
1. Requisitos previos
Para realizar este codelab, se requieren algunos requisitos previos. Cada requisito se marca según si es necesario para las "Pruebas locales" o el "Servicio de agregación".
1.1. Descarga la herramienta de pruebas locales (pruebas locales)
Para realizar pruebas locales, deberás descargar la herramienta de pruebas locales. La herramienta generará informes de resumen a partir de los informes de depuración sin encriptar.
La herramienta de pruebas locales está disponible para descargar en los archivos JAR de Lambda en GitHub. Debe llamarse LocalTestingTool_{version}.jar.
1.2. Asegúrate de que el JRE de Java esté instalado (servicio de agregación y pruebas locales)
Abre "Terminal" y usa java --version para verificar si tu máquina tiene instalado Java o openJDK.

Si no está instalado, puedes descargarlo e instalarlo desde el sitio de Java o el sitio de openJDK.
1.3. Descarga el convertidor de informes agregables (servicio de pruebas y agregación locales)
Puedes descargar una copia del convertidor de informes agregables desde el repositorio de GitHub de Demos de Privacy Sandbox.
1.4. Habilita las APIs de privacidad en los anuncios (servicio de agregación y pruebas locales)
En el navegador, ve a chrome://settings/adPrivacy y habilita todas las APIs de privacidad en los anuncios.
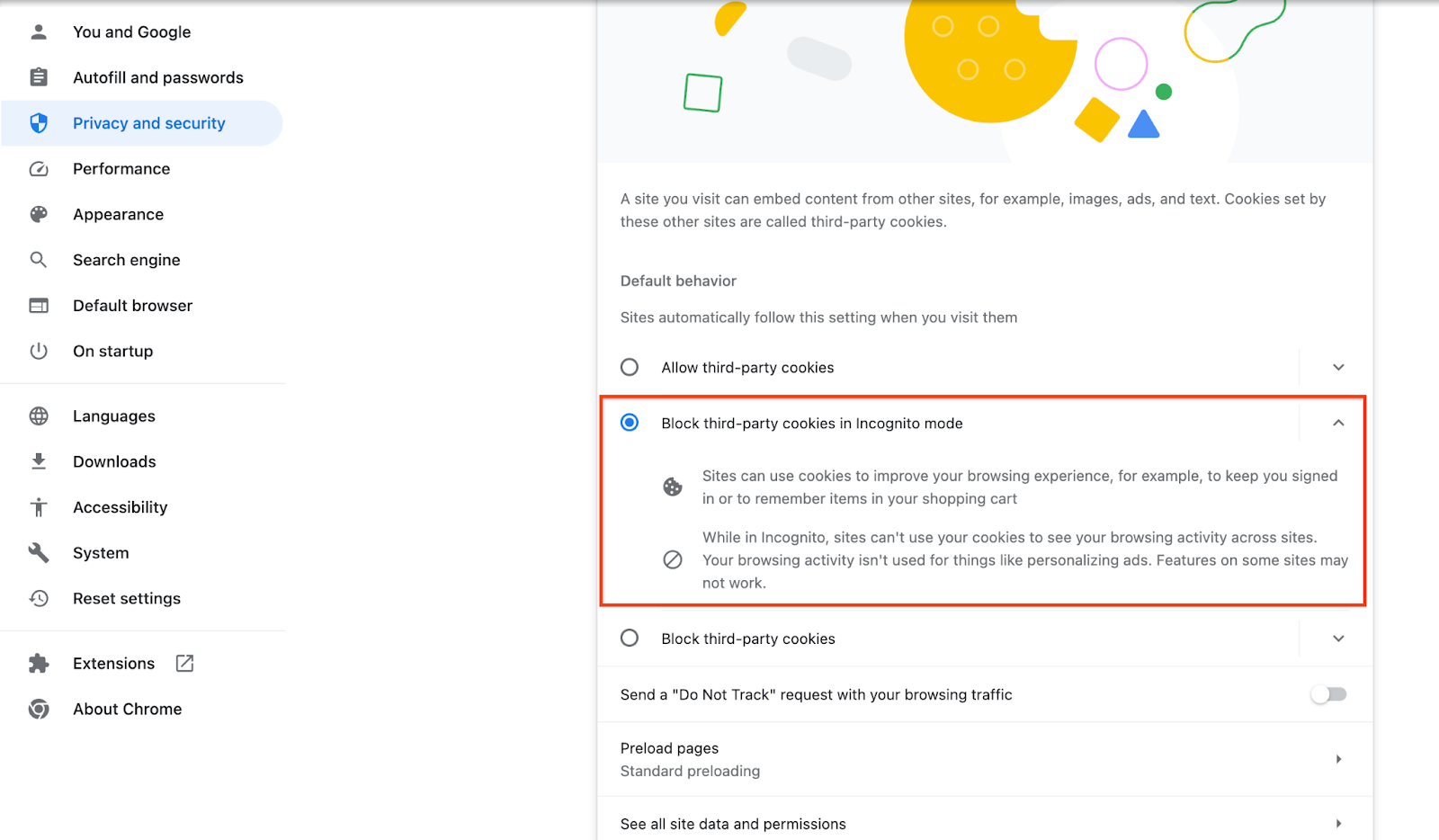
Asegúrate de que las cookies de terceros estén habilitadas.
En el navegador, ve a chrome://settings/cookies y selecciona "Bloquear cookies de terceros en el modo Incógnito".
1.5. Inscripción en la Web y Android (servicio de agregación)
Para usar las APIs de Privacy Sandbox en un entorno de producción, asegúrate de haber completado la inscripción y la certificación para Chrome y Android.
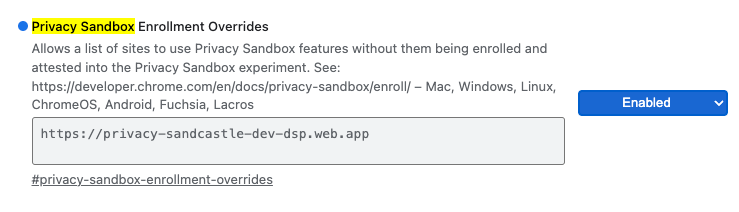
Para las pruebas locales, la inscripción se puede inhabilitar con una marca de Chrome y un interruptor de la CLI.
