
ML Kit Pose Detection API یک راه حل همه کاره سبک وزن برای توسعه دهندگان برنامه است تا وضعیت بدن یک سوژه را در زمان واقعی از یک ویدیوی مداوم یا تصویر ثابت تشخیص دهند. یک ژست موقعیت بدن را در یک لحظه در زمان با مجموعه ای از نقاط برجسته اسکلتی توصیف می کند. نشانه ها مربوط به قسمت های مختلف بدن مانند شانه ها و باسن هستند. موقعیتهای نسبی نشانهها را میتوان برای تشخیص یک ژست از دیگری استفاده کرد.
ML Kit Pose Detection یک تطابق اسکلتی 33 نقطهای برای تمام بدن ایجاد میکند که شامل نقاط برجسته صورت (گوشها، چشمها، دهان و بینی) و نقاط روی دستها و پاها میشود. شکل 1 زیر نشانه هایی را نشان می دهد که از طریق دوربین به کاربر نگاه می کنند، بنابراین یک تصویر آینه ای است. سمت راست کاربر در سمت چپ تصویر ظاهر می شود:
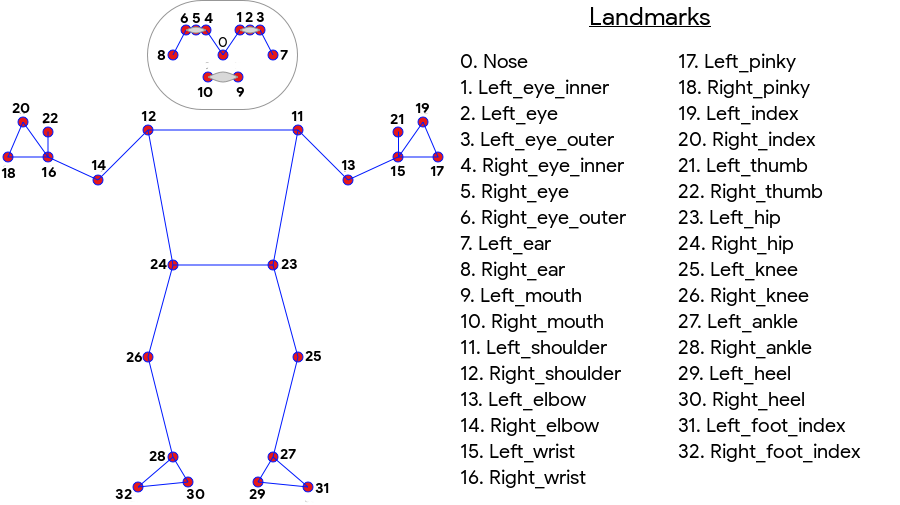
تشخیص وضعیت کیت ML برای دستیابی به نتایج عالی به تجهیزات تخصصی یا تخصص ML نیاز ندارد. با استفاده از این فناوری، توسعه دهندگان می توانند تنها با چند خط کد، تجربه های بی نظیری را برای کاربران خود ایجاد کنند.
برای تشخیص حالت، چهره کاربر باید حضور داشته باشد. تشخیص پوس زمانی بهترین کار را انجام می دهد که کل بدن سوژه در کادر قابل مشاهده باشد، اما ژست جزئی بدن را نیز تشخیص می دهد. در این صورت، نشانه هایی که شناسایی نمی شوند، مختصاتی خارج از تصویر اختصاص داده می شوند.
قابلیت های کلیدی
- پشتیبانی از چند پلتفرم از تجربه یکسانی در اندروید و iOS لذت ببرید.
- ردیابی کامل بدن این مدل 33 نقطه برجسته اسکلتی، از جمله موقعیت دست ها و پاها را برمی گرداند.
- امتیاز InFrameLikelihood برای هر علامت مشخصه، معیاری است که احتمال قرار گرفتن نقطه عطف در قاب تصویر را نشان می دهد. امتیاز دارای دامنه ای از 0.0 تا 1.0 است که در آن 1.0 نشان دهنده اطمینان بالا است.
