
1. Prérequis
Pour suivre cet atelier de programmation, vous devez remplir quelques conditions préalables. Chaque exigence est marquée en conséquence, qu'elle soit requise pour les tests locaux ou pour le service d'agrégation.
1.1. Télécharger l'outil de test local (test local)
Pour effectuer des tests en local, vous devez télécharger l'outil de test en local. L'outil génère des rapports récapitulatifs à partir des rapports de débogage non chiffrés.
L'outil de test local est disponible au téléchargement dans les archives JAR Lambda sur GitHub. Il doit être nommé LocalTestingTool_{version}.jar.
1.2. Vérifier que le JRE JAVA est installé (service d'agrégation et de test local)
Ouvrez Terminal et utilisez java --version pour vérifier si Java ou openJDK est installé sur votre machine.

Si ce n'est pas le cas, vous pouvez le télécharger et l'installer depuis le site Java ou le site openJDK.
1.3. Télécharger le convertisseur de rapports agrégables (service de test et d'agrégation en local)
Vous pouvez télécharger une copie du convertisseur de rapports agrégables à partir du dépôt GitHub des démonstrations de la Privacy Sandbox.
1.4. Activer les API Ad Privacy (service de test et d'agrégation locaux)
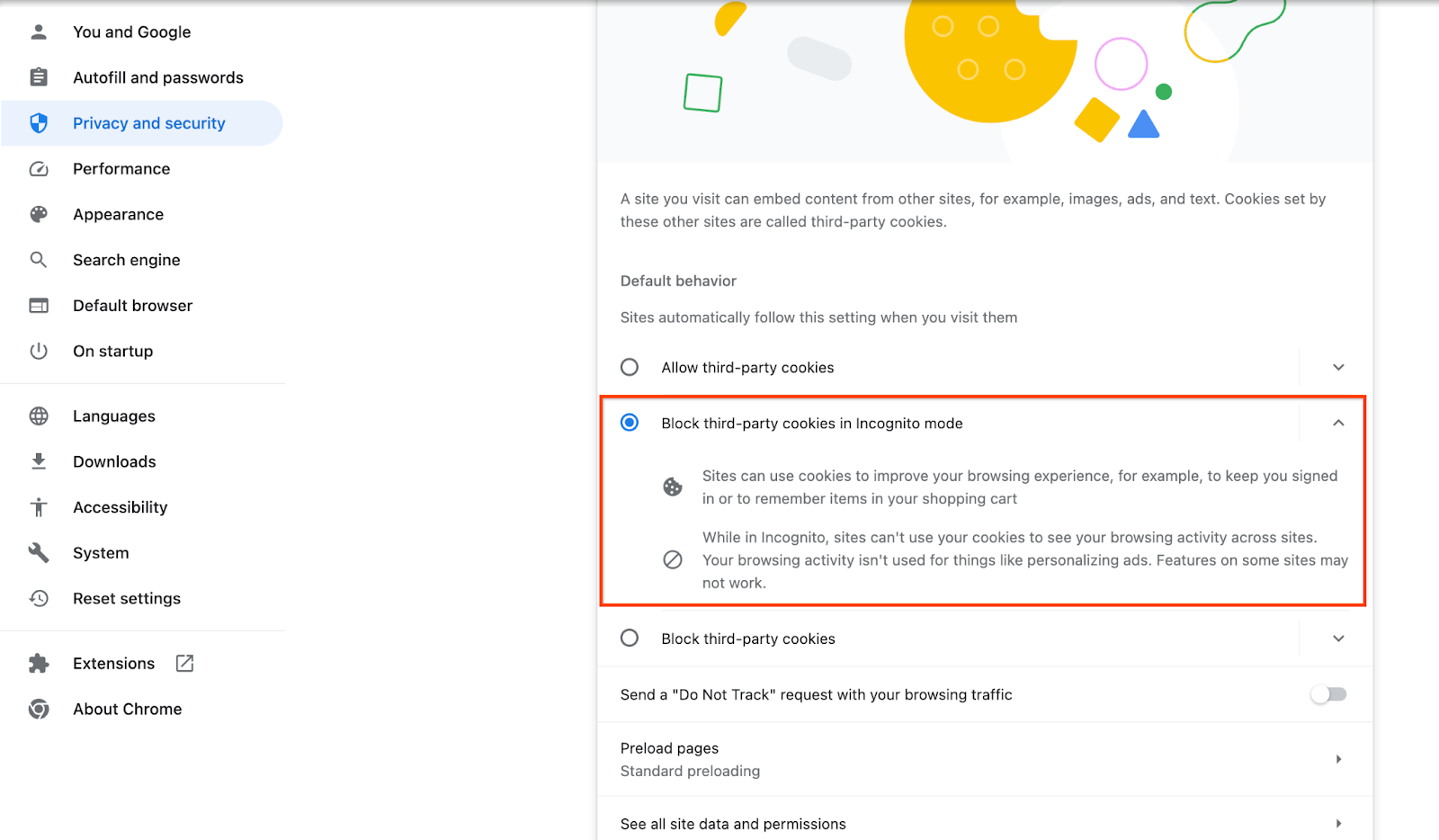
Dans votre navigateur, accédez à chrome://settings/adPrivacy et activez toutes les API Ad Privacy.
Assurez-vous que les cookies tiers sont activés.
Dans votre navigateur, accédez à chrome://settings/cookies, puis sélectionnez Bloquer les cookies tiers en mode navigation privée.
1.5. Inscription sur le Web et sur Android (service d'agrégation)
Pour utiliser les API Privacy Sandbox dans un environnement de production, assurez-vous d'avoir effectué l'inscription et l'attestation pour Chrome et Android.