Para usar la marca de Chrome en nuestra demostración, ve a chrome://flags/#privacy-sandbox-enrollment-overrides y actualiza la anulación con tu sitio. Si usarás nuestro sitio de demostración, no es necesario que realices ninguna actualización.
1.6. Integración del servicio de agregación (servicio de agregación)
El servicio de agregación requiere la integración con los coordinadores para poder usarlo. Completa el formulario de integración del servicio de agregación proporcionando la dirección de tu sitio de informes, el ID de cuenta de AWS y otra información.
1.7. Proveedor de servicios en la nube (servicio de agregación)
El servicio de agregación requiere el uso de un entorno de ejecución confiable que usa un entorno de nube. El servicio de agregación es compatible con Amazon Web Services (AWS) y Google Cloud (GCP). En este codelab, solo se abordará la integración de AWS.
AWS proporciona un entorno de ejecución confiable llamado Enclaves de Nitro. Asegúrate de tener una cuenta de AWS y sigue las instrucciones de instalación y actualización de la CLI de AWS para configurar tu entorno de la CLI de AWS.
Si tu AWS CLI es nueva, puedes configurarla con las instrucciones de configuración de la CLI.
1.7.1. Crea un bucket de AWS S3
Crea un bucket de AWS S3 para almacenar el estado de Terraform y otro bucket de S3 para almacenar tus informes y resúmenes. Puedes usar el comando de la CLI proporcionado. Reemplaza el campo en <> por las variables adecuadas.
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. Crea una clave de acceso de usuario
Crea claves de acceso de usuario con la guía de AWS. Se usará para llamar a los extremos de la API de createJob y getJob creados en AWS.
1.7.3. Permisos de usuarios y grupos de AWS
Para implementar el servicio de agregación en AWS, deberás proporcionar ciertos permisos al usuario que se usa para implementar el servicio. Para este codelab, asegúrate de que el usuario tenga acceso de administrador para garantizar que tenga permisos completos en la implementación.
1.8. Terraform (servicio de agregación)
En este codelab, se usa Terraform para implementar el servicio de agregación. Asegúrate de que el objeto binario de Terraform esté instalado en tu entorno local.
Descarga el objeto binario de Terraform en tu entorno local.
Una vez que se descargue el objeto binario de Terraform, extrae el archivo y muévelo a /usr/local/bin.
cp <directory>/terraform /usr/local/bin
Asegúrate de que Terraform esté disponible en el classpath.
terraform -v
1.9. Postman (para el servicio de agregación de AWS)
En este codelab, usa Postman para la administración de solicitudes.
Para crear un lugar de trabajo, ve al elemento de navegación superior "Espacios de trabajo" y selecciona "Crear lugar de trabajo".
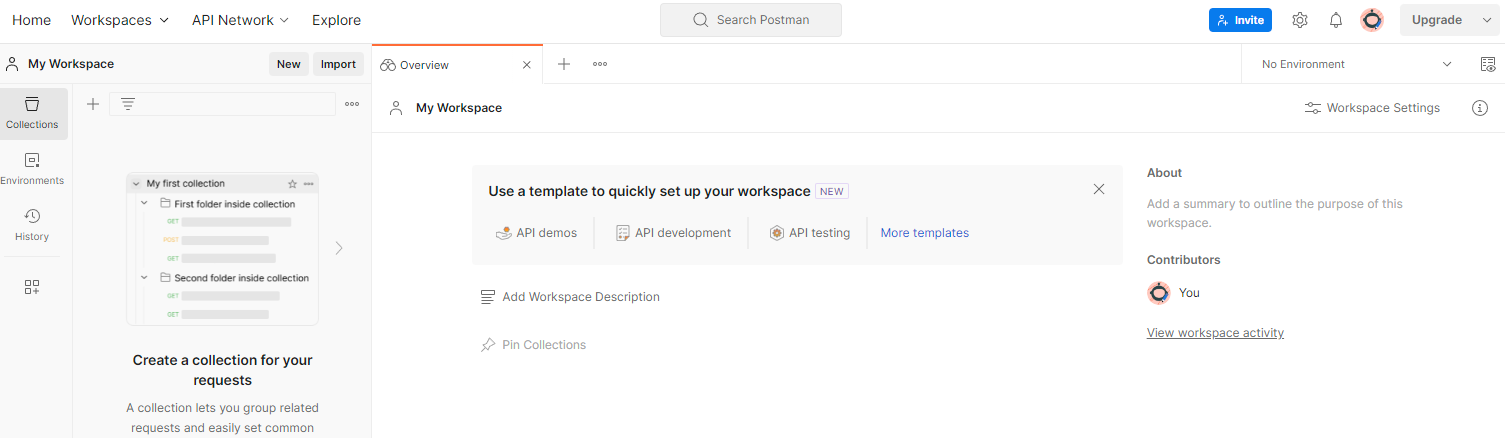
Selecciona "Espacio de trabajo en blanco", haz clic en Siguiente y asígnale el nombre "Zona de pruebas de privacidad". Selecciona “Personal” y haz clic en “Crear”.
Descarga los archivos JSON de configuración y Global Environment del lugar de trabajo preconfigurado.
Importa los archivos JSON a "Mi espacio de trabajo" con el botón "Importar".

Esto creará la colección de Privacy Sandbox junto con las solicitudes HTTP de createJob y getJob.
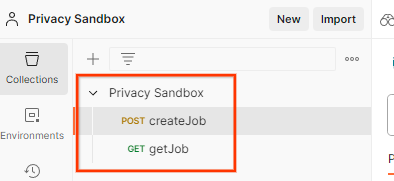
Actualiza la "Clave de acceso" y la "Clave secreta" de AWS a través de "Vista rápida del entorno".