- دو SDK بهینه شده SDK پایه در تلفنهای مدرن مانند Pixel 4 و iPhone X بهصورت بلادرنگ اجرا میشود. نتایج را به ترتیب با سرعت 30 و ~45 فریم در ثانیه برمیگرداند. با این حال، دقت مختصات نقطه عطف ممکن است متفاوت باشد. SDK دقیق نتایج را با نرخ فریم کندتر برمی گرداند، اما مقادیر مختصات دقیق تری تولید می کند.
- مختصات Z برای تجزیه و تحلیل عمق این مقدار می تواند به تعیین اینکه آیا قسمت هایی از بدن کاربر در جلو یا پشت باسن کاربر قرار دارد کمک می کند. برای اطلاعات بیشتر، بخش Z Coordinate را در زیر ببینید.
Pose Detection API شبیه به Facial Recognition API است که مجموعه ای از نشانه ها و مکان آنها را برمی گرداند. با این حال، در حالی که تشخیص چهره همچنین سعی میکند ویژگیهایی مانند دهان خندان یا چشمان باز را تشخیص دهد، Pose Detection هیچ معنایی به نشانههای یک ژست یا خود ژست نمیدهد. شما می توانید الگوریتم های خود را برای تفسیر یک ژست ایجاد کنید. برای چند نمونه به نکات طبقه بندی پوز مراجعه کنید.
تشخیص پوس فقط می تواند یک نفر را در یک تصویر تشخیص دهد. اگر دو نفر در تصویر باشند، مدل به فردی که با بالاترین اطمینان شناسایی شده است، نشانههای مشخصی را اختصاص میدهد.
Z مختصات
مختصات Z یک مقدار آزمایشی است که برای هر نقطه عطف محاسبه می شود. در "پیکسل های تصویر" مانند مختصات X و Y اندازه گیری می شود، اما یک مقدار سه بعدی واقعی نیست. محور Z عمود بر دوربین است و از بین باسن سوژه عبور می کند. مبدا محور Z تقریباً نقطه مرکزی بین باسن (چپ/راست و جلو/پشت نسبت به دوربین) است. مقادیر Z منفی به سمت دوربین است. ارزش های مثبت از آن دور است. مختصات Z کران بالایی یا پایینی ندارد.
نتایج نمونه
جدول زیر مختصات و InFrameLikelihood را برای چند نشانه در حالت سمت راست نشان می دهد. توجه داشته باشید که مختصات Z برای دست چپ کاربر منفی است، زیرا در جلوی مرکز باسن سوژه و به سمت دوربین قرار دارند.

| نقطه عطف | تایپ کنید | موقعیت | InFrameLikelihood |
|---|---|---|---|
| 11 | شانه چپ | (734.9671، 550.7924، -118.11934) | 0.9999038 |
| 12 | RIGHT_SHOULDER | (391.27032, 583.2485, -321.15836) | 0.9999894 |
| 13 | LEFT_ELBOW | (903.83704، 754.676، -219.67009) | 0.9836427 |
| 14 | RIGHT_ELBOW | (322.18152, 842.5973, -179.28519) | 0.99970156 |
| 15 | مچ دست چپ | (1073.8956، 654.9725، -820.93463) | 0.9737737 |
| 16 | RIGHT_WRIST | (218.27956، 1015.70435، -683.6567) | 0.995568 |
| 17 | LEFT_PINKY | (1146.1635، 609.6432، -956.9976) | 0.95273364 |
| 18 | RIGHT_PINKY | (176.17755، 1065.838، -776.5006) | 0.9785348 |
در زیر کاپوت
برای جزئیات پیاده سازی بیشتر در مورد مدل های ML اساسی برای این API، پست وبلاگ Google AI ما را بررسی کنید.
برای کسب اطلاعات بیشتر در مورد شیوه های منصفانه ML ما و نحوه آموزش مدل ها، به کارت مدل ما مراجعه کنید