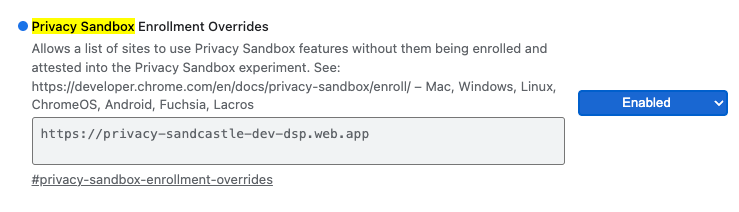
Pour les tests locaux, l'inscription peut être désactivée à l'aide d'un flag Chrome et d'un commutateur de ligne de commande.
Pour utiliser l'option Chrome pour notre démonstration, accédez à chrome://flags/#privacy-sandbox-enrollment-overrides et mettez à jour le forçage avec votre site. Si vous utilisez notre site de démonstration, aucune mise à jour n'est requise.
1.6. Intégration du service d'agrégation (service d'agrégation)
Le service d'agrégation nécessite une intégration aux coordinateurs pour pouvoir l'utiliser. Remplissez le formulaire d'intégration du service d'agrégation en indiquant l'adresse de votre site de création de rapports, votre ID de compte AWS et d'autres informations.
1.7. Fournisseur de services cloud (service d'agrégation)
Le service d'agrégation nécessite l'utilisation d'un environnement d'exécution sécurisé qui utilise un environnement cloud. Le service d'agrégation est compatible avec Amazon Web Services (AWS) et Google Cloud (GCP). Cet atelier de programmation ne concerne que l'intégration d'AWS.
AWS fournit un environnement d'exécution sécurisé appelé Nitro Enclaves. Assurez-vous de disposer d'un compte AWS, puis suivez les instructions d'installation et de mise à jour de la CLI AWS pour configurer votre environnement CLI AWS.
Si votre CLI AWS est nouvelle, vous pouvez la configurer à l'aide des instructions de configuration de la CLI.
1.7.1. Créer un bucket AWS S3
Créez un bucket AWS S3 pour stocker l'état Terraform et un autre bucket S3 pour stocker vos rapports et rapports récapitulatifs. Vous pouvez utiliser la commande CLI fournie. Remplacez le champ dans <> par les variables appropriées.
aws s3api create-bucket --bucket <tf_bucket_name> --region us-east-1
aws s3api create-bucket --bucket <report_bucket_name> --region us-east-1
1.7.2. Créer une clé d'accès utilisateur
Créez des clés d'accès utilisateur à l'aide du guide AWS. Il servira à appeler les points de terminaison d'API createJob et getJob créés sur AWS.
1.7.3. Autorisations des utilisateurs et des groupes AWS
Pour déployer le service d'agrégation sur AWS, vous devez accorder certaines autorisations à l'utilisateur qui a déployé le service. Pour cet atelier de programmation, assurez-vous que l'utilisateur dispose d'un accès administrateur pour disposer de toutes les autorisations de déploiement.
1.8. Terraform (service d'agrégation)
Cet atelier de programmation utilise Terraform pour déployer le service d'agrégation. Assurez-vous que le binaire Terraform est installé dans votre environnement local.
Téléchargez le binaire Terraform dans votre environnement local.
Une fois le binaire Terraform téléchargé, extrayez le fichier et déplacez-le dans /usr/local/bin.
cp <directory>/terraform /usr/local/bin
Vérifiez que Terraform est disponible dans le chemin d'accès aux classes.
terraform -v
1.9. Postman (pour le service d'agrégation AWS)
Pour cet atelier de programmation, utilisez Postman pour la gestion des requêtes.
Pour créer un espace de travail, accédez à l'élément de navigation supérieur Espaces de travail, puis sélectionnez Créer un espace de travail.
Sélectionnez Espace de travail vide, cliquez sur "Suivant", puis nommez-le Privacy Sandbox. Sélectionnez Personnel, puis cliquez sur Créer.
Téléchargez les fichiers de configuration JSON et d'environnement global de l'espace de travail préconfiguré.
Importez les fichiers JSON dans Mon espace de travail à l'aide du bouton Importer.

La collection Privacy Sandbox sera créée pour vous, ainsi que les requêtes HTTP createJob et getJob.
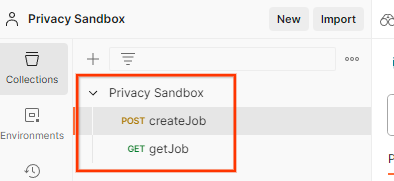
Mettez à jour la "Clé d'accès " et la"Clé secrète " AWS via Aperçu rapide de l'environnement.
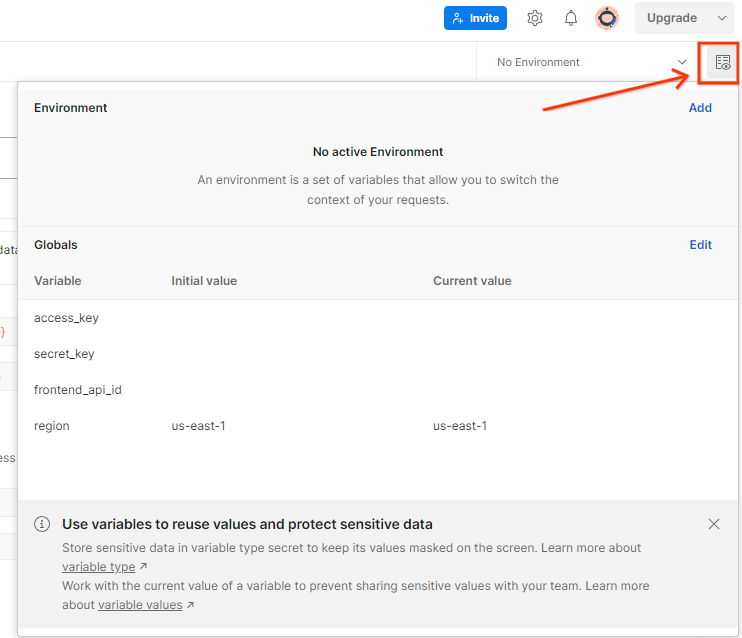
Cliquez sur Modifier, puis mettez à jour la valeur actuelle de access_key et de secret_key. Notez que frontend_api_id sera fourni dans la section 3.1.4 de ce document. Nous vous recommandons d'utiliser la région us-east-1. Toutefois, si vous souhaitez effectuer un déploiement dans une autre région, veillez à copier l'AMI publiée dans votre compte ou à effectuer un build personnalisé à l'aide des scripts fournis.