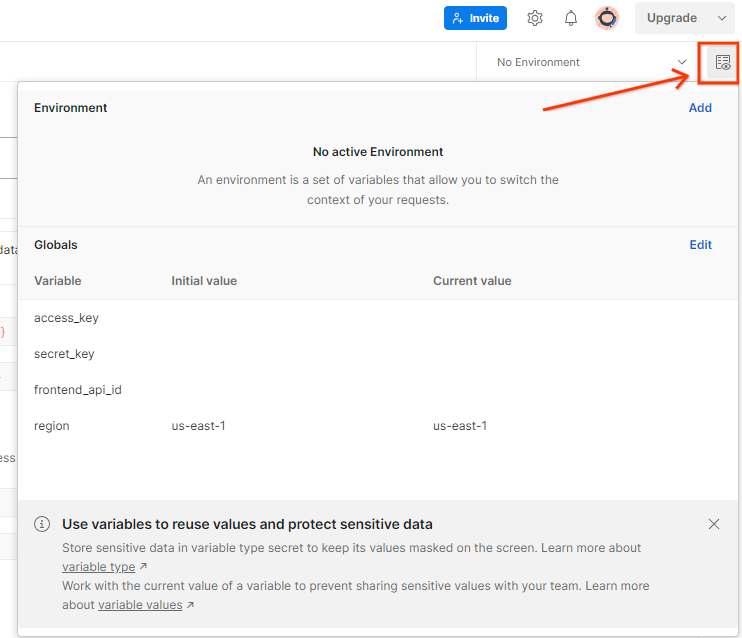
Haz clic en "Editar" y actualiza el "Valor actual" de "access_key" y "secret_key". Ten en cuenta que frontend_api_id se proporcionará en la sección 3.1.4 de este documento. Además, te recomendamos que uses la región us-east-1. Sin embargo, si deseas realizar la implementación en una región diferente, asegúrate de copiar el AMI publicado en tu cuenta o de realizar una compilación manual con las secuencias de comandos proporcionadas.

2. Codelab de pruebas locales
Puedes usar la herramienta de prueba local en tu máquina para realizar la agregación y generar informes de resumen con los informes de depuración sin encriptar.
Pasos del codelab
Paso 2.1: Activar informe: Activa los informes de agregación privada para poder recopilarlos.
Paso 2.2. Crear un informe agregable de depuración: Convierte el informe JSON recopilado en un informe con formato AVRO.
Este paso será similar al momento en que las tecnologías publicitarias recopilan los informes de los extremos de informes de la API y convierten los informes JSON en informes con formato AVRO.
Paso 2.3. Analiza la clave de bucket del informe de depuración: Las tecnologías publicitarias diseñan las claves de bucket. En este codelab, como los buckets están predefinidos, recupera las claves de bucket como se proporciona.
Paso 2.4. Crea el archivo AVRO del dominio de salida: Una vez que se recuperen las claves del bucket, crea el archivo AVRO del dominio de salida.
Paso 2.5: Crea informes de resumen con la herramienta de pruebas locales: Usa la herramienta de pruebas locales para poder crear informes de resumen en el entorno local.
Paso 2.6. Revisa el informe de resumen: Revisa el informe de resumen que crea la herramienta de prueba local.
2.1. Informe de activadores
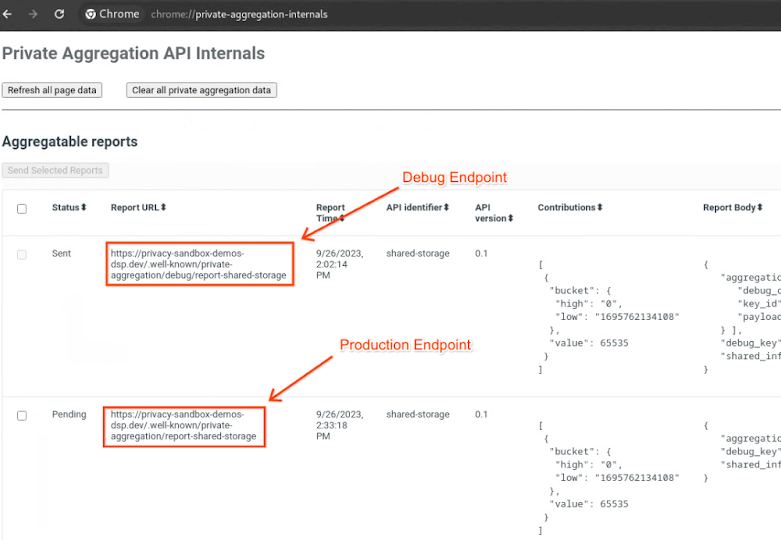
Ve al sitio de la demo de Privacy Sandbox. Esto activa un informe de agregación privado. Puedes ver el informe en chrome://private-aggregation-internals.
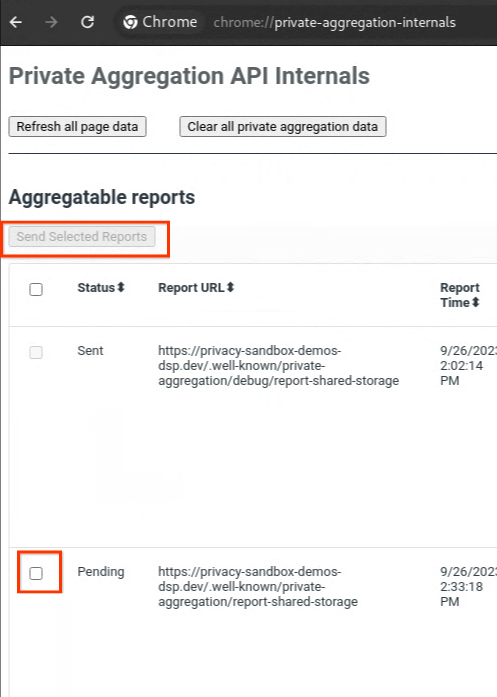
Si tu informe tiene el estado "Pendiente", puedes seleccionarlo y hacer clic en "Enviar informes seleccionados".
2.2. Crea un informe agregable de depuración
En chrome://private-aggregation-internals, copia el "Cuerpo del informe" que se recibió en el extremo [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
Asegúrate de que, en "Cuerpo del informe", aggregation_coordinator_origin contenga https://publickeyservice.msmt.aws.privacysandboxservices.com, lo que significa que el informe es un informe agregable de AWS.
