
L'API ML Kit Pose Detection è una soluzione versatile e leggera per gli sviluppatori di app che consente di rilevare la posizione del corpo di un soggetto in tempo reale da un video continuo o da un'immagine statica. Una posa descrive la posizione del corpo in un momento temporale con una serie di punti di riferimento scheletrici. I punti di riferimento corrispondono a diverse parti del corpo, come spalle e fianchi. La posizione relativa dei punti di riferimento può essere utilizzata per distinguere una posa dall'altra.
ML Kit Pose Detection produce un abbinamento scheletrico a 33 punti del viso che include punti di riferimento del viso (orecchie, occhi, bocca e naso) e punti su mani e piedi. La Figura 1 di seguito mostra i punti di riferimento che guardano l'utente attraverso la fotocamera, quindi è un'immagine speculare. Il lato destro dell'utente viene visualizzato a sinistra dell'immagine:
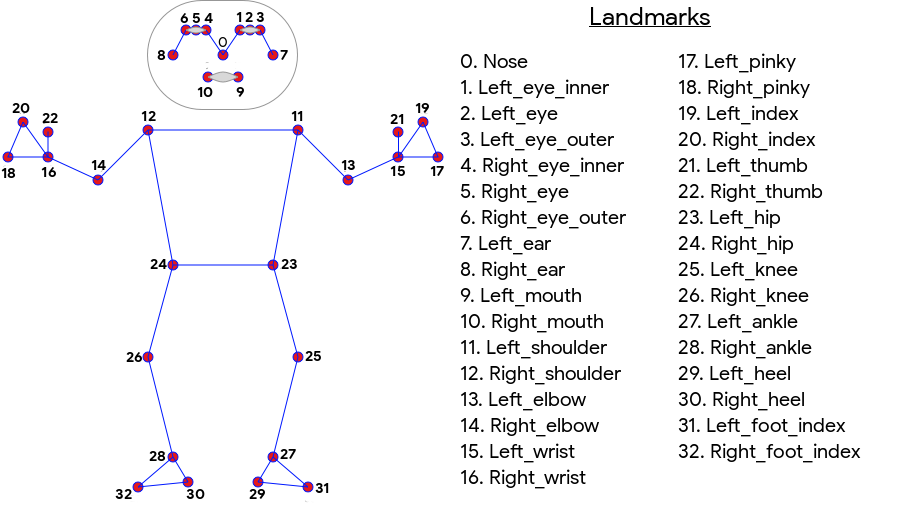
Il rilevamento delle posizioni di ML Kit non richiede apparecchiature specializzate o esperienza in ML per ottenere ottimi risultati. Grazie a questa tecnologia, gli sviluppatori possono creare esperienze uniche per gli utenti con poche righe di codice.
Il volto dell'utente deve essere presente per poter rilevare la posa. Il rilevamento della posizione funziona meglio quando tutto il corpo del soggetto è visibile nell'inquadratura, ma rileva anche una posa parziale del corpo. In questo caso, ai punti di riferimento non riconosciuti vengono assegnate coordinate esterne all'immagine.
Funzionalità chiave
- Supporto per più piattaforme Usufruisci della stessa esperienza sia su Android che su iOS.
- Monitoraggio completo del corpo Il modello restituisce 33 punti di riferimento principali dello scheletro, tra cui le posizioni di mani e piedi.
- Punteggio InFrameLikelihood Per ogni punto di riferimento, una misura che indica la probabilità che il punto di riferimento si trovi all'interno del frame dell'immagine. Il punteggio ha un intervallo da 0,0 a 1,0, dove 1,0 indica un'elevata affidabilità.
- Due SDK ottimizzati. L'SDK di base viene eseguito in tempo reale su smartphone moderni come Pixel 4 e iPhone X. Restituisce i risultati rispettivamente a una frequenza di ~30 e ~45 fps. Tuttavia, la precisione delle coordinate dei punti di riferimento può variare. L'SDK preciso restituisce risultati con una frequenza fotogrammi più lenta, ma produce valori delle coordinate più precisi.
- Coordinata Z per l'analisi di profondità Questo valore può aiutare a determinare se parti del corpo dell'utente si trovano davanti o dietro i fianchi. Per ulteriori informazioni, consulta la sezione Coordinata Z di seguito.
L'API Pose Detection è simile all'API Faacial Recognition in quanto restituisce un insieme di punti di riferimento e la relativa posizione. Tuttavia, sebbene la funzionalità di riconoscimento facciale cerchi anche di riconoscere funzionalità come la bocca sorridente o gli occhi aperti, la funzionalità di rilevamento della posizione non attribuisce alcun significato ai punti di riferimento in una posa o alla posa stessa. Puoi creare i tuoi algoritmi per interpretare una posa. Consulta i suggerimenti per la classificazione delle posizioni per alcuni esempi.
Il rilevamento delle posizioni può rilevare solo una persona in un'immagine. Se nell'immagine sono presenti due persone, il modello assegnerà i punti di riferimento alla persona rilevata con la maggiore affidabilità.
Coordinata Z
La coordinata Z è un valore sperimentale calcolato per ogni punto di riferimento. Si misura in "pixel immagine", come le coordinate X e Y, ma non è un vero valore 3D. L'asse Z è perpendicolare alla fotocamera e passa tra i fianchi del soggetto. L'origine dell'asse Z è approssimativamente il punto centrale tra i fianchi (sinistra/destra e anteriore/posteriore rispetto alla fotocamera). I valori Z negativi sono rivolti alla fotocamera; i valori positivi sono lontani da tale valore. La coordinata Z non ha un limite superiore o inferiore.
Risultati di esempio
La seguente tabella mostra le coordinate e InFrame Likelihood per alcuni punti di riferimento nella posa a destra. Tieni presente che le coordinate Z per la mano sinistra dell'utente sono negative, perché si trovano di fronte al centro dei fianchi del soggetto e verso la fotocamera.

| Punto di riferimento | Tipo | Posizione | InFrameLikelihood |
|---|---|---|---|
| 11 | LEFT_SHOULDER | (734,9671, 550,7924, -118,11934) | 0,9999038 |
| 12 | RIGHT_SHOULDER | (391,27032, 583,2485, -321,15836) | 0,9999894 |
| 13 | LEFT_ELBOW | (903,83704, 754,676, -219,67009) | 0,9836427 |
| 14 | RIGHT_ELBOW | (322,18152, 842,5973, -179,28519) | 0,99970156 |
| 15 | LEFT_WRIST | (1073,8956, 654,9725, -820,93463) | 0,9737737 |
| 16 | RIGHT_WRIST | (218,27956, 1015,70435, -683,6567) | 0,995568 |
| 17 | LEFT_PINKY | (1146,1635, 609,6432, -956,9976) | 0,95273364 |
| 18 | RIGHT_PINKY | (176,17755, 1065,838, -776,5006) | 0,9785348 |
Uno sguardo alle caratteristiche
Per ulteriori dettagli sull'implementazione dei modelli ML sottostanti per questa API, consulta il post del blog sull'IA di Google.
Per scoprire di più sulle nostre pratiche di equità nel machine learning e su come sono stati addestrati i modelli, consulta la nostra scheda del modello