2. Atelier de programmation sur les tests en local
Vous pouvez utiliser l'outil de test local sur votre ordinateur pour effectuer une agrégation et générer des rapports récapitulatifs à l'aide des rapports de débogage non chiffrés.
Étapes de l'atelier de programmation
Étape 2.1. Déclencher le rapport: déclenchez les rapports d'agrégation privée pour pouvoir les collecter.
Étape 2.2. Créer un rapport agrégable de débogage: convertissez le rapport JSON collecté en un rapport au format AVRO.
Cette étape est semblable à celle où les technologies publicitaires collectent les rapports à partir des points de terminaison de création de rapports de l'API et convertissent les rapports JSON en rapports au format AVRO.
Étape 2.3. Analyser la clé de bucket à partir du rapport de débogage: les clés de bucket sont conçues par les technologies publicitaires. Dans cet atelier de programmation, étant donné que les buckets sont prédéfinis, récupérez les clés de bucket telles que fournies.
Étape 2.4. Créer le fichier AVRO du domaine de sortie: une fois les clés de bucket récupérées, créez le fichier AVRO du domaine de sortie.
Étape 2.5. Créer des rapports récapitulatifs à l'aide de l'outil de test local: utilisez l'outil de test local pour créer des rapports récapitulatifs dans l'environnement local.
Étape 2.6. Examinez le rapport récapitulatif: examinez le rapport récapitulatif créé par l'outil de test local.
2.1. Rapport sur les déclencheurs
Accédez au site de la démo de la Privacy Sandbox. Cela déclenche un rapport d'agrégation privé. Vous pouvez consulter le rapport sur chrome://private-aggregation-internals.
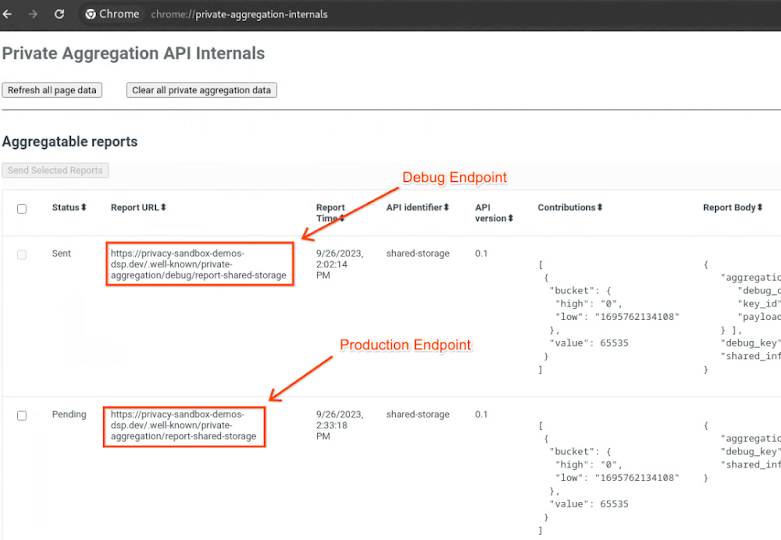
Si votre rapport est en attente, vous pouvez le sélectionner, puis cliquer sur Envoyer les rapports sélectionnés.
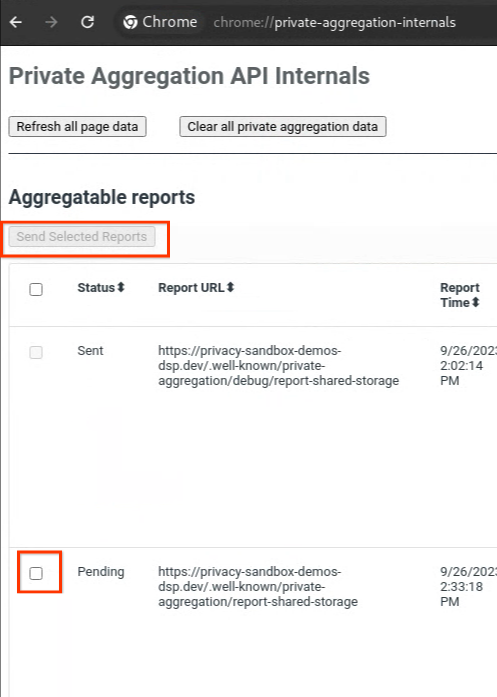
2.2. Créer un rapport agrégable de débogage
Dans chrome://private-aggregation-internals, copiez le corps du rapport reçu dans le point de terminaison [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
Dans le champ Body (Corps du rapport), assurez-vous que aggregation_coordinator_origin contient https://publickeyservice.msmt.aws.privacysandboxservices.com, ce qui signifie que le rapport est un rapport AWS agrégable.