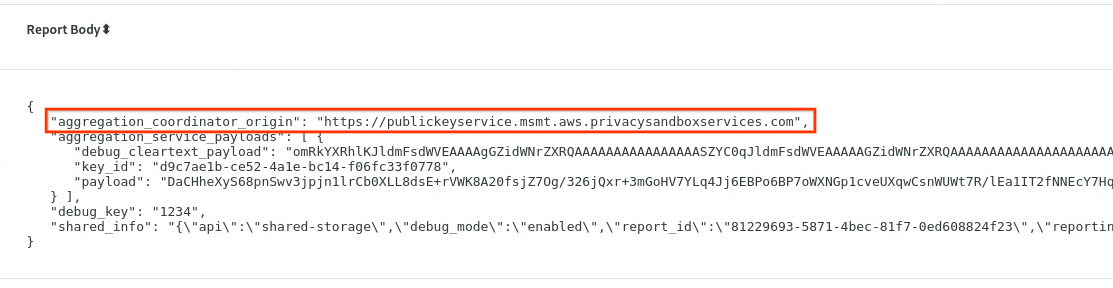
Coloca el JSON "Report Body" en un archivo JSON. En este ejemplo, puedes usar vim. Sin embargo, puedes usar el editor de texto que quieras.
vim report.json
Pega el informe en report.json y guarda el archivo.

Una vez que lo tengas, navega a la carpeta de informes y usa aggregatable_report_converter.jar para crear el informe agregable de depuración. Esto crea un informe agregable llamado report.avro en tu directorio actual.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Analiza la clave del bucket del informe de depuración
El servicio de agregación requiere dos archivos cuando se realiza el procesamiento por lotes. El informe agregable y el archivo de dominio de salida El archivo de dominio de salida contiene las claves que deseas recuperar de los informes agregables. Para crear el archivo output_domain.avro, necesitas las claves de bucket que se pueden recuperar de los informes.
El llamador de la API diseña las claves de bucket, y la demo contiene ejemplos de claves de bucket precompiladas. Dado que la demostración habilitó el modo de depuración para la agregación privada, puedes analizar la carga útil de texto simple de depuración del "Cuerpo del informe" para recuperar la clave del bucket. Sin embargo, en este caso, la demo de Privacy Sandbox del sitio crea las claves de bucket. Dado que la agregación privada para este sitio está en modo de depuración, puedes usar el debug_cleartext_payload del "Cuerpo del informe" para obtener la clave del bucket.
Copia el debug_cleartext_payload del cuerpo del informe.

Abre la herramienta Debug payload decoder for Private Aggregation, pega tu debug_cleartext_payload en el cuadro "INPUT" y haz clic en "Decode".
La página muestra el valor decimal de la clave del bucket. La siguiente es una clave de bucket de ejemplo.
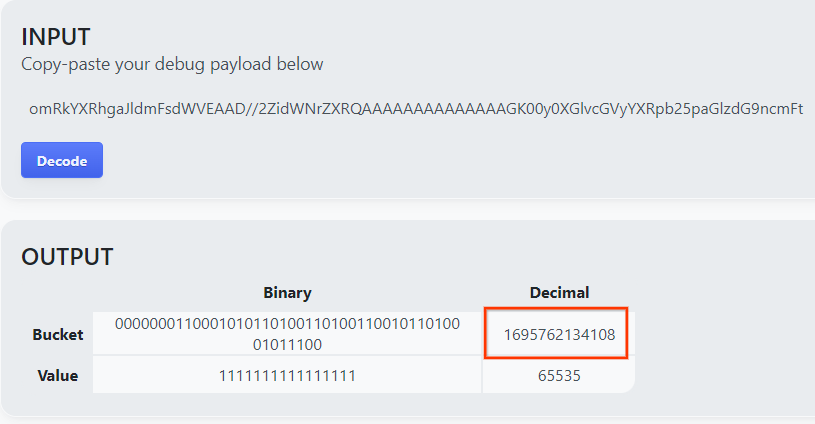
2.4. Crea el dominio de salida AVRO
Ahora que tenemos la clave del bucket, copia el valor decimal de la clave del bucket. Continúa creando el output_domain.avro con la clave del bucket. Asegúrate de reemplazar
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
La secuencia de comandos crea el archivo output_domain.avro en la carpeta actual.
2.5. Crea informes de resumen con la herramienta de pruebas locales
Usaremos LocalTestingTool_{version}.jar que se descargó en la Sección 1.1 para crear los informes de resumen. Usa el siguiente comando. Debes reemplazar LocalTestingTool_{version}.jar por la versión descargada para LocalTestingTool.
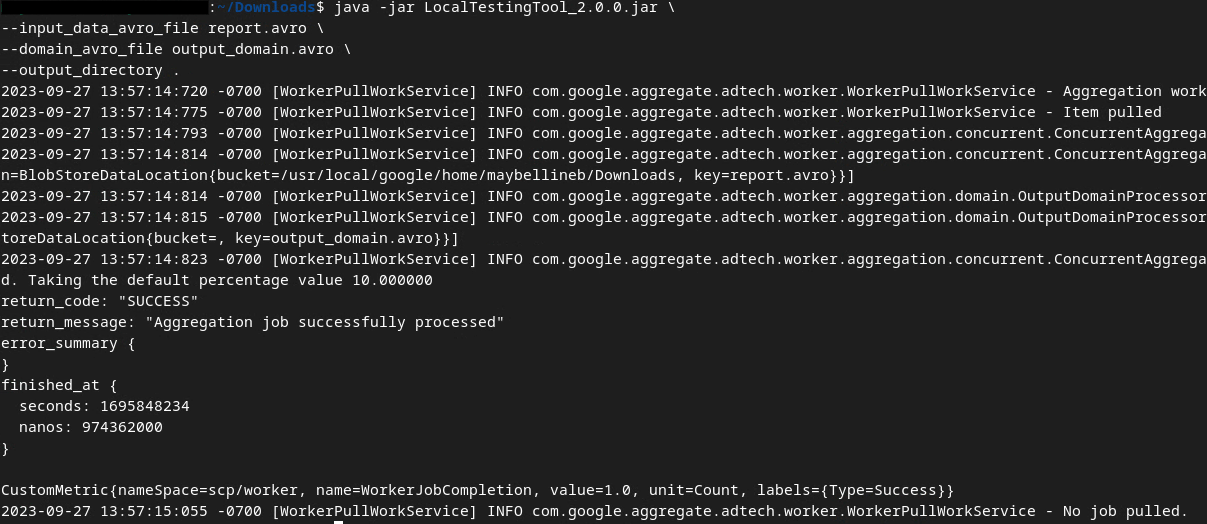
Ejecuta el siguiente comando para generar un informe de resumen en tu entorno de desarrollo local:
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
Deberías ver algo similar a la siguiente imagen una vez que se ejecute el comando. Se crea un informe output.avro una vez que se completa.
