
Un schéma Google Cloud Search est une structure JSON qui définit les objets, les propriétés et les options à utiliser pour l'indexation et l'interrogation de vos données. Le connecteur de contenu lit les données de votre dépôt et, en fonction du schéma enregistré, les structure et les indexe.
Pour créer un schéma, fournissez un objet de schéma JSON à l'API, puis enregistrez-le. Afin de pouvoir indexer vos données, vous devez enregistrer un objet de schéma pour chacun de vos dépôts.
Ce document présente les principes de base de la création de schémas. Pour savoir comment ajuster votre schéma afin d'améliorer l'expérience de recherche, consultez Améliorer la qualité de la recherche.
Créer un schéma
Les étapes à suivre pour créer le schéma Cloud Search sont répertoriées ci-dessous:
- Identifier le comportement attendu des utilisateurs
- Initialiser une source de données
- Créer un schéma
- Exemple de schéma complet
- Enregistrer votre schéma
- Indexer vos données
- Tester votre schéma
- Ajuster votre schéma
Identifier le comportement attendu des utilisateurs
Anticiper les types de requêtes de vos utilisateurs vous permet de définir une stratégie pour la création du schéma.
Par exemple, lors de l'émission de requêtes sur une base de données de films, vous pouvez anticiper une requête telle que "Afficher tous les films avec Robert Redford" de la part des utilisateurs. Votre schéma doit donc être compatible avec les résultats des requêtes basées sur "tous les films avec un acteur particulier".
Pour définir votre schéma afin qu'il reflète les modèles de comportement de vos utilisateurs, envisagez les tâches suivantes:
- Évaluer un ensemble de diverses requêtes souhaitées émanant de différents utilisateurs.
- Identifiez les objets pouvant être utilisés dans les requêtes. Les objets sont des ensembles logiques de données associées, comme un film dans une base de données de films.
- Identifiez les propriétés et les valeurs qui composent l'objet et qui peuvent être utilisées dans les requêtes. Les propriétés sont les attributs indexables de l'objet : elles peuvent inclure des valeurs primitives ou d'autres objets. Par exemple, un objet de film peut avoir des propriétés telles que le titre et la date de sortie du film sous forme de valeurs primitives. L'objet "movie" peut également contenir d'autres objets, tels que les membres de la distribution, qui sont associés à leurs propres propriétés, comme leur nom ou leur rôle.
- Identifier des exemples de valeurs valides pour les propriétés Les valeurs correspondent aux données réelles indexées pour une propriété. Par exemple, le titre d'un film dans votre base de données peut être "Les Aventuriers de l'arche perdue".
- Déterminez les options de tri et de classement souhaitées par vos utilisateurs. Par exemple, lorsqu'ils lancent des requêtes sur des films, les utilisateurs peuvent vouloir trier les résultats de manière chronologique et les classer par nombre d'entrées, plutôt que par ordre alphabétique des titres.
- (Facultatif) Demandez-vous si l'une de vos propriétés représente un contexte plus spécifique dans lequel des recherches peuvent être effectuées, comme le poste ou le service des utilisateurs, afin que des suggestions de saisie semi-automatique puissent être fournies en fonction du contexte. Par exemple, les utilisateurs qui recherchent dans une base de données de films ne sont peut-être intéressés que par un certain genre de films. Les utilisateurs définissent le genre de résultats qu'ils souhaitent obtenir pour leurs recherches, éventuellement dans leur profil utilisateur. Ensuite, lorsqu'un utilisateur commence à saisir une requête de films, seuls les films de son genre préféré, tels que "films d'action", sont suggérés dans les suggestions de saisie semi-automatique.
- Établir la liste de ces objets, propriétés et exemples de valeurs pouvant être utilisés dans les recherches. (Pour plus d'informations sur l'utilisation de cette liste, consultez la section Définir les options d'opérateur.)
