
ML Kit Pose Detection API は、アプリ デベロッパーが連続した動画または静止画像から被写体の姿勢をリアルタイムで検出できる、軽量で汎用性の高いソリューションです。ポーズは、一連の骨格のランドマーク ポイントで、ある時点での身体の位置を表します。ランドマークは、肩や腰など、さまざまな部位に対応しています。ランドマークの相対位置を使用して、ポーズを区別できます。
ML Kit 姿勢検出では、顔のランドマーク(耳、目、口、鼻)と手と足の点を含む、全身の 33 ポイントのスケルタルマッチが生成されます。以下の図 1 は、ユーザーのカメラを通してランドマークが映っているため、鏡像になっています。ユーザーの右側が画像の左側に表示されます。
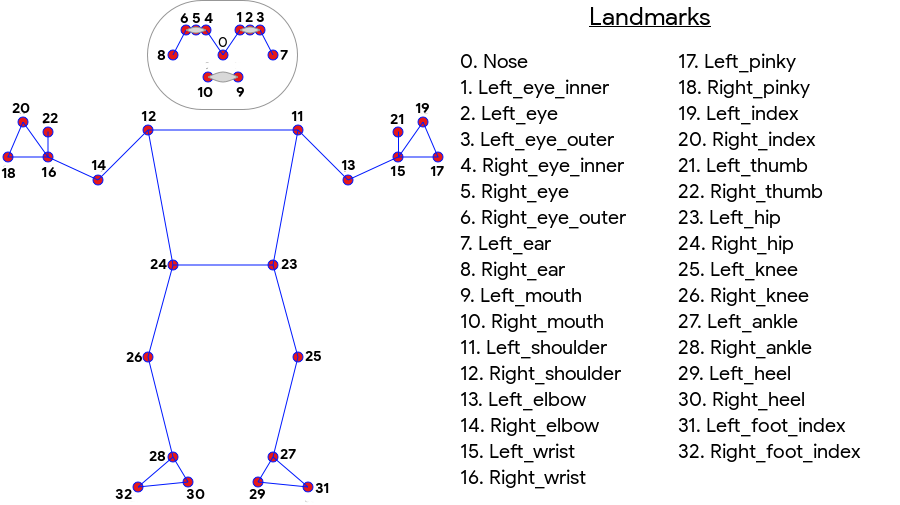
ML Kit 姿勢検出では、優れた結果を得るために特別な機器や ML の専門知識は必要ありません。この技術により、デベロッパーはわずか数行のコードでユーザーに唯一無二のエクスペリエンスを構築できます。
ポーズを検出するには、ユーザーの顔が存在する必要があります。姿勢検出は、被写体の身体全体がフレーム内に収まっている場合に最も効果的に機能しますが、身体の一部のポーズも検出します。認識されないランドマークには、画像外の座標が割り当てられます。
主な機能
- クロス プラットフォームのサポート: Android と iOS の両方で同じエクスペリエンスを提供します。
- 全身のトラッキング: モデルは、手と足の位置など、33 の主要な骨格的ランドマーク ポイントを返します。
- InFrameLikelihood スコア: ランドマークごとに、ランドマークが画像フレーム内にある確率を示す尺度。スコアの範囲は 0.0 ~ 1.0 で、1.0 は高い信頼度を示します。
- 最適化された 2 つの SDK。ベース SDK は、Google Pixel 4 や iPhone X などの最新のスマートフォンでリアルタイムで動作します。それぞれ約 30 fps と約 45 fps のレートで結果が返されます。ただし、ランドマークの座標の精度は異なる場合があります。正確な SDK は遅いフレームレートで結果を返しますが、より正確な座標値を生成します。
- 深度分析の Z 座標: この値は、ユーザーの身体の一部がユーザーの腰の前にあるか背後にあるかを判断するのに役立ちます。詳しくは、以下の Z 座標のセクションをご覧ください。
Pose Detection API はランドマークと位置情報のセットを返すという点で、Facial Recognition API と似ています。ただし、顔検出では、笑顔や開いた目などの機能の認識も試みられますが、姿勢検出では、ポーズのランドマークやポーズ自体に意味はありません。ポーズを解釈する独自のアルゴリズムを作成できます例については、姿勢分類のヒントをご覧ください。
姿勢検出では、画像の中の 1 人の人物しか検出できません。画像に 2 人の人物が写っている場合、モデルは最も信頼度の高い人物にランドマークを割り当てます。
Z 座標
Z 座標は、すべてのランドマークに対して計算される試験運用版の値です。X 座標および Y 座標と同様に「画像ピクセル」で測定されますが、実際の 3D 値ではありません。Z 軸はカメラに直交し、被写体の腰の間を通ります。Z 軸の原点は、腰の間のほぼ中心点(カメラを基準とした左右および前後)です。負の Z 値はカメラに向かって、正の値はカメラから離れています。 Z 座標に上限も下限もありません。
サンプル結果
次の表は、右側のポーズのランドマークの座標と InFrameLikelihood を示しています。ユーザーの左手の Z 座標は負の座標です。これは、被写体の腰の中心の前でカメラの方が多いためです。

| ランドマーク | タイプ | 職位 | InFrameLikelihood |
|---|---|---|---|
| 11 | LEFT_SHOULDER | (734.9671, 550.7924, -118.11934) | 0.9999038 |
| 12 | RIGHT_SHOULDER | (391.27032、583.2485、-321.15836) | 0.9999894 |
| 13 | LEFT_ELBOW | (903.83704、754.676、-219.67009) | 0.9836427 |
| 14 | RIGHT_ELBOW | (322.18152、842.5973、-179.28519) | 0.99970156 |
| 15 | LEFT_WRIST | (1073.8956、654.9725、-820.93463) | 0.9737737 |
| 16 | RIGHT_WRIST | (218.27956, 1015.70435, -683.6567) | 0.995568 |
| 17 | LEFT_PINKY | (1146.1635、609.6432、-956.9976) | 0.95273364 |
| 18 | RIGHT_PINKY | (176.17755, 1065.838, -776.5006) | 0.9785348 |
仕組み
この API の基盤となる ML モデルの実装の詳細については、Google AI のブログ投稿をご覧ください。
ML の公平性の実践とモデルのトレーニング方法の詳細については、モデルカードをご覧ください。