2.6. Revisa el informe de resumen
El informe de resumen que se crea está en formato AVRO. Para poder leerlo, debes convertirlo de AVRO a un formato JSON. Idealmente, la tecnología publicitaria debería codificar para convertir los informes de AVRO en JSON.
En nuestro codelab, usaremos la herramienta aggregatable_report_converter.jar proporcionada para volver a convertir el informe AVRO en JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Esto muestra un informe similar a la siguiente imagen. Junto con un informe output.json creado en el mismo directorio.

Abre el archivo JSON en el editor que prefieras para revisar el informe de resumen.
3. Implementación del servicio de agregación
Para implementar el servicio de agregación, sigue estos pasos:
Paso 3: Implementación del servicio de agregación: Implementa el servicio de agregación en AWS
Paso 3.1. Clona el repositorio del servicio de agregación
Paso 3.2. Descarga las dependencias compiladas previamente
Paso 3.3. Crea un entorno de desarrollo
Paso 3.4. Implementa el servicio de agregación
3.1. Clona el repositorio del servicio de agregación
En tu entorno local, clona el repositorio de GitHub del servicio de agregación.
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. Descarga dependencias precompiladas
Una vez que hayas clonado el repositorio del servicio de agregación, ve a la carpeta Terraform del repositorio y a la carpeta de nube correspondiente. Si tu cloud_provider es AWS, puedes continuar con
cd <repository_root>/terraform/aws
En download_prebuilt_dependencies.sh.
bash download_prebuilt_dependencies.sh
3.3. Crea un entorno de desarrollo
Crea un entorno de desarrollo en dev.
mkdir dev
Copia el contenido de la carpeta demo en la carpeta dev.
cp -R demo/* dev
Ve a la carpeta dev.
cd dev
Actualiza el archivo main.tf y presiona i para que input lo edite.
vim main.tf
Quita el comentario del código en el cuadro rojo. Para ello, quita el # y actualiza los nombres del bucket y de la clave.
Para AWS main.tf:
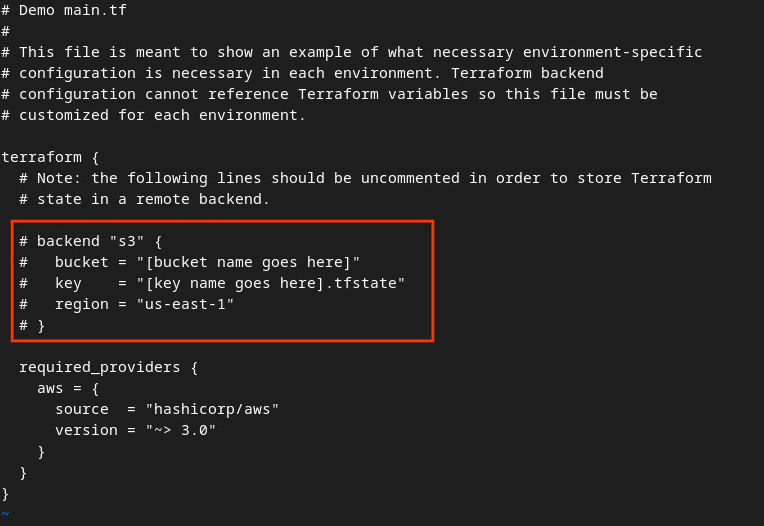
El código sin comentarios debería verse de la siguiente manera.
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
Cuando se completen las actualizaciones, presiónalas para guardarlas y salir del editor: esc -> :wq!. Esto guarda las actualizaciones en main.tf.
A continuación, cambia el nombre de example.auto.tfvars a dev.auto.tfvars.
mv example.auto.tfvars dev.auto.tfvars
Actualiza dev.auto.tfvars y presiona i para que input edite el archivo.
vim dev.auto.tfvars
Actualiza los campos del cuadro rojo de la siguiente imagen con los parámetros de ARN de AWS correctos que se proporcionan durante la integración del servicio de agregación, el entorno y el correo electrónico de notificación.
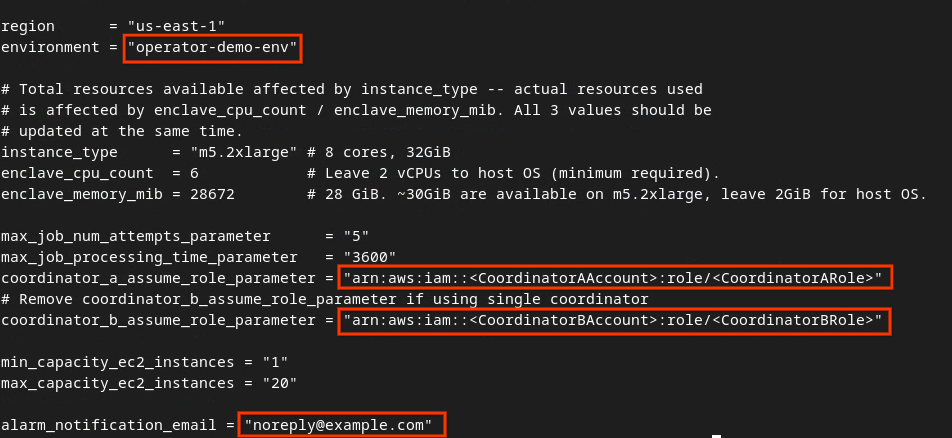
Cuando se completen las actualizaciones, presiona esc -> :wq!. Esto guardará el archivo dev.auto.tfvars y debería verse como la siguiente imagen.