Initialiser votre source de données
Une source de données représente les données d'un dépôt qui ont été indexées et stockées dans Google Cloud. Pour obtenir des instructions sur l'initialisation d'une source de données, consultez l'article Gérer les sources de données tierces.
Les résultats de recherche d'un utilisateur sont renvoyés à partir de la source de données. Lorsqu'un utilisateur clique sur un résultat de recherche, Cloud Search le dirige vers l'élément correspondant à l'aide de l'URL fournie dans la requête d'indexation.
Définir vos objets
L'unité de données fondamentale dans un schéma est l'objet, également appelé objet de schéma, qui est une structure logique de données. Dans une base de données de films, l'une des structures logiques de données est "film". L'objet "personne" peut également être défini pour représenter les acteurs et l'équipe du film.
Chaque objet d'un schéma possède une série de propriétés, ou attributs, décrivant l'objet, tels que le titre et la durée d'un film, ou le nom et la date de naissance d'une personne. Les propriétés d'un objet peuvent inclure des valeurs primitives ou d'autres objets.
La figure 1 illustre les objets "movie" (film) et "person" (personne), ainsi que les propriétés associées.
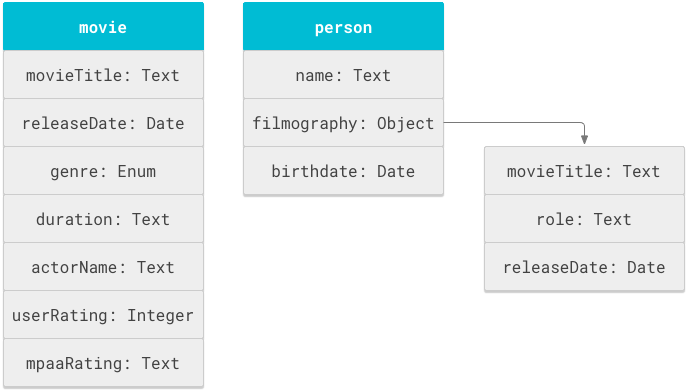
Un schéma Cloud Search est essentiellement une liste d'instructions de définition d'objet définies dans la balise objectDefinitions. L'extrait de schéma suivant montre les instructions objectDefinitions pour les objets de schéma "movie" et "person".
{
"objectDefinitions": [
{
"name": "movie",
...
},
{
"name": "person",
...
}
]
}
Lorsque vous définissez un objet de schéma, vous spécifiez un name pour l'objet qui doit être unique parmi tous les objets de ce schéma. En règle générale, vous utiliserez une valeur name décrivant l'objet, telle que movie pour un objet correspondant à un film. Le service de schéma utilise le champ name comme identifiant de clé pour les objets indexables. Pour en savoir plus sur le champ name, consultez la section Définition des objets.
Définir les propriétés des objets
Comme indiqué dans la documentation de ObjectDefinition, le nom de l'objet est suivi d'un ensemble de options et d'une liste de propertyDefinitions.
options peut également se composer de freshnessOptions et de displayOptions.
Les freshnessOptions permettent d'ajuster le classement des recherches en fonction de l'actualisation d'un élément. Les displayOptions vous permettent de définir si des étiquettes et des propriétés spécifiques sont affichées dans les résultats de recherche associés à un objet.
Dans la section propertyDefinitions, vous pouvez définir les propriétés d'un objet, telles que le titre et la date de sortie du film.
L'extrait de code suivant montre l'objet movie avec deux propriétés: movieTitle et releaseDate.
{
"objectDefinitions": [
{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
},
"displayOptions": {
"displayLabel": "Release date"
}
...
]
}
]
}
La section PropertyDefinition comprend les éléments suivants:
- une chaîne
name. - Une liste d'options non spécifiques au type, telles que
isReturnabledans l'extrait précédent. - Un type et ses options spécifiques au type associées, telles que
textPropertyOptionsetretrievalImportancedans l'extrait précédent. - Un
operatorOptionsdécrivant comment la propriété est utilisée en tant qu'opérateur de recherche. - Un ou plusieurs
displayOptions, tels quedisplayLabeldans l'extrait précédent.
