
Google Cloud Search スキーマは、データのインデックス登録やクエリに使用するオブジェクト、プロパティ、オプションを定義する JSON 構造です。コンテンツ コネクタにより、リポジトリからデータが読み取られ、登録されたスキーマに基づいてデータの構造化とインデックス登録が行われます。
スキーマを作成するには、JSON スキーマ オブジェクトを API に提供してから登録します。データをインデックスに登録するには、事前に各リポジトリにスキーマ オブジェクトを登録する必要があります。
このドキュメントでは、スキーマ作成の基礎について説明します。検索エクスペリエンスを向上させるためにスキーマを調整する方法については、検索品質の向上をご覧ください。
スキーマを作成する
Cloud Search スキーマを作成するには、次の手順に従います。
- 予想されるユーザーの行動を特定する
- データソースを初期化する
- スキーマの作成
- サンプル スキーマを完成させる
- スキーマを登録する
- データをインデックスに登録する
- スキーマをテストする
- スキーマをチューニングする
予想されるユーザーの行動を特定する
ユーザーが実行するクエリの種類を予測することは、スキーマの作成戦略につながります。
たとえば、ユーザーが映画のデータベースに対してクエリを発行する場合、「Robert Redford が主演するすべての映画を表示する」などのクエリが予測されます。したがって、スキーマでは、「特定の俳優が出演するすべての映画」に基づくクエリ結果をサポートする必要があります。
ユーザーの行動パターンを反映するようにスキーマを定義するには、次のタスクを実行することを検討してください。
- さまざまなユーザーから要求される多様なクエリを評価します。
- クエリで使用される可能性があるオブジェクトを特定します。オブジェクトとは、映画データベース内の映画のような、関連データの論理的集合です。
- オブジェクトの構成要素でクエリに使用される可能性があるプロパティと値を特定します。プロパティとは、オブジェクトのインデックス登録可能な属性であり、プリミティブ値または他のオブジェクトで構成されます。たとえば、映画オブジェクトには、映画のタイトルや公開日などのプロパティをプリミティブ値として含めることができます。また、出演者のように、名前や役柄などの固有のプロパティを持つ他のオブジェクトを含めることもできます。
- プロパティの有効な値のサンプルを見つけます。値とは、プロパティに対してインデックス登録される実際のデータのことです。たとえば、データベースには「レイダース / 失われたアーク《聖櫃》」というタイトルの映画が含まれているかもしれません。
- ユーザーが希望する並べ替えとランキングのオプションを決定します。たとえば、映画のクエリでは、タイトルでアルファベット順に並べ替えるよりも、年代順に並べ替えて視聴者の評価でランク付けするほうがよい場合があります。
- (省略可)検索が実行されるコンテキスト(ユーザーの役職や部門など)をより具体的に表すプロパティがないか検討し、コンテキストに基づいて自動入力候補を提供できるようにします。たとえば、映画のデータベースを検索しているユーザーは、特定のジャンルの映画にしか興味がない可能性があります。ユーザーは、検索結果に表示するジャンルを、ユーザー プロフィールの一部として定義できます。その後、ユーザーが映画のクエリを入力し始めると、ユーザーが好むジャンルの映画(「アクション映画」など)のみが、予測入力の候補として表示されます。
- 検索に使用される可能性があるオブジェクト、プロパティ、サンプル値のリストを作成します(このリストの使用方法の詳細については、演算子オプションを定義するをご覧ください)。
データソースを初期化する
データソースとは、Google Cloud にインデックス登録されて格納されているリポジトリのデータを表します。データソースを初期化する手順については、サードパーティのデータソースを管理するをご覧ください。
ユーザーの検索結果はデータソースから返されます。ユーザーが検索結果をクリックすると、インデックス登録リクエストで指定された URL を使用して実際のアイテムに誘導されます。
オブジェクトを定義する
スキーマ内のデータの基本単位はオブジェクトです。これはデータの論理構造で、「スキーマ オブジェクト」とも呼ばれます。映画データベースでは、データの論理構造の 1 つに「映画」があります。別のオブジェクトとして、映画に関わっている出演者やスタッフを表す「人物」があります。
スキーマ内の個々のオブジェクトに、映画のタイトルや上映時間、人物の名前や生年月日など、そのオブジェクトを構成する一連のプロパティ(属性)があります。オブジェクトのプロパティには、プリミティブ値や他のオブジェクトを含めることができます。