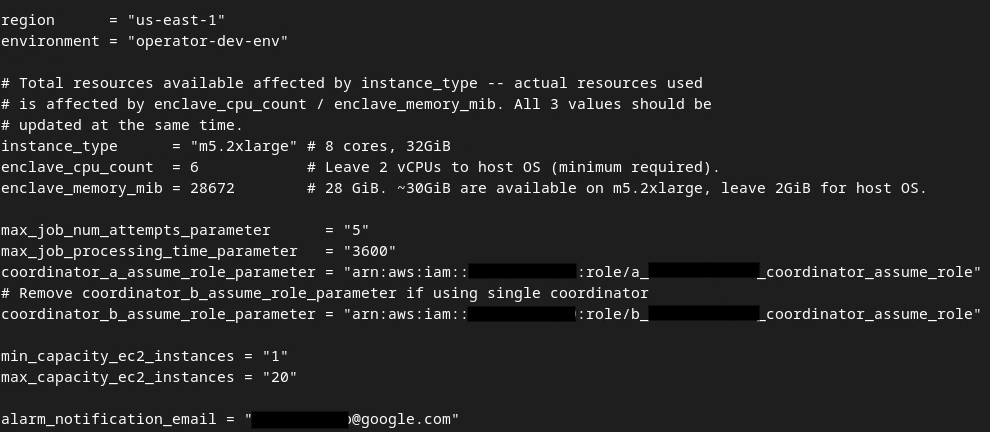
3.4. Implementa el servicio de agregación
Para implementar el servicio de agregación, en la misma carpeta
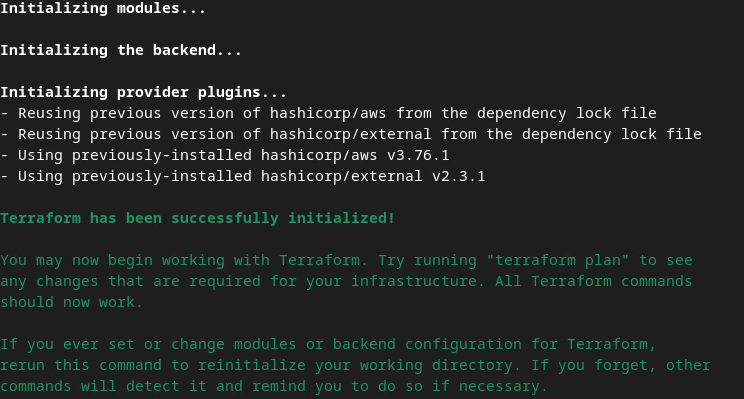
terraform init
Se debería mostrar algo similar a la siguiente imagen:
Una vez que se inicialice Terraform, crea el plan de ejecución de Terraform. Donde se muestra la cantidad de recursos que se agregarán y otra información adicional similar a la siguiente imagen.
terraform plan
A continuación, puedes ver el resumen de "Plan". Si se trata de una implementación nueva, deberías ver la cantidad de recursos que se agregarán con 0 para cambiar y 0 para destruir.
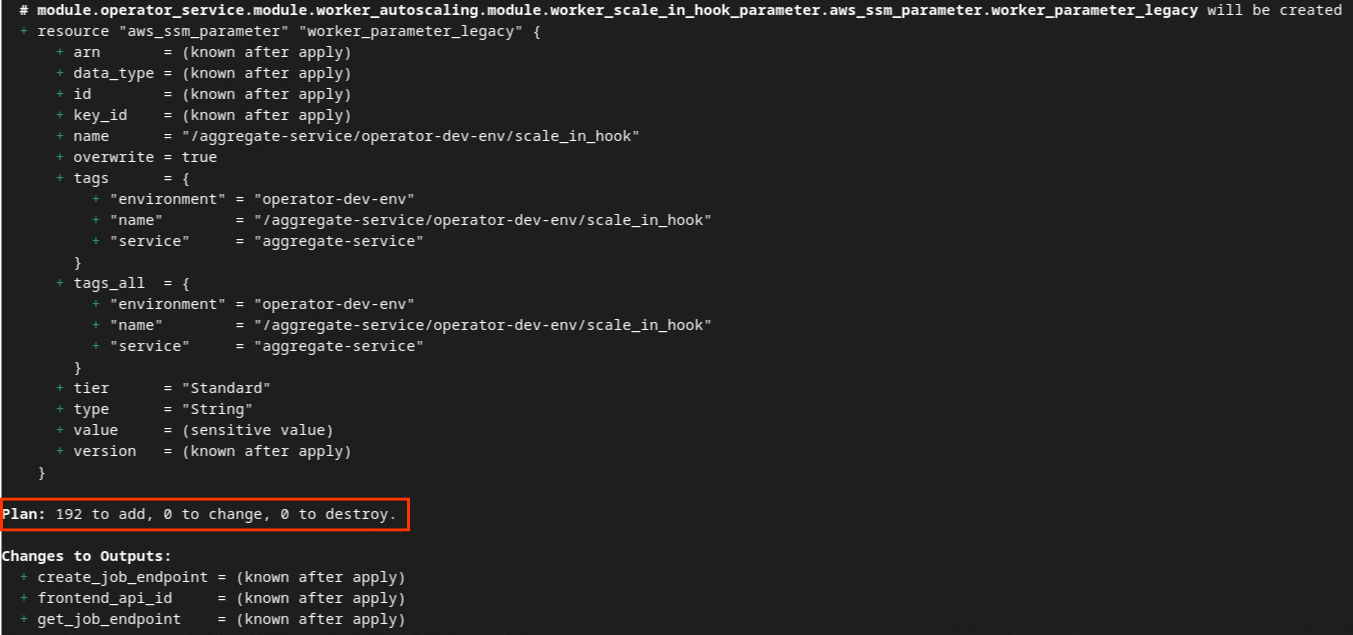
Una vez que completes este paso, podrás aplicar Terraform.
terraform apply
Cuando se te solicite confirmar que Terraform realice las acciones, ingresa un yes en el valor.