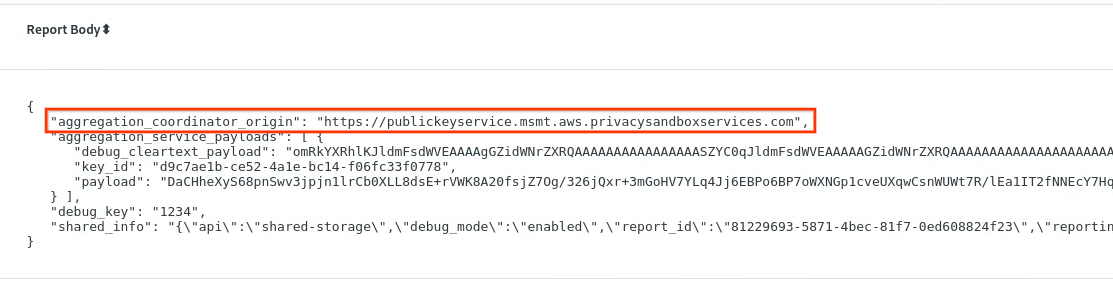
Placez le corps du rapport JSON dans un fichier JSON. Dans cet exemple, vous pouvez utiliser vim. Vous pouvez toutefois utiliser l'éditeur de texte de votre choix.
vim report.json
Collez le rapport dans report.json et enregistrez le fichier.

Accédez ensuite à votre dossier de rapports et utilisez aggregatable_report_converter.jar pour créer le rapport de débogage agrégable. Un rapport agrégable nommé report.avro est alors créé dans votre répertoire actuel.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Analyser la clé de bucket à partir du rapport de débogage
Le service d'agrégation nécessite deux fichiers lors de l'agrégation. Le rapport agrégable et le fichier de domaine de sortie. Le fichier de domaine de sortie contient les clés que vous souhaitez récupérer à partir des rapports agrégables. Pour créer le fichier output_domain.avro, vous avez besoin des clés de bucket qui peuvent être récupérées dans les rapports.
Les clés de bucket sont conçues par l'appelant de l'API. La démonstration contient des exemples de clés de bucket prédéfinies. Étant donné que la démonstration a activé le mode débogage pour l'agrégation privée, vous pouvez analyser la charge utile en texte clair de débogage à partir du corps du rapport pour récupérer la clé de bucket. Toutefois, dans ce cas, la démonstration de la Privacy Sandbox du site crée les clés de bucket. Étant donné que l'agrégation privée pour ce site est en mode débogage, vous pouvez utiliser debug_cleartext_payload dans le corps du rapport pour obtenir la clé de bucket.
Copiez l'debug_cleartext_payload à partir du corps du rapport.

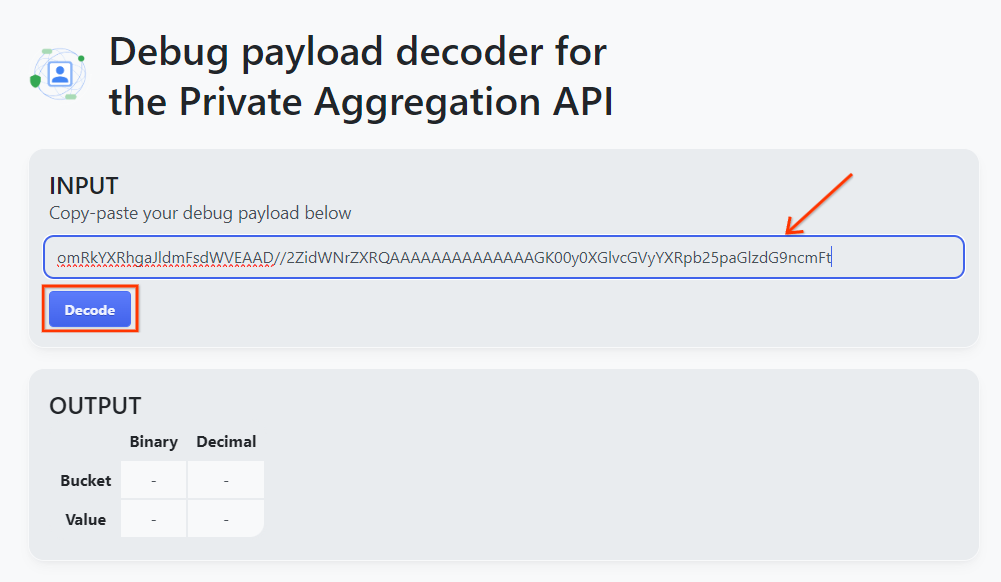
Ouvrez l'outil Debug payload decoder for Private Aggregation (Décodeur de charge utile de débogage pour l'agrégation privée), collez votre debug_cleartext_payload dans le champ INPUT (ENTRÉE), puis cliquez sur Decode (Décoder).
La page renvoie la valeur décimale de la clé de bucket. Voici un exemple de clé de bucket.
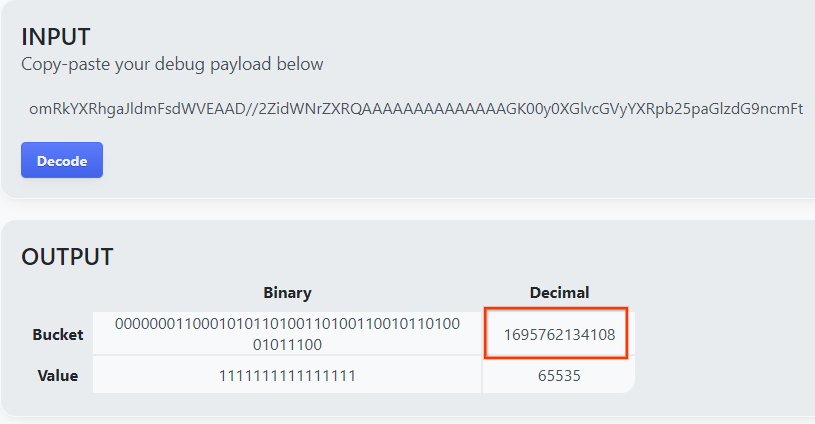
2.4. Créer le domaine de sortie AVRO
Maintenant que nous avons la clé de bucket, copiez la valeur décimale de la clé de bucket. Créez l'output_domain.avro à l'aide de la clé du bucket. Veillez à remplacer
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Le script crée le fichier output_domain.avro dans votre dossier actuel.