図 1 は、映画オブジェクトと人物オブジェクトおよびそれぞれに関連するプロパティを示しています。
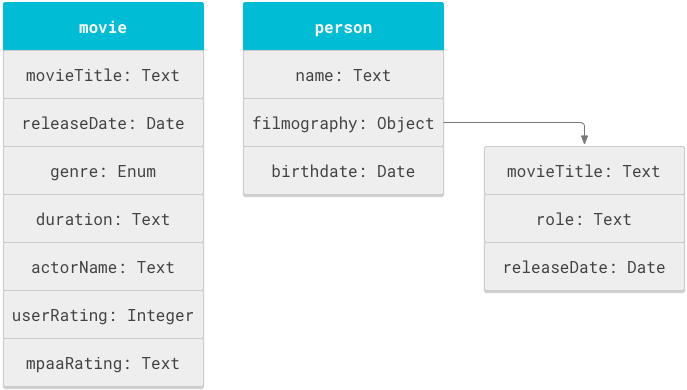
Cloud Search スキーマは、実質的には objectDefinitions タグ内で定義されたオブジェクト定義ステートメントのリストです。次のスキーマ スニペットは、映画スキーマ オブジェクトと人物スキーマ オブジェクトの objectDefinitions ステートメントを示しています。
{
"objectDefinitions": [
{
"name": "movie",
...
},
{
"name": "person",
...
}
]
}
スキーマ オブジェクトを定義する際には、そのオブジェクトの name を指定します。この名前は、スキーマ内の他のすべてのオブジェクト間で一意でなければなりません。通常、映画オブジェクトの場合は movie など、該当するオブジェクトを表す name 値を使用します。スキーマ サービスでは、インデックス登録可能なオブジェクトのキー識別子として name フィールドが使用されます。name フィールドの詳細については、オブジェクト定義をご覧ください。
オブジェクトのプロパティを定義する
ObjectDefinition のリファレンスに記載されているように、オブジェクト名の後に options のセットと propertyDefinitions のリストが続きます。options は、さらに freshnessOptions と displayOptions で構成できます。freshnessOptions は、アイテムの鮮度に基づいて検索ランキングを調整するために使用します。displayOptions は、特定のラベルとプロパティをオブジェクトの検索結果に表示するかどうかを定義するために使用します。
propertyDefinitions セクションでは、オブジェクトのプロパティ(映画のタイトルや公開日など)を定義します。
次のスニペットは、movieTitle と releaseDate の 2 つのプロパティを持つ movie オブジェクトを示しています。
{
"objectDefinitions": [
{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
},
"displayOptions": {
"displayLabel": "Release date"
}
...
]
}
]
}
PropertyDefinition は、次の項目で構成されます。
name文字列。- 型に依存しないオプションのリスト。たとえば、前のスニペットの
isReturnableが該当します。 - 型とそれに関連する型固有のオプション。たとえば、前のスニペットの
textPropertyOptionsとretrievalImportanceが該当します。 - プロパティを検索演算子として使用する方法を表す
operatorOptions。 - 1 つ以上の
displayOptions。たとえば、前のスニペットのdisplayLabelが該当します。
プロパティの name はそれを含むオブジェクト内では一意である必要がありますが、他のオブジェクトやサブオブジェクトでは同じ名前を使用できます。図 1 では、映画のタイトルと公開日が 2 回定義されています。1 つ目は movie オブジェクトで定義されており、2 つ目は person オブジェクトの filmography サブオブジェクトで定義されています。このスキーマでは、次の 2 種類の検索動作をサポートするために movieTitle 項目を再利用しています。
- ユーザーが映画のタイトルを検索した場合、映画の結果を表示します。
- ユーザーが映画のタイトルで特定の出演俳優を検索した場合、人物の結果を表示します。
同様に、2 つの movieTitle フィールドの意味が同じであるため、releaseDate フィールドを再利用しています。
独自のスキーマを開発する際には、スキーマで複数回宣言するデータを含む関連項目がリポジトリ内でどのように定義されているかを考慮してください。
型に依存しないオプションを追加する
PropertyDefinition には、データ型に関係なく、すべてのプロパティに共通する一般的な検索機能オプションをリストします。