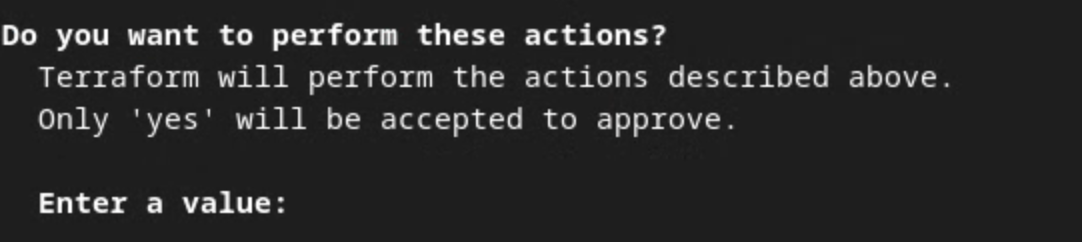
Una vez que finaliza terraform apply, se muestran los siguientes extremos para createJob y getJob. También se muestra el frontend_api_id que debes actualizar en Postman en la sección 1.9.

4. Creación de entradas del servicio de agregación
Continúa con la creación de los informes AVRO para el procesamiento por lotes en el servicio de agregación.
Paso 4: Creación de entradas del servicio de agregación: Crea los informes del servicio de agregación que se agrupan para el servicio de agregación.
Paso 4.1. Informe de activación
Paso 4.2. Recopila informes agregables
Paso 4.3. Convierte los informes a AVRO
Paso 4.4. Crea el dominio de salida AVRO
4.1. Informe de activadores
Ve al sitio de la demo de Privacy Sandbox. Esto activa un informe de agregación privado. Puedes ver el informe en chrome://private-aggregation-internals.
Si tu informe tiene el estado "Pendiente", puedes seleccionarlo y hacer clic en "Enviar informes seleccionados".
4.2. Recopila informes agregables
Recopila tus informes agregables desde los extremos .well-known de tu API correspondiente.
- Private Aggregation
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - Attribution Reporting - Summary Report
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
En este codelab, realizarás la recopilación de informes de forma manual. En producción, se espera que las tecnologías publicitarias recopilen y conviertan los informes de forma programática.
En chrome://private-aggregation-internals, copia el "Cuerpo del informe" que se recibió en el extremo [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
Asegúrate de que, en "Cuerpo del informe", aggregation_coordinator_origin contenga https://publickeyservice.msmt.aws.privacysandboxservices.com, lo que significa que el informe es un informe agregable de AWS.
Coloca el JSON "Report Body" en un archivo JSON. En este ejemplo, puedes usar vim. Sin embargo, puedes usar el editor de texto que quieras.
vim report.json
Pega el informe en report.json y guarda el archivo.
4.3. Convierte informes a AVRO
Los informes recibidos de los extremos .well-known están en formato JSON y deben convertirse al formato de informe AVRO. Una vez que tengas el informe JSON, navega a la carpeta del informe y usa aggregatable_report_converter.jar para crear el informe de depuración agregable. Esto crea un informe agregable llamado report.avro en tu directorio actual.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. Crea el dominio de salida AVRO
Para crear el archivo output_domain.avro, necesitas las claves de bucket que se pueden recuperar de los informes.
La tecnología publicitaria diseña las claves de bucket. Sin embargo, en este caso, el sitio demo de Privacy Sandbox crea las claves de bucket. Dado que la agregación privada para este sitio está en modo de depuración, puedes usar el debug_cleartext_payload del "Cuerpo del informe" para obtener la clave del bucket.
Continúa y copia el debug_cleartext_payload del cuerpo del informe.
Abre goo.gle/ags-payload-decoder, pega tu debug_cleartext_payload en el cuadro "INPUT" y haz clic en "Decode".
La página muestra el valor decimal de la clave del bucket. La siguiente es una clave de bucket de ejemplo.
Ahora que tenemos la clave del bucket, crea el output_domain.avro. Asegúrate de reemplazar
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
La secuencia de comandos crea el archivo output_domain.avro en la carpeta actual.
4.5. Cómo mover informes al bucket de AWS
Una vez que se hayan creado los informes AVRO (de la sección 3.2.3) y el dominio de salida (de la sección 3.2.4), mueve los informes y el dominio de salida a los buckets de S3 de informes.
Si tienes la configuración de AWS CLI en tu entorno local, usa los siguientes comandos para copiar los informes en el bucket de S3 y la carpeta de informes correspondientes.
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. Uso del servicio de agregación
Desde terraform apply, se muestra create_job_endpoint, get_job_endpoint y frontend_api_id. Copia el frontend_api_id y colócalo en la variable global de Postman frontend_api_id que configuraste en la sección de requisitos previos 1.9.
Paso 5: Uso del servicio de agregación: Usa la API de Aggregation Service para crear informes de resumen y revisarlos.
Paso 5.1. Usa el extremo createJob para realizar tareas por lotes
Paso 5.2. Usa el extremo getJob para recuperar el estado del lote
Paso 5.3. Revisa el informe de resumen
5.1. Usa el extremo createJob para realizar tareas por lotes
En Postman, abre la colección "Privacy Sandbox" y selecciona "createJob".
Selecciona "Cuerpo" y "en bruto" para colocar la carga útil de la solicitud.