Le name d'une propriété doit être unique dans l'objet qui la contient, mais le même nom peut être utilisé dans d'autres objets et sous-objets.
Dans la figure 1, le titre et la date de sortie du film ont été définis deux fois : une fois dans l'objet movie et une autre fois dans le sous-objet filmography de l'objet person. Ce schéma réutilise le champ movieTitle pour être compatible avec deux types de comportements de recherche:
- Afficher les résultats de films lorsque les utilisateurs recherchent le titre d'un film.
- Afficher les résultats de personnes lorsque les utilisateurs recherchent le titre d'un film dans lequel a joué un acteur.
De même, ce schéma réutilise le champ releaseDate, car il a la même signification pour les deux champs movieTitle.
Lorsque vous développez votre propre schéma, déterminez si votre dépôt peut comporter des champs associés contenant des données que vous souhaiterez déclarer plusieurs fois dans votre schéma.
Ajouter des options indépendantes du type
La section PropertyDefinition répertorie les options de fonctionnalité de recherche générale communes à toutes les propriétés, quel que soit le type de données.
isReturnable: indique si la propriété identifie les données à renvoyer dans les résultats de recherche via l'API Query. Toutes les propriétés d'exemple de films peuvent être retournées. Les propriétés non renvoyables peuvent être utilisées pour la recherche ou le classement des résultats (sans renvoi à l'utilisateur).isRepeatable: indique si plusieurs valeurs sont autorisées pour la propriété. Par exemple, un film a une seule date de sortie, mais peut avoir plusieurs acteurs.isSortable: indique que la propriété peut être utilisée pour le tri. Cette option ne peut pas être associée à la valeur "true" pour les propriétés qui sont reproductibles. Par exemple, les résultats de films peuvent être triés par date de sortie ou par nombre d'entrées.isFacetable: indique que la propriété peut être utilisée pour générer des attributs. Un attribut permet d'affiner les résultats de la recherche. L'utilisateur voit les résultats initiaux, puis ajoute des critères, ou attributs, pour les affiner. Cette option ne peut pas avoir la valeur "true" pour les propriétés dont le type est "object", et ne peut être définie que siisReturnablea la valeur "true". Enfin, cette option est disponible uniquement pour les propriétés "Enum", "Boolean" et "Text". Par exemple, dans notre exemple de schéma, nous pouvons autoriser l'ajout d'attributs àgenre,actorName,userRatingetmpaaRatingpour permettre d'affiner de manière interactive des résultats de recherche.isWildcardSearchableindique que les utilisateurs peuvent effectuer une recherche avec des caractères génériques pour cette propriété. Cette option n'est disponible que pour les propriétés de texte. Le fonctionnement de la recherche avec caractères génériques dans le champ de texte dépend de la valeur définie dans le champ exactMatchWithOperator. SiexactMatchWithOperatorest défini surtrue, la valeur de texte est tokenisée en tant que valeur atomique, et une recherche avec caractère générique est effectuée à son encontre. Par exemple, si la valeur textuelle estscience-fiction, une requête avec caractère génériquescience-*lui correspond. SiexactMatchWithOperatorest défini surfalse, la valeur textuelle est tokenisée et une recherche avec caractères génériques est effectuée sur chaque jeton. Par exemple, si la valeur textuelle est "science-fiction", les requêtes avec caractères génériquessci*oufi*correspondent à l'élément, maisscience-*ne le fait pas.
Ces paramètres de fonctionnalité de recherche générale sont tous des valeurs booléennes ; ils ont tous la valeur par défaut false et doivent être définis sur true pour pouvoir être utilisés.