isReturnable- プロパティによって識別されたデータを Query API による検索結果として返す必要があるかどうかを指定します。映画のプロパティの例はすべて返品可能です。逆に、ユーザーに返さないプロパティは、結果を検索したり、ランク付けしたりするために使用できます。isRepeatable- プロパティに複数の値を許可するかどうかを指定します。たとえば、映画の公開日は 1 つしかありませんが、俳優は複数人いることが考えられます。isSortable- プロパティを並べ替えに使用できるようにするかどうかを指定します。繰り返し可能なプロパティに対しては true に設定することはできません。たとえば、映画の結果は、公開日または視聴率によって並べ替えることができます。isFacetable- プロパティをファセットの生成に使用できるようにするかどうかを指定します。ファセットは、検索結果を絞り込むために使用できます。ユーザーは、最初の結果を確認してから、条件つまりファセットを追加して結果をさらに絞り込むことができます。オブジェクト型のプロパティに対してはこのオプションを true に設定することはできません。また、このオプションを設定するには、isReturnableを true に設定する必要があります。最後に、このオプションは、列挙型、ブール型、テキスト型のプロパティに対してのみサポートされています。たとえば、サンプル スキーマでは、genre、actorName、userRating、mpaaRatingをファセットとして使用できるようにして、検索結果をインタラクティブに絞り込めるようにできます。isWildcardSearchableは、ユーザーがこのプロパティに対してワイルドカード検索を実行できることを示します。このオプションはテキスト プロパティでのみ使用できます。テキスト フィールドでのワイルドカード検索の仕組みは、exactMatchWithOperator フィールドに設定された値によって異なります。exactMatchWithOperatorがtrueに設定されている場合、テキスト値は 1 つのアトミック値としてトークン化され、ワイルドカード検索が実行されます。たとえば、テキスト値がscience-fictionの場合、ワイルドカード クエリscience-*はそれに一致します。exactMatchWithOperatorがfalseに設定されている場合、テキスト値はトークン化され、各トークンに対してワイルドカード検索が実行されます。たとえば、テキスト値が「science-fiction」の場合、ワイルドカード クエリsci*またはfi*はアイテムと一致しますが、science-*は一致しません。
これらの一般的な検索機能パラメータはすべてブール値です。これらのデフォルト値はすべて false になっているため、使用するには true に設定する必要があります。
次の表に、movie オブジェクトのすべてのプロパティに対して true に設定されているブール値パラメータを示します。
| プロパティ | isReturnable |
isRepeatable |
isSortable |
isFacetable |
isWildcardSearchable |
|---|---|---|---|---|---|
movieTitle |
true | true | |||
releaseDate |
true | true | |||
genre |
true | true | true | ||
duration |
true | ||||
actorName |
true | true | true | true | |
userRating |
true | true | |||
mpaaRating |
true | true |
映画は複数のジャンルに属する可能性があり、通常は複数の俳優が出演しているため、genre と actorName に対してはいずれも isRepeatable が true に設定されています。プロパティが繰り返し可能であるか、繰り返し可能なサブオブジェクトに含まれている場合は、そのプロパティを並べ替えることはできません。
型を定義する
PropertyDefinition リファレンス セクションには、いくつかの xxPropertyOptions をリストします。ここで、xx は boolean などの特定の型です。プロパティのデータ型を設定するには、適切なデータ型オブジェクトを定義する必要があります。プロパティのデータ型オブジェクトを定義すると、そのプロパティのデータ型が設定されます。たとえば、movieTitle プロパティに textPropertyOptions を定義すると、映画のタイトルがテキスト型になります。次のスニペットは、textPropertyOptions によってデータ型が設定された movieTitle プロパティを示しています。
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
...
},
...