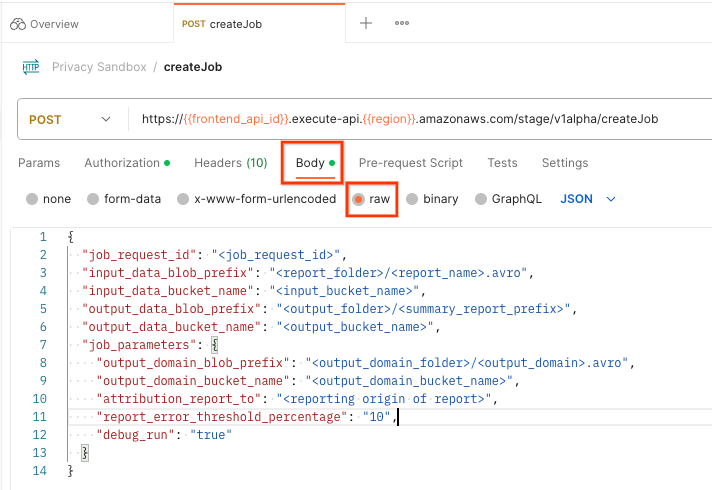
El esquema de carga útil de createJob está disponible en github y es similar al siguiente. Reemplaza <> por los campos adecuados.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Cuando hagas clic en "Enviar", se creará la tarea con el job_request_id. Deberías recibir una respuesta HTTP 202 una vez que el servicio de agregación acepte la solicitud. Puedes encontrar otros códigos de devolución posibles en Códigos de respuesta HTTP.

5.2. Usa el extremo getJob para recuperar el estado del lote
Para verificar el estado de la solicitud de trabajo, puedes usar el extremo getJob. Selecciona "getJob" en la colección "Privacy Sandbox".
En "Params", actualiza el valor de job_request_id al job_request_id que se envió en la solicitud createJob.
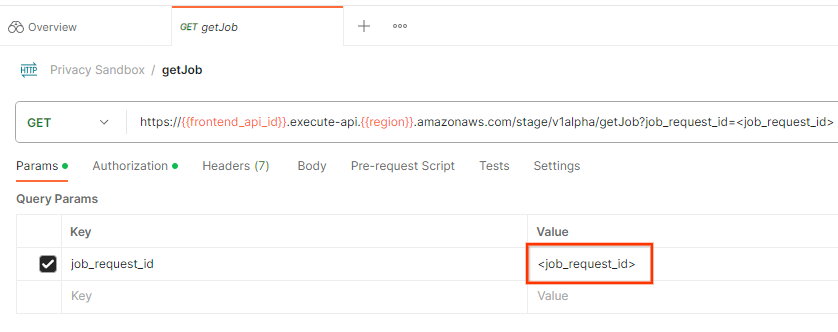
El resultado de getJob debería mostrar el estado de tu solicitud de trabajo con un estado HTTP de 200. El "cuerpo" de la solicitud contiene la información necesaria, como job_status, return_message y error_messages (si la tarea generó un error).
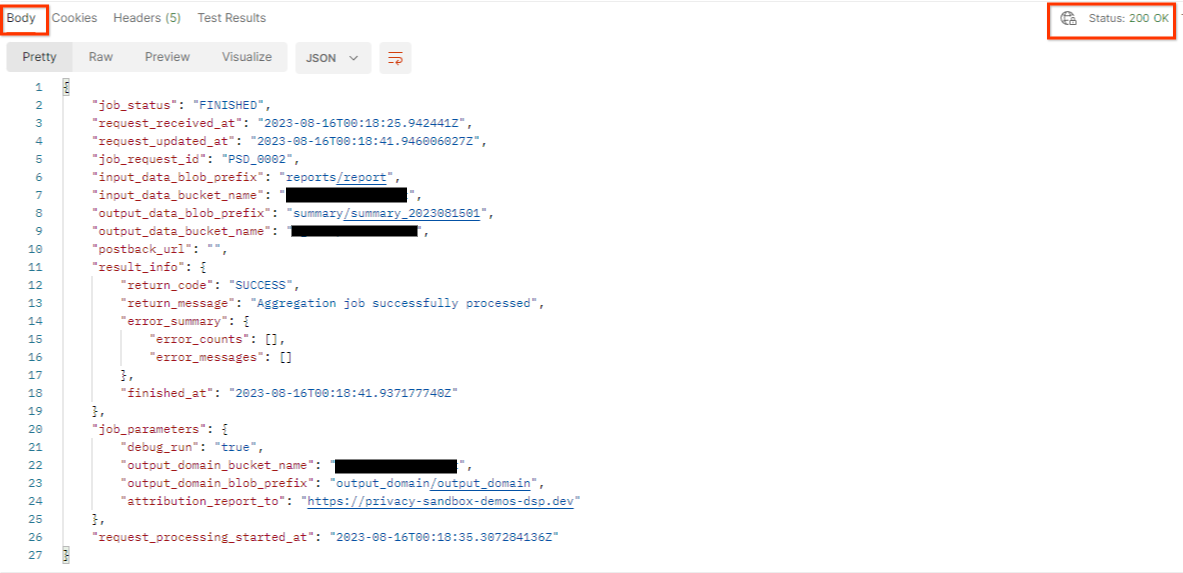
Dado que el sitio de informes del informe de demostración generado es diferente del sitio integrado en tu ID de AWS, es posible que recibas una respuesta con el código de retorno PRIVACY_BUDGET_AUTHORIZATION_ERROR. Esto es normal, ya que el sitio de origen de los informes no coincide con el sitio de informes integrado para el ID de AWS.
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. Revisa el informe de resumen
Una vez que recibas el informe de resumen en tu bucket de S3 de salida, podrás descargarlo en tu entorno local. Los informes de resumen están en formato AVRO y se pueden volver a convertir a JSON. Puedes usar aggregatable_report_converter.jar para leer tu informe con el siguiente comando.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Esto muestra un JSON de valores agregados de cada clave de bucket que se ve similar a la siguiente imagen.

Si tu solicitud de createJob incluye debug_run como true, puedes recibir tu informe de resumen en la carpeta de depuración que se encuentra en output_data_blob_prefix. El informe está en formato AVRO y se puede convertir a JSON con el comando anterior.
El informe contiene la clave del bucket, la métrica sin ruido y el ruido que se agrega a la métrica sin ruido para formar el informe de resumen. El informe es similar a la siguiente imagen.

Las anotaciones también contienen in_reports y in_domain, lo que significa lo siguiente:
- in_reports: La clave de bucket está disponible dentro de los informes agregables.
- in_domain: La clave del bucket está disponible dentro del archivo AVRO output_domain.