Le tableau suivant contient les paramètres booléens qui sont définis sur true pour toutes les propriétés de l'objet movie:
| Propriété | isReturnable |
isRepeatable |
isSortable |
isFacetable |
isWildcardSearchable |
|---|---|---|---|---|---|
movieTitle |
true | true | |||
releaseDate |
true | true | |||
genre |
true | true | true | ||
duration |
true | ||||
actorName |
true | true | true | true | |
userRating |
true | true | |||
mpaaRating |
true | true |
Pour les deux propriétés genre et actorName, l'option isRepeatable est définie sur true, car un film peut appartenir à plusieurs genres et comprend généralement plusieurs acteurs. Une propriété ne peut pas être triée si elle est reproductible ou contenue dans un sous-objet reproductible.
Définir le type
La section de référence PropertyDefinition répertorie plusieurs xxPropertyOptions où xx est un type spécifique, tel que boolean. Pour définir le type de données de la propriété, vous devez définir l'objet de type de données approprié. La définition d'un objet de type de données pour une propriété établit le type de données de cette propriété. Par exemple, la définition de textPropertyOptions pour la propriété movieTitle indique que le titre du film est de type texte. L'extrait suivant montre la propriété movieTitle avec textPropertyOptions définissant le type de données.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
...
},
...
},
Un seul type de données peut être associé à une propriété. Par exemple, dans notre schéma de film, releaseDate ne peut être qu'une date (par exemple, 2016-01-13) ou une chaîne (par exemple, January 13, 2016), mais pas les deux.
Les objets de type de données utilisés pour spécifier les types de données associés aux propriétés dans l'exemple de schéma de film sont répertoriés ci-dessous:
| Propriété | Objet de type de données |
|---|---|
movieTitle |
textPropertyOptions |
releaseDate |
datePropertyOptions |
genre |
enumPropertyOptions |
duration |
textPropertyOptions |
actorName |
textPropertyOptions |
userRating |
integerPropertyOptions |
mpaaRating |
textPropertyOptions |
Le type de données que vous choisissez pour la propriété dépend de vos cas d'utilisation prévus.
Dans le scénario fictif de ce schéma de films, on s'attend à ce que les utilisateurs veuillent trier les résultats de façon chronologique, de sorte que releaseDate est un objet de date.
Si, par exemple, le cas d'utilisation prévu comprend la comparaison des sorties de décembre d'une année sur l'autre avec les sorties de janvier, un format chaîne peut s'avérer utile.
Configurer les options spécifiques au type
La section de référence PropertyDefinition renvoie aux options associées à chaque type. La plupart des options spécifiques au type sont facultatives, à l'exception de la liste de possibleValues dans enumPropertyOptions. De plus, l'option orderedRanking vous permet de classer les valeurs les unes par rapport aux autres. L'extrait suivant montre la propriété movieTitle avec textPropertyOptions définissant le type de données et avec l'option spécifique au type retrievalImportance.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
...
},
...
}
Les options spécifiques au type supplémentaires utilisées dans l'exemple de schéma sont répertoriées ci-dessous:
| Propriété | Type | Options spécifiques au type |
|---|---|---|
movieTitle |
textPropertyOptions |
retrievalImportance |
releaseDate |
datePropertyOptions |
|
genre |
enumPropertyOptions |
|
duration |
textPropertyOptions |
|
actorName |
textPropertyOptions |
|
userRating |
integerPropertyOptions |
orderedRanking, maximumValue |
mpaaRating |
textPropertyOptions |
Définir les options d'opérateur
En plus des options spécifiques au type, chaque type comporte un ensemble d'operatorOptions facultatives. Ces options décrivent la manière dont la propriété est utilisée en tant qu'opérateur de recherche. L'extrait suivant montre la propriété movieTitle avec textPropertyOptions définissant le type de données et avec les options spécifiques au type retrievalImportance et operatorOptions.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
...