2.5. Créer des rapports récapitulatifs à l'aide de l'outil de test local
Nous utiliserons LocalTestingTool_{version}.jar, téléchargé dans la section 1.1, pour créer les rapports récapitulatifs. Utilisez la commande suivante. Vous devez remplacer LocalTestingTool_{version}.jar par la version téléchargée pour LocalTestingTool.
Exécutez la commande suivante pour générer un rapport récapitulatif dans votre environnement de développement local:
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
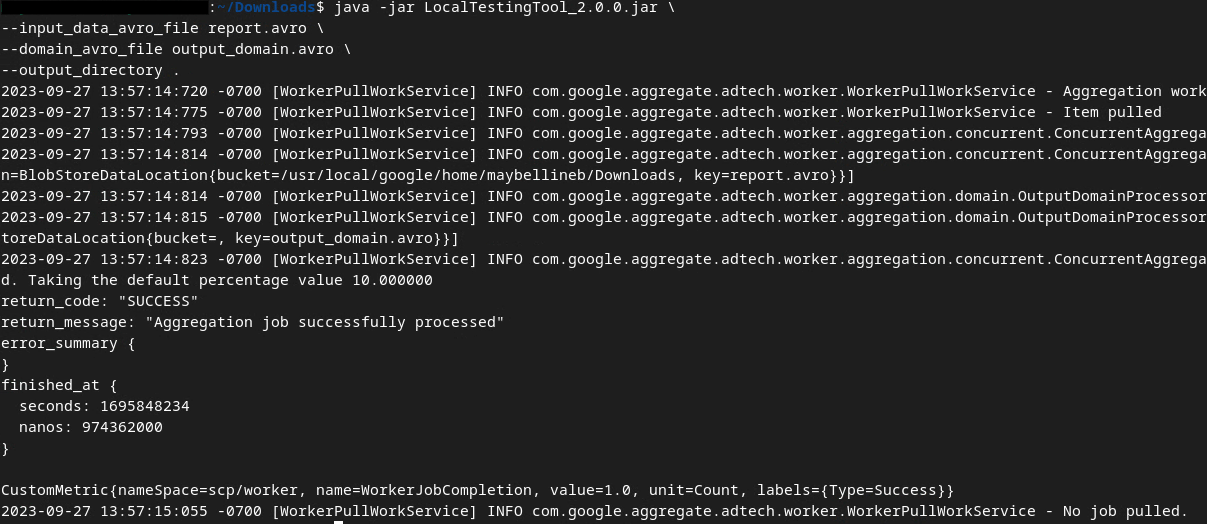
Une image semblable à celle-ci devrait s'afficher une fois la commande exécutée. Un rapport output.avro est créé une fois l'opération terminée.
2.6. Examiner le rapport récapitulatif
Le rapport récapitulatif créé est au format AVRO. Pour pouvoir le lire, vous devez le convertir du format AVRO au format JSON. Idéalement, la technologie publicitaire doit être codée pour convertir les rapports AVRO en JSON.
Pour cet atelier de programmation, nous utiliserons l'outil aggregatable_report_converter.jar fourni pour convertir le rapport AVRO en JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Un rapport semblable à l'image suivante s'affiche. ainsi qu'un fichier output.json de rapport créé dans le même répertoire.

Ouvrez le fichier JSON dans l'éditeur de votre choix pour consulter le rapport récapitulatif.
3. Déploiement du service d'agrégation
Pour déployer le service d'agrégation, procédez comme suit:
Étape 3 : Déploiement du service d'agrégation: déployez le service d'agrégation sur AWS
Étape 3.1. Cloner le dépôt du service d'agrégation
Étape 3.2. Télécharger les dépendances prédéfinies
Étape 3.3. Créer un environnement de développement
Étape 3.4. Déployer le service d'agrégation
3.1. Cloner le dépôt du service d'agrégation
Dans votre environnement local, clonez le dépôt GitHub du service d'agrégation.
git clone https://github.com/privacysandbox/aggregation-service.git
3.2. Télécharger les dépendances prédéfinies
Une fois le dépôt du service d'agrégation cloné, accédez au dossier Terraform du dépôt et au dossier cloud correspondant. Si votre cloud_provider est AWS, vous pouvez passer à
cd <repository_root>/terraform/aws
Dans download_prebuilt_dependencies.sh.
bash download_prebuilt_dependencies.sh
3.3. Créer un environnement de développement
Créez un environnement de développement dans dev.
mkdir dev
Copiez le contenu du dossier demo dans le dossier dev.
cp -R demo/* dev
Accédez à votre dossier dev.
cd dev
Mettez à jour votre fichier main.tf et appuyez sur i pour que input le modifie.
vim main.tf
Supprimez le symbole # pour annuler la mise en commentaire du code dans le cadre rouge, puis modifiez les noms du bucket et de la clé.
Pour le fichier main.tf AWS:
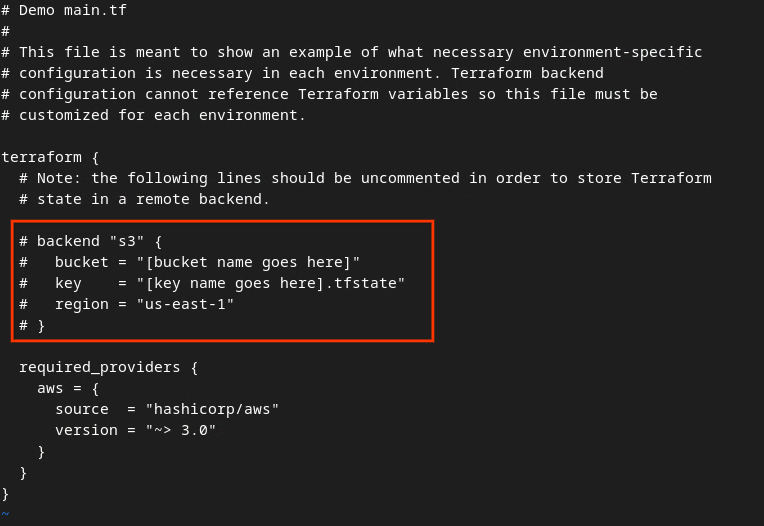
Le code sans commentaire doit se présenter comme suit.
backend "s3" {
bucket = "<tf_state_bucket_name>"
key = "<environment_name>.tfstate"
region = "us-east-1"
}
Une fois les modifications effectuées, enregistrez-les et quittez l'éditeur en appuyant sur esc -> :wq!. Les mises à jour sont ainsi enregistrées sur main.tf.
Renommez ensuite example.auto.tfvars en dev.auto.tfvars.
mv example.auto.tfvars dev.auto.tfvars
Mettez à jour dev.auto.tfvars et appuyez sur i pour que input modifie le fichier.
vim dev.auto.tfvars
Remplacez les champs du cadre rouge de l'image suivante par les paramètres ARN AWS appropriés fournis lors de l'intégration du service d'agrégation, de l'environnement et de l'e-mail de notification.
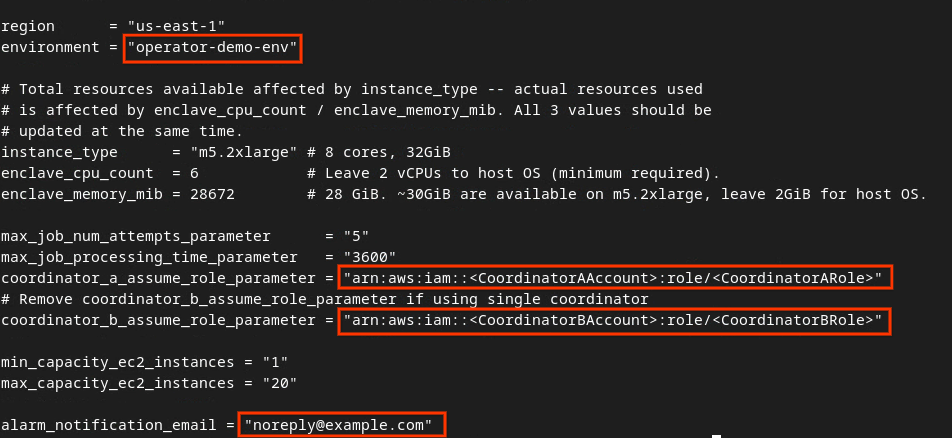
Une fois les mises à jour effectuées, appuyez sur esc -> :wq!. Le fichier dev.auto.tfvars est ainsi enregistré et devrait se présenter comme l'image ci-dessous.
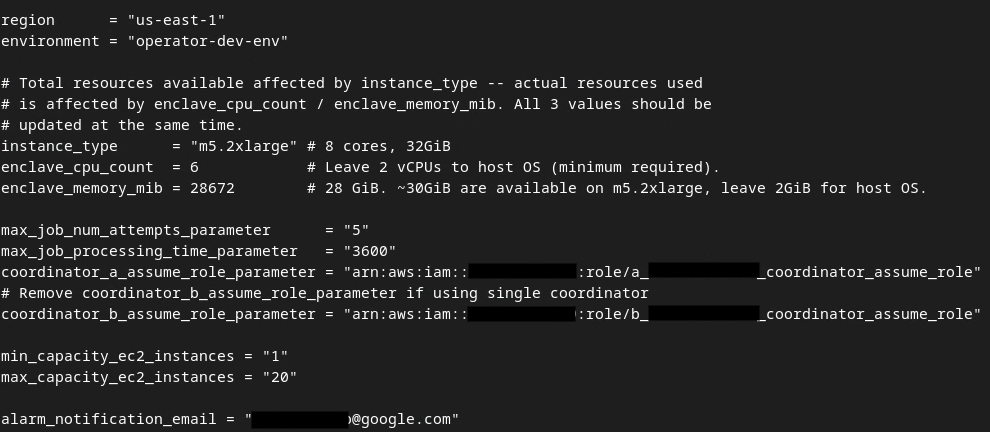
3.4. Déployer le service d'agrégation
Pour déployer le service d'agrégation, dans le même dossier
terraform init
Vous devriez obtenir un résultat semblable à l'image suivante:
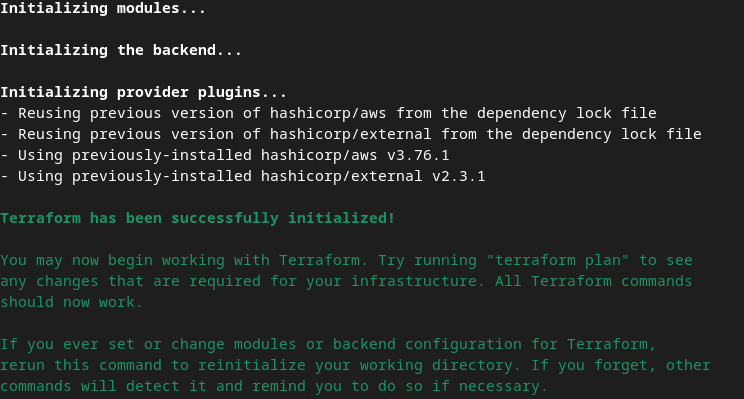
Une fois Terraform initialisé, créez le plan d'exécution Terraform. Elle renvoie le nombre de ressources à ajouter et d'autres informations supplémentaires semblables à l'image suivante.
terraform plan
Vous pouvez voir ci-dessous le récapitulatif "Plan". S'il s'agit d'un nouveau déploiement, le nombre de ressources à ajouter devrait s'afficher, avec 0 pour les modifications et 0 pour les destructions.