},
1 つのプロパティには、1 つのデータ型のみを関連付けることができます。たとえば、映画スキーマでは、releaseDate には日付(2016-01-13)または文字列(例: January 13, 2016)のいずれかを指定でき、両方は指定できません。
サンプル映画スキーマでは、次のデータ型オブジェクトを使用して各種プロパティのデータ型が指定されています。
| プロパティ | データ型オブジェクト |
|---|---|
movieTitle |
textPropertyOptions |
releaseDate |
datePropertyOptions |
genre |
enumPropertyOptions |
duration |
textPropertyOptions |
actorName |
textPropertyOptions |
userRating |
integerPropertyOptions |
mpaaRating |
textPropertyOptions |
プロパティに対して選択するデータ型は、想定されるユースケースによって異なります。この映画スキーマで想定されるシナリオでは、結果を年代順に並べ替えるのが望ましいと考えられるため、releaseDate は日付オブジェクトです。年をまたいで 12 月の公開と 1 月の公開を比較するユースケースが想定される場合などには、文字列形式が役立つこともあります。
型固有のオプションを構成する
PropertyDefinition リファレンス セクションは、各型のオプションにリンクしています。型固有のオプションのほとんどは、enumPropertyOptions の possibleValues のリストを除き、オプションです。さらに、orderedRanking オプションを使用すると、値を相互に比較してランク付けできます。次のスニペットでは、textPropertyOptions によってデータ型が設定され、retrievalImportance 型固有のオプションが指定されている movieTitle プロパティを示しています。
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
...
},
...
}
それ以外に、サンプル スキーマで使用されている型固有のオプションは次のとおりです。
| プロパティ | 型 | 型固有のオプション |
|---|---|---|
movieTitle |
textPropertyOptions |
retrievalImportance |
releaseDate |
datePropertyOptions |
|
genre |
enumPropertyOptions |
|
duration |
textPropertyOptions |
|
actorName |
textPropertyOptions |
|
userRating |
integerPropertyOptions |
orderedRanking、maximumValue |
mpaaRating |
textPropertyOptions |
演算子オプションを定義する
型固有のオプションに加えて、各型にはオプションで一連の operatorOptions を指定します。これらのオプションでは、プロパティを検索演算子として使用する方法を指定します。次のスニペットでは、movieTitle プロパティのデータ型が textPropertyOptions によって設定され、型固有のオプションとして retrievalImportance と operatorOptions が指定されています。
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
...
}
すべての operatorOptions には operatorName があります(movieTitle の title など)。演算子名はプロパティの検索演算子です。検索演算子は、ユーザーが検索の絞り込みに使用すると予想される実際のパラメータです。たとえば、タイトルに基づいて映画を検索する場合、ユーザーは「title:movieName」と入力します。ここで、movieName は映画の名前です。
演算子名をプロパティ名と同じにすることはできません。代わりに、演算子名には、組織内のユーザーが使用する最も一般的な単語を反映する必要があります。たとえば、ユーザーが映画のタイトルを表す用語として「title」ではなく「name」の使用を好む場合は、演算子名を「name」に設定する必要があります。
すべてのプロパティが同じ型に解決される場合に限り、複数のプロパティに対して同じ演算子名を使用できます。クエリの実行時に共有演算子名を使用した場合、その演算子名を使用するすべてのプロパティが取得されます。たとえば、映画オブジェクトに plotSummary プロパティと plotSynopsis プロパティがあり、それらの各プロパティの operatorName が plot になっているとします。これらのプロパティの両方がテキスト(textPropertyOptions)であれば、1 つのクエリで plot 検索演算子を使用することによって、これらの両方を取得できます。
並べ替え可能なプロパティについては、operatorName に加えて、operatorOptions に lessThanOperatorName フィールドと greaterThanOperatorName フィールドを指定できます。ユーザーは、これらのオプションを使用することで、提示された値との比較に基づくクエリを作成できます。
最後に、textOperatorOptions の operatorOptions に exactMatchWithOperator フィールドがあります。exactMatchWithOperator を true に設定した場合、クエリ文字列はプロパティ値全体と一致する必要があり、テキスト内に単に含まれているだけでは不十分です。テキスト値は、演算子検索およびファセット照合で 1 つのアトミック値として扱われます。
たとえば、ジャンルのプロパティを使用して、書籍オブジェクトまたは映画オブジェクトをインデックスに登録する場合について考えます。考えられるジャンルは、「Science-Fiction」、「Science」、「Fiction」です。exactMatchWithOperator が false に設定されているか省略されている場合、ジャンルを検索するか、「Science」または「Fiction」のファセットを選択すると、「Science-Fiction」の結果も返されます。これは、テキストがトークン化され、「Science-Fiction」に「Science」と「Fiction」のトークンが存在するためです。exactMatchWithOperator が true の場合、テキストは単一のトークンとして扱われるため、「Science」も「Fiction」も「Science-Fiction」と一致しません。
(省略可)displayOptions セクションを追加する
任意の propertyDefinition セクションの末尾にオプションで displayOptions セクションを追加できます。このセクションには、1 つの displayLabel 文字列を指定します。displayLabel には、プロパティを表すわかりやすいテキストラベルを指定することをおすすめします。ObjectDisplayOptions を使用してプロパティを表示するように構成している場合は、このラベルがプロパティの前に表示されます。プロパティを表示するように構成していても、displayLabel を定義しなかった場合は、プロパティ値のみが表示されます。
次のスニペットは、displayLabel が「Title」に設定された movieTitle プロパティを示しています。
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
サンプル スキーマの movie オブジェクトのすべてのプロパティの displayLabel 値は次のとおりです。
| プロパティ | displayLabel |
|---|---|
movieTitle |
Title |
releaseDate |
Release date |
genre |
Genre |
duration |
Run length |
actorName |
Actor |
userRating |
Audience score |
mpaaRating |
MPAA rating |
(省略可)suggestionFilteringOperators[] セクションを追加します。
propertyDefinition セクションの末尾に、オプションで suggestionFilteringOperators[] セクションを追加できます。このセクションでは、自動入力候補のフィルタに使用するプロパティを定義します。たとえば、ユーザーが好む映画のジャンルに基づいて候補をフィルタするために、genre の演算子を定義できます。ユーザーが検索クエリを入力すると、ユーザーが好むジャンルに一致する映画のみが、予測入力の候補として表示されます。
スキーマを登録する
Cloud Search クエリから構造化データが返されるようにするには、Cloud Search スキーマ サービスにスキーマを登録する必要があります。スキーマを登録する際には、データソースを初期化するステップで取得したデータソース ID が必要になります。
データソース ID を使用して、UpdateSchema リクエストを発行してスキーマを登録します。
UpdateSchema リファレンス ページの詳細な説明に従って、次の HTTP リクエストを発行してスキーマを登録します。
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
リクエストの本文には、次の内容が含まれている必要があります。
{
"validateOnly": // true or false,
"schema": {
// ... Your complete schema object ...
}
}
validateOnly オプションを使用すると、実際にスキーマを登録することなくスキーマの有効性をテストできます。
データをインデックスに登録する
スキーマの登録後、インデックス呼び出しを使用してデータソースにインデックスを挿入します。インデックス登録は、通常、コンテンツ コネクタで行われます。
映画スキーマでは、1 つの映画に対する REST API インデックス登録リクエストは次のようになります。
{
"name": "datasource/<data_source_id>/items/titanic",
"acl": {
"readers": [
{
"gsuitePrincipal": {
"gsuiteDomain": true
}
}
]
},
"metadata": {
"title": "Titanic",
"sourceRepositoryUrl": "http://www.imdb.com/title/tt2234155/?ref_=nv_sr_1",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [
{
"name": "movieTitle",
"textValues": {
"values": [
"Titanic"
]
}
},
{
"name": "releaseDate",
"dateValues": {
"values": [
{
"year": 1997,
"month": 12,
"day": 19
}
]
}
},
{
"name": "actorName",
"textValues": {
"values": [
"Leonardo DiCaprio",
"Kate Winslet",
"Billy Zane"
]
}
},
{
"name": "genre",
"enumValues": {
"values": [
"Drama",
"Action"
]
}
},
{
"name": "userRating",
"integerValues": {
"values": [
8
]
}
},
{
"name": "mpaaRating",
"textValues": {
"values": [
"PG-13"
]
}
},
{
"name": "duration",
"textValues": {
"values": [
"3 h 14 min"
]
}
}
]
}
},
"content": {
"inlineContent": "A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.",
"contentFormat": "TEXT"
},
"version": "01",
"itemType": "CONTENT_ITEM"
}
objectType フィールドの movie の値が、スキーマ内のオブジェクト定義名とどのように対応付けられているかに注目してください。Cloud Search では、これらの 2 つの値の対応付けに基づいて、インデックス登録時に使用するスキーマ オブジェクトが認識されます。
また、スキーマ プロパティ releaseDate のインデックス登録において、このプロパティが継承するサブプロパティ year、month、day がどのように使用されているかに注目してください。これらのサブプロパティを継承するのは、このプロパティが datePropertyOptions によって date データ型として定義されているためです。ただし、year、month、day はスキーマに定義されていないため、これらのプロパティの 1 つ(たとえば、year)を個別に設定します。
また、繰り返し可能なプロパティ actorName が値リストを使用してどのようにインデックスに登録されるかにも注目してください。
インデックス登録における潜在的な問題を特定する
スキーマとインデックス登録に関する最も一般的な問題として、次の 2 つがあります。
スキーマ サービスに登録されていないスキーマ オブジェクト名またはプロパティ名がインデックス登録リクエストに含まれている。この問題が原因で、プロパティまたはオブジェクトが無視されます。
スキーマに登録されている型と異なる型を持つプロパティがインデックス登録リクエストに含まれている。この問題が原因で、インデックス登録時にエラーが返されます。
複数のクエリ形式を使用してスキーマをテストする
大規模な本番環境データ リポジトリ用にスキーマを登録する際には、より小さなテストデータ リポジトリでテストすることを検討してください。小さいテスト リポジトリでテストすることで、より大きなインデックスや既存の本番環境インデックスに影響を与えることなく、スキーマをすばやく調整したり、インデックス登録済みデータを削除できます。テスト用データ リポジトリでは、テストユーザーのみを承認する ACL を作成し、他のユーザーに対してはこのデータが検索結果に表示されないようにできます。
検索クエリを検証するための検索インターフェースを作成する方法については、検索インターフェースをご覧ください。
このセクションでは、映画スキーマをテストするために使用できるいくつかの異なるクエリを例として紹介しています。
一般的なクエリを使用してテストする
一般的なクエリとは、データソース内のアイテムのうち特定の文字列を含むすべてのアイテムを返すものです。たとえば、検索インターフェースで「titanic」という単語を入力して Return キーを押すことによって、映画データソースに対して一般的なクエリを実行できます。「titanic」という単語を含むすべての映画が検索結果として返されるはずです。
演算子を使用してテストする
クエリに演算子を追加すると、その演算子の値に一致するアイテムに結果が制限されます。たとえば、actor 演算子を使用して、特定の俳優が主演するすべての映画を検索できます。検索インターフェースを使用してこの演算子クエリを実行するには、「actor:Zane」などの operator=value ペアを入力して Return キーを押すだけです。俳優 Zane が主演するすべての映画が検索結果として返されるはずです。
スキーマを調整する
スキーマとデータの使用が開始された後も、ユーザーに対してうまく機能する部分とそうでない部分を引き続き監視します。次のような状況では、スキーマを調整することを検討してください。
- 以前にインデックスに登録しなかった項目をインデックスに登録します。たとえば、監督名で映画を検索するユーザーが多い場合は、演算子として監督名をサポートするようにスキーマを調整します。