}
Chaque operatorOptions a un operatorName, tel que title pour un movieTitle. Le nom de l'opérateur est l'opérateur de recherche associé à la propriété. Un opérateur de recherche est le paramètre que les utilisateurs sont censés employer pour affiner une recherche. Par exemple, pour rechercher des films en fonction de leur titre, l'utilisateur saisit normalement title:movieName, où movieName est le nom d'un film.
Les noms d'opérateur ne doivent pas obligatoirement être identiques au nom de la propriété. Vous devez plutôt utiliser des noms d'opérateur qui reflètent les mots les plus couramment employés par les utilisateurs de votre organisation. Par exemple, si vos utilisateurs préfèrent le terme "nom" à celui de "titre" pour un titre de film, le nom de l'opérateur doit être défini sur "nom".
Vous pouvez utiliser le même nom d'opérateur pour plusieurs propriétés à condition que toutes les propriétés se résolvent en un même type. Lorsqu'un nom d'opérateur partagé est utilisé dans le cadre d'une requête, toutes les propriétés employant ce nom d'opérateur sont extraites. Par exemple, supposons que l'objet "movie" ait les propriétés plotSummary et plotSynopsis, et que chacune de ces propriétés possède le operatorName plot. Si ces deux propriétés sont de type texte (textPropertyOptions), une requête unique utilisant l'opérateur de recherche plot permet de les extraire toutes les deux.
En plus de operatorName, les propriétés susceptibles d'être triées peuvent comporter des champs lessThanOperatorName et greaterThanOperatorName dans operatorOptions.
Les utilisateurs peuvent exploiter ces options pour créer des requêtes basées sur des comparaisons avec une valeur soumise.
Enfin, textOperatorOptions contient un champ exactMatchWithOperator dans operatorOptions. Si vous définissez exactMatchWithOperator sur true, la chaîne de requête doit correspondre à la valeur de propriété entière, et non uniquement à celle trouvée dans le texte.
La valeur de texte est traitée comme une valeur atomique dans les recherches avec opérateur et les correspondances d'attributs.
Par exemple, vous pouvez envisager d'indexer des objets "Book" ou "Movie" avec des propriétés de genre.
Les genres peuvent inclure "Science-Fiction", "Science" et "Fiction". Lorsque exactMatchWithOperator est défini sur false ou omis, la recherche d'un genre ou la sélection des facettes "Science" ou "Fiction" renvoie également des résultats pour "Science-Fiction", car le texte est tokenisé et les jetons "Science" et "Fiction" existent dans "Science-Fiction".
Lorsque exactMatchWithOperator est true, le texte est traité comme un jeton unique. Par conséquent, ni "Science", ni "Fiction" ne correspondent à "Science-Fiction".
(Facultatif) Ajouter la section displayOptions
Une section displayOptions facultative est présente à la fin de toute section propertyDefinition. Cette section contient une chaîne displayLabel.
displayLabel est une étiquette de texte recommandée pour la propriété (facile à retenir). Si la propriété est configurée pour l'affichage à l'aide de ObjectDisplayOptions, cette étiquette est affichée devant la propriété. Si la propriété est configurée pour l'affichage et que displayLabel n'est pas défini, seule la valeur de la propriété est affichée.
L'extrait suivant montre la propriété movieTitle avec un displayLabel défini sur "Title" (Titre).
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
Les valeurs displayLabel associées à toutes les propriétés de l'objet movie dans l'exemple de schéma sont répertoriées ci-dessous:
| Propriété | displayLabel |
|---|---|
movieTitle |
Title |
releaseDate |
Release date |
genre |
Genre |
duration |
Run length |
actorName |
Actor |
userRating |
Audience score |
mpaaRating |
MPAA rating |
(Facultatif) Ajouter une section suggestionFilteringOperators[]
Une section suggestionFilteringOperators[] facultative est présente à la fin de toute section propertyDefinition. Utilisez cette section pour définir une propriété permettant de filtrer les suggestions de saisie semi-automatique. Par exemple, vous pouvez définir l'opérateur genre pour filtrer les suggestions en fonction du genre de film préféré de l'utilisateur. Ensuite, lorsque l'utilisateur saisit sa requête de recherche, seuls les films correspondant à son genre préféré sont affichés dans les suggestions de saisie semi-automatique.