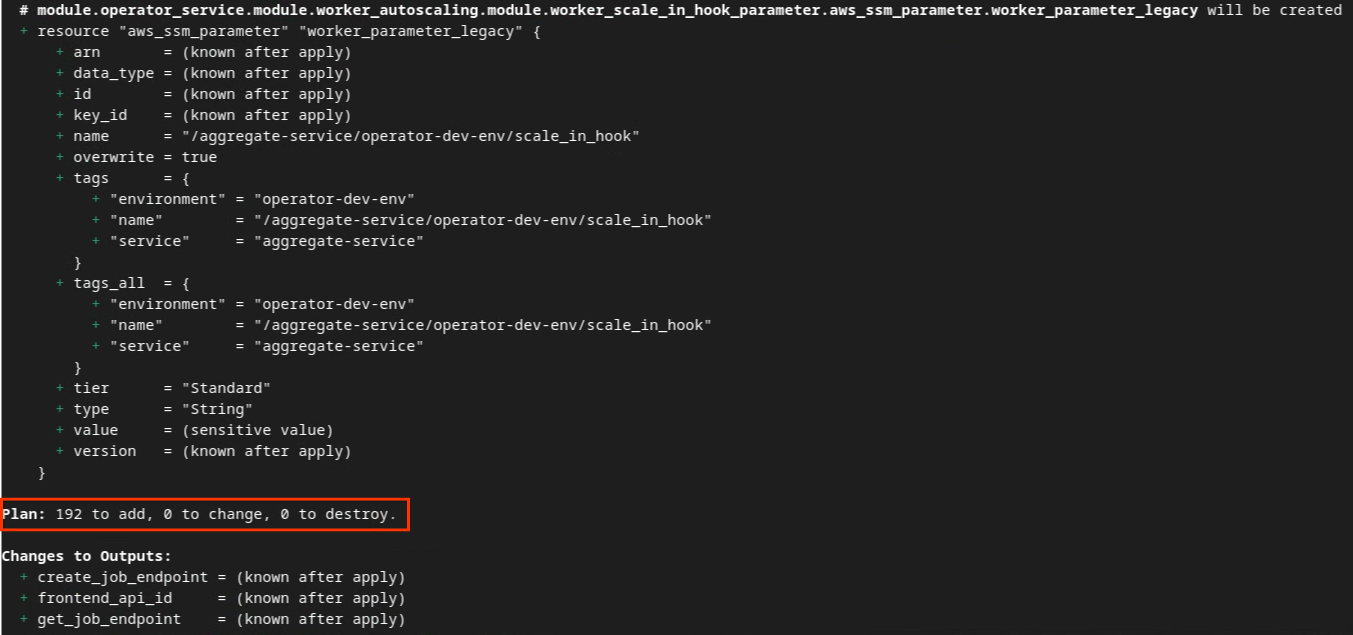
Une fois cette étape terminée, vous pouvez appliquer Terraform.
terraform apply
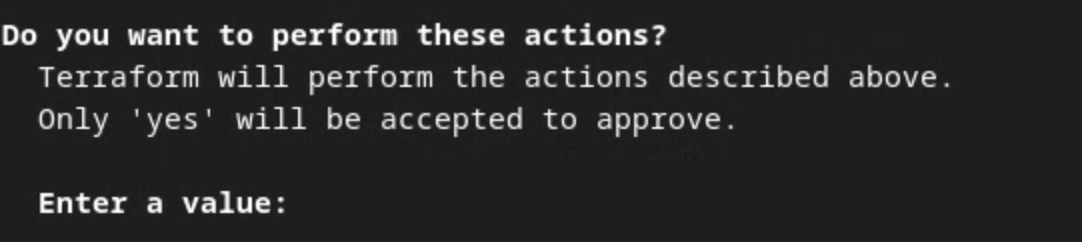
Lorsque vous êtes invité à confirmer l'exécution des actions par Terraform, saisissez yes dans la valeur.
Une fois terraform apply terminé, les points de terminaison suivants pour createJob et getJob sont renvoyés. Le frontend_api_id que vous devez mettre à jour dans Postman dans la section 1.9 est également renvoyé.

4. Création d'entrées pour le service d'agrégation
Créez les rapports AVRO pour le traitement par lot dans le service d'agrégation.
Étape 4 : Création d'entrées pour le service d'agrégation: créez les rapports du service d'agrégation qui sont groupés pour le service d'agrégation.
Étape 4.1. Déclencher un rapport
Étape 4.2. Collecter des rapports agrégables
Étape 4.3 Convertir les rapports au format AVRO
Étape 4.4. Créer le domaine de sortie AVRO
4.1. Rapport sur les déclencheurs
Accédez au site de démonstration de la Privacy Sandbox. Cela déclenche un rapport d'agrégation privé. Vous pouvez consulter le rapport sur chrome://private-aggregation-internals.
Si votre rapport est en attente, vous pouvez le sélectionner, puis cliquer sur Envoyer les rapports sélectionnés.
4.2. Collecter des rapports agrégables
Collectez vos rapports agrégables à partir des points de terminaison .well-known de votre API correspondante.
- Private Aggregation
[reporting-origin] /.well-known/private-aggregation/report-shared-storage - Attribution Reporting – Rapport récapitulatif
[reporting-origin] /.well-known/attribution-reporting/report-aggregate-attribution
Pour cet atelier de programmation, vous allez collecter les rapports manuellement. En production, les technologies publicitaires doivent collecter et convertir les rapports de manière programmatique.
Dans chrome://private-aggregation-internals, copiez le corps du rapport reçu dans le point de terminaison [reporting-origin]/.well-known/private-aggregation/report-shared-storage.
Dans le champ Body (Corps du rapport), assurez-vous que aggregation_coordinator_origin contient https://publickeyservice.msmt.aws.privacysandboxservices.com, ce qui signifie que le rapport est un rapport AWS agrégable.
Placez le corps du rapport JSON dans un fichier JSON. Dans cet exemple, vous pouvez utiliser vim. Vous pouvez toutefois utiliser l'éditeur de texte de votre choix.
vim report.json
Collez le rapport dans report.json et enregistrez le fichier.
4.3. Convertir des rapports au format AVRO
Les rapports reçus des points de terminaison .well-known sont au format JSON et doivent être convertis au format AVRO. Une fois que vous avez le rapport JSON, accédez à votre dossier de rapports et utilisez aggregatable_report_converter.jar pour créer le rapport de débogage agrégable. Un rapport agrégable nommé report.avro est alors créé dans votre répertoire actuel.
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
4.4. Créer le domaine de sortie AVRO
Pour créer le fichier output_domain.avro, vous avez besoin des clés de bucket qui peuvent être récupérées dans les rapports.
Les clés de bucket sont conçues par la technologie publicitaire. Toutefois, dans ce cas, le site Démo de la Privacy Sandbox crée les clés de bucket. Étant donné que l'agrégation privée pour ce site est en mode débogage, vous pouvez utiliser debug_cleartext_payload dans le corps du rapport pour obtenir la clé de bucket.
Copiez l'debug_cleartext_payload dans le corps du rapport.
Ouvrez goo.gle/ags-payload-decoder, collez votre debug_cleartext_payload dans la zone INPUT (ENTRÉE), puis cliquez sur Decode (Décoder).
La page renvoie la valeur décimale de la clé de bucket. Voici un exemple de clé de bucket.
Maintenant que nous avons la clé du bucket, créons le output_domain.avro. Veillez à remplacer
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Le script crée le fichier output_domain.avro dans votre dossier actuel.
4.5. Déplacer des rapports vers un bucket AWS
Une fois les rapports AVRO (de la section 3.2.3) et le domaine de sortie (de la section 3.2.4) créés, déplacez-les dans les buckets S3 de création de rapports.
Si vous avez configuré AWS CLI dans votre environnement local, utilisez les commandes suivantes pour copier les rapports dans le bucket S3 et le dossier de rapports correspondants.
aws s3 cp report.avro s3://<report_bucket_name>/<report_folder>/
aws s3 cp output_domain.avro s3://<report_bucket_name>/<output_domain_folder>/
5. Utilisation du service d'agrégation
À partir de terraform apply, vous obtenez create_job_endpoint, get_job_endpoint et frontend_api_id. Copiez frontend_api_id et placez-le dans la variable globale Postman frontend_api_id que vous avez configurée dans la section préalable 1.9.
Étape 5. Utilisation du service d'agrégation: utilisez l'API du service d'agrégation pour créer et consulter des rapports récapitulatifs.
Étape 5.1. Utiliser le point de terminaison createJob pour effectuer des tâches par lot
Étape 5.2. Utiliser le point de terminaison getJob pour récupérer l'état d'un lot
Étape 5.3. Examiner le rapport récapitulatif
5.1. Utiliser le point de terminaison createJob pour effectuer des lots
Dans Postman, ouvrez la collection Privacy Sandbox (Privacy Sandbox) et sélectionnez createJob (créer une tâche).
Sélectionnez Body (Corps) et raw (Brut) pour placer la charge utile de votre requête.
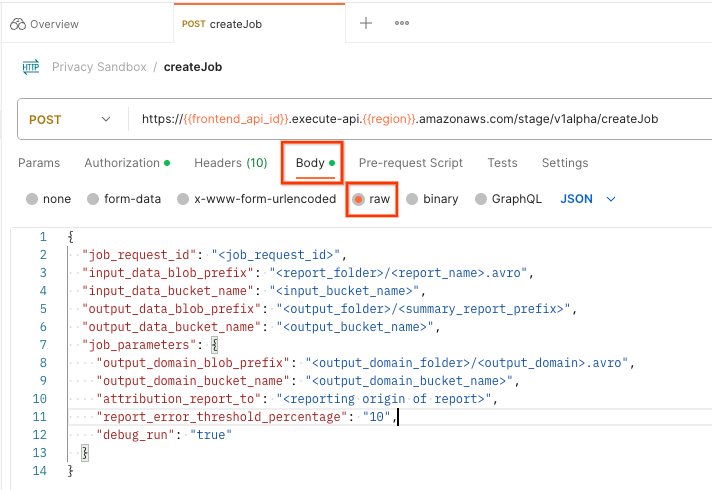
Le schéma de charge utile createJob est disponible sur github et ressemble à ce qui suit. Remplacez <> par les champs appropriés.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Lorsque vous cliquez sur Envoyer, la tâche est créée avec l'job_request_id. Vous devriez recevoir une réponse HTTP 202 une fois la requête acceptée par le service d'agrégation. Vous trouverez d'autres codes de retour possibles dans la section Codes de réponse HTTP.

5.2. Utiliser le point de terminaison getJob pour récupérer l'état du lot
Pour vérifier l'état de la demande de tâche, vous pouvez utiliser le point de terminaison getJob. Sélectionnez getJob dans la collection Privacy Sandbox.
Dans Params (Paramètres), remplacez la valeur job_request_id par l'job_request_id envoyé dans la requête createJob.