- ユーザーのフィードバックに基づいて検索演算子名を変更します。演算子名はユーザーにとってわかりやすいものでなければなりません。ユーザーが間違った演算子名を覚えたまま直らない場合は、その名前を変更することを検討します。
スキーマ変更後の再インデックス登録
スキーマ内の次の値を変更しても、データの再インデックス登録が必要になることはありません。新しい UpdateSchema リクエストを送信するだけで、インデックスは引き続き機能します。
- 演算子名。
- 整数の最小値と最大値。
- 整数型と列挙型の順位付け。
- 更新頻度オプション。
- 表示オプション。
次の変更を行った場合でも、インデックス登録済みデータは引き続き元の登録済みスキーマに従って動作します。ただし、このような変更を更新後のスキーマに基づいて表示するには、既存のエントリの再インデックス登録が必要になります。
- 新しいプロパティまたはオブジェクトを追加または削除する。
isReturnable、isFacetable、isSortableをfalseからtrueに変更。
isFacetable または isSortable を true に設定するのは、明確なユースケースとニーズがある場合に限ります。
最後に、プロパティに isSuggestable をマークしてスキーマを更新する場合は、データのインデックスを再作成する必要があります。これにより、そのプロパティの自動入力の使用が遅延します。
禁止されているプロパティ変更
スキーマに対する一部の変更は、データの再インデックス登録を行うかどうかに関係なく禁止されています。変更すると、インデックスが破損したり、検索結果の精度や一貫性が失われたりします。該当する変更は次のとおりです。
- プロパティのデータ型。
- プロパティ名。
exactMatchWithOperatorの設定。retrievalImportanceの設定。
ただし、この制限を回避する方法はあります。
複雑なスキーマ変更を行う
検索結果の精度低下や検索インデックスの破損を引き起こす変更を回避するために、Cloud Search では、リポジトリのインデックス登録後に UpdateSchema リクエストによって特定の種類の変更を行うことが禁止されています。たとえば、プロパティのデータ型または名前は、一度設定したら以後変更できなくなります。これらの変更は、データの再インデックス登録を行ったとしても、単純な UpdateSchema リクエストでは実現できません。
スキーマに対して禁止されている変更をどうしても加える変更がある場合は、通常、許可されている一連の変更を通じて同じ結果を実現できます。そのためには、一般に、最初にインデックス登録済みのプロパティを古いオブジェクト定義から新しいオブジェクト定義に移行してから、新しいプロパティのみを使用するインデックス登録リクエストを送信します。
次の手順では、プロパティのデータ型または名前を変更する方法を示します。
- スキーマのオブジェクト定義に新しいプロパティを追加します。変更対象のプロパティとは異なる名前を使用します。
- 新しい定義で UpdateSchema リクエストを発行します。リクエストでは、新しいプロパティと古いプロパティの両方を含むスキーマ全体を送信してください。
データ リポジトリからインデックスをバックフィルします。インデックスをバックフィルするには、古いプロパティは使用せず、新しいプロパティのみを使用してすべてのインデックス登録リクエストを送信します。そうしないと、クエリに対する一致件数が 2 倍になるためです。
- インデックスのバックフィル時には、新しいプロパティをチェックし、古いプロパティをデフォルトに設定することで、動作の一貫性が失われないようにします。
- バックフィルが完了したら、テストクエリを実行して検証します。
古いプロパティを削除します。古いプロパティ名を含まない別の UpdateSchema リクエストを発行し、今後のインデックス登録リクエストでは古いプロパティ名の使用を中止します。
古いプロパティの代わりに新しいプロパティを使用するように移行します。たとえば、プロパティ名を creator から author に変更する場合は、これまで creator を参照していた部分で author を使用するようにクエリコードを更新する必要があります。
Cloud Search では、予期しないインデックス登録結果を招くような再利用を防止するために、削除したプロパティまたはオブジェクトのレコードは 30 日間だけ保持されます。この 30 日以内に、将来のインデックス登録リクエストでの使用を含め、削除したオブジェクトまたはプロパティの使用から完全に移行する必要があります。これにより、後でそのプロパティまたはオブジェクトを再び使用することに決めた場合でも、インデックスの正確性を維持する形で対応できます。
サイズ制限を把握する
Cloud Search では、構造化データ オブジェクトとスキーマのサイズに制限があります。これらの上限は次のとおりです。
- 最上位のオブジェクトの最大数は 10 個です。
- 構造化データ階層の最大深度は 10 レベルです。
- オブジェクト内の項目の合計数は 1,000 個に制限されています。これは、プリミティブ項目の数に、ネストされた各オブジェクト内の項目数の合計を加えたものです。
次のステップ
必要に応じて次の手順を行います。
スキーマをテストする検索インターフェースを作成します。
検索品質の向上のためにスキーマを調整します。
_dictionaryEntryスキーマを活用して、自社でよく使用される用語の類義語を定義する方法を学びます。_dictionaryEntryスキーマを使用するには、類義語を定義するをご覧ください。コネクタを作成します。