Enregistrer votre schéma
Pour obtenir des données structurées à partir de requêtes Cloud Search, vous devez enregistrer votre schéma auprès du service de schéma Cloud Search. L'enregistrement d'un schéma nécessite l'ID de source de données que vous avez obtenu lors de l'étape Initialiser une source de données.
À l'aide de l'ID de source de données, émettez une requête UpdateSchema pour enregistrer le schéma.
Comme décrit en détail sur la page de référence UpdateSchema, émettez la requête HTTP suivante pour enregistrer le schéma:
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
Le corps de la requête doit contenir les éléments suivants:
{
"validateOnly": // true or false,
"schema": {
// ... Your complete schema object ...
}
}
L'option validateOnly permet de tester la validité de votre schéma sans l'enregistrer réellement.
Indexer vos données
Une fois le schéma enregistré, remplissez la source de données à l'aide d'appels d'index. L'indexation est normalement effectuée dans le connecteur de contenu.
Avec le schéma de film, une requête d'indexation de l'API REST pour un seul film se présente comme suit:
{
"name": "datasource/<data_source_id>/items/titanic",
"acl": {
"readers": [
{
"gsuitePrincipal": {
"gsuiteDomain": true
}
}
]
},
"metadata": {
"title": "Titanic",
"sourceRepositoryUrl": "http://www.imdb.com/title/tt2234155/?ref_=nv_sr_1",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [
{
"name": "movieTitle",
"textValues": {
"values": [
"Titanic"
]
}
},
{
"name": "releaseDate",
"dateValues": {
"values": [
{
"year": 1997,
"month": 12,
"day": 19
}
]
}
},
{
"name": "actorName",
"textValues": {
"values": [
"Leonardo DiCaprio",
"Kate Winslet",
"Billy Zane"
]
}
},
{
"name": "genre",
"enumValues": {
"values": [
"Drama",
"Action"
]
}
},
{
"name": "userRating",
"integerValues": {
"values": [
8
]
}
},
{
"name": "mpaaRating",
"textValues": {
"values": [
"PG-13"
]
}
},
{
"name": "duration",
"textValues": {
"values": [
"3 h 14 min"
]
}
}
]
}
},
"content": {
"inlineContent": "A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.",
"contentFormat": "TEXT"
},
"version": "01",
"itemType": "CONTENT_ITEM"
}
Notez que la valeur de movie dans le champ objectType correspond au nom de la définition d'objet dans le schéma. En faisant correspondre ces deux valeurs, Cloud Search identifie l'objet de schéma à utiliser lors de l'indexation.
Notez également la manière dont l'indexation de la propriété de schéma releaseDate utilise les sous-propriétés year, month et day dont elle hérite, car elle est définie en tant que type de données date via l'utilisation de datePropertyOptions.
Cependant, year, month et day n'étant pas définis dans le schéma, vous ne pouvez pas lancer de requêtes séparées sur l'une de ces propriétés (par exemple, year) individuellement.
Notez également comment la propriété reproductible actorName est indexée à l'aide d'une liste de valeurs.
Identifier les problèmes d'indexation potentiels
Les deux problèmes les plus courants liés aux schémas et à l'indexation sont les suivants:
Votre requête d'indexation contient un nom objet ou de propriété de schéma qui n'a pas été enregistré auprès du service de schéma. Lorsque ce problème se produit, la propriété ou l'objet sont ignorés.
Votre requête d'indexation a une propriété avec une valeur de type différente de celle enregistrée dans le schéma. Dans ce cas, Cloud Search renvoie une erreur lors de l'indexation.
Tester votre schéma avec plusieurs types de requêtes
Avant d'enregistrer votre schéma pour un dépôt de données de production volumineux, envisagez de le tester avec un dépôt de données de test plus petit. L'utilisation d'un dépôt de test réduit vous permet de modifier rapidement le schéma et de supprimer les données indexées, sans impact sur un index plus grand ou un index de production existant. Pour un dépôt de données de test, créez une liste de contrôle d'accès autorisant un seul utilisateur de test afin que les autres utilisateurs ne puissent pas voir ces données dans les résultats de recherche.
Pour créer une interface de recherche en vue de valider les requêtes de recherche, consultez la section L'interface de recherche.
Cette section présente différents exemples de requêtes que vous pouvez utiliser pour tester un schéma de film.
Tester avec une requête générique
Une requête générique renvoie tous les éléments de la source de données contenant une chaîne spécifique. À l'aide d'une interface de recherche, vous pouvez, par exemple, exécuter une requête générique sur une source de données de films en saisissant le mot "titanic" et en appuyant sur Retour. Tous les films contenant le mot "titanic" seront renvoyés dans les résultats de recherche.
Tester avec un opérateur
L'ajout d'un opérateur à la requête limite les résultats aux éléments correspondant à cette valeur d'opérateur. Par exemple, vous pouvez utiliser l'opérateur actor pour rechercher tous les films dans lesquels joue un acteur particulier. À l'aide d'une interface de recherche, vous pouvez effectuer cette requête avec opérateur en saisissant simplement une paire opérateur=valeur, telle que "acteur:Zane", puis en appuyant sur Retour. Tous les films dans lesquels joue Zane seront renvoyés dans les résultats de la recherche.
Ajuster votre schéma
Une fois que l'exploitation de votre schéma et de vos données a débuté, continuez de surveiller ce qui fonctionne et ne fonctionne pas pour vos utilisateurs. Vous devez envisager d'ajuster votre schéma dans les cas suivants:
- Indexation d'un champ qui n'avait pas encore été indexé. Par exemple, si vos utilisateurs recherchent de manière répétée des films d'après le nom du réalisateur, vous pouvez ajuster votre schéma pour que le nom du réalisateur soit utilisé en tant qu'opérateur.
- Modification du nom des opérateurs de recherche en fonction des commentaires des utilisateurs. Les noms d'opérateurs sont conçus pour être faciles à utiliser. Si vos utilisateurs se trompent constamment lors de la saisie d'un nom d'opérateur, vous pouvez envisager de le changer.
Réindexation après une modification du schéma
La modification des valeurs suivantes dans votre schéma ne nécessite pas la réindexation de vos données. Votre index continuera de fonctionner lorsque vous soumettrez une nouvelle requête UpdateSchema:
- Noms d'opérateur
- Valeurs entières minimales et maximales
- Classement ordonné par valeurs entières et valeurs d'énumération
- Options relatives à l'actualisation
- Options d'affichage
Pour les modifications suivantes, les données précédemment indexées continueront de fonctionner selon le schéma précédemment enregistré. Vous devrez réindexer les entrées existantes pour voir les modifications en fonction du schéma mis à jour si les modifications suivantes ont été apportées:
- Ajouter ou supprimer une propriété ou un objet
- Modification de
isReturnable,isFacetableouisSortabledefalseentrue.
Vous devez définir isFacetable ou isSortable sur true uniquement si cela répond à un cas d'utilisation et un besoin clairement déterminés.
Enfin, lorsque vous mettez à jour votre schéma en marquant une propriété isSuggestable, vous devez réindexer vos données, ce qui retarde l'utilisation de la saisie semi-automatique pour cette propriété.
Modifications de propriété non autorisées
Certaines modifications de schéma ne sont pas autorisées, même si vous réindexez vos données, car elles corrompraient l'index ou produiraient des résultats de recherche insatisfaisants ou incohérents. Elles incluent les modifications relatives aux éléments suivants:
- Type de données de propriété
- Nom de propriété
- Paramètre
exactMatchWithOperator. - Paramètre
retrievalImportance.
Cependant, il existe un moyen de contourner cette limitation.
Exécuter une modification de schéma complexe
Afin d'éviter les modifications qui produiraient des résultats de recherche insatisfaisants ou corrompraient l'index de recherche, Cloud Search interdit certains types de modifications dans les requêtes UpdateSchema après l'indexation du dépôt. Par exemple, le type de données ou le nom d'une propriété ne peuvent pas être modifiés une fois qu'ils ont été définis. Ces modifications ne peuvent pas être effectuées par une simple requête UpdateSchema, même si vous réindexez les données.
Il est souvent possible d'apporter au schéma une modification normalement non autorisée au moyen d'une série de modifications autorisées permettant de parvenir au même résultat. En général, cela nécessite de faire migrer les propriétés indexées d'une ancienne définition d'objet vers une nouvelle, puis d'envoyer une requête d'indexation utilisant uniquement la nouvelle propriété.
La procédure suivante décrit comment modifier le type de données ou le nom d'une propriété:
- Ajoutez une nouvelle propriété à la définition d'objet dans votre schéma. Utilisez un nom différent de la propriété que vous souhaitez modifier.
- Soumettez la requête UpdateSchema avec la nouvelle définition. N'oubliez pas d'inclure le schéma complet, y compris la nouvelle et l'ancienne propriétés, dans la requête.
Remplissez l'index à partir du dépôt de données. Pour remplir l'index, envoyez toutes les requêtes d'indexation avec la nouvelle propriété, mais pas l'ancienne, car cela entraînerait un double comptage des correspondances de requête.
- Durant le remplissage de l'index, recherchez la nouvelle propriété et remplacez-la par l'ancienne propriété par défaut afin d'éviter tout comportement incohérent.
- Une fois le remplissage terminé, exécutez des requêtes de test pour vérifier.
Supprimez l'ancienne propriété. Émettez une autre requête UpdateSchema sans l'ancien nom de propriété et arrêtez d'utiliser l'ancien nom de propriété dans les requêtes d'indexation suivantes.
Transférez toutes les utilisations de l'ancienne propriété vers la nouvelle propriété. Par exemple, si vous modifiez le nom de la propriété de "créateur" en "auteur", vous devez mettre à jour le code de votre requête pour qu'il utilise "auteur" là où il indiquait précédemment "créateur".
Cloud Search conserve un enregistrement de l'ensemble des propriétés et des objets supprimés pendant 30 jours afin d'éviter toute réutilisation susceptible d'entraîner des résultats d'indexation inattendus. Pendant ces 30 jours, vous devez effectuer toutes les migrations nécessaires afin d'éviter que l'objet ou la propriété supprimés ne soient utilisés, y compris en veillant à ne pas les utiliser dans les futures requêtes d'indexation. Si vous décidez ultérieurement de rétablir cette propriété ou cet objet, vous pourrez ainsi préserver l'exactitude de votre index.
Connaître les limites de taille
Cloud Search impose des limites à la taille des objets de données structurées et des schémas. Ces limites sont les suivantes:
- Le nombre maximal d'objets de premier niveau est de 10.
- La profondeur maximale d'une arborescence de données structurées est de 10 niveaux.
- Le nombre total de champs dans un objet est limité à 1 000. Ce nombre inclut le nombre de champs primitifs et la somme des nombres de champs correspondant aux objets imbriqués.
Étapes suivantes
Voici quelques étapes que vous pouvez également suivre :
Créez une interface de recherche pour tester votre schéma.
Ajustez votre schéma pour améliorer la qualité de la recherche.
Structurez un schéma pour une interprétation optimale des requêtes.
Apprendre à exploiter le schéma
_dictionaryEntrypour définir des synonymes des termes couramment utilisés dans votre entreprise. Pour utiliser le schéma_dictionaryEntry, consultez Définir des synonymes.Créez un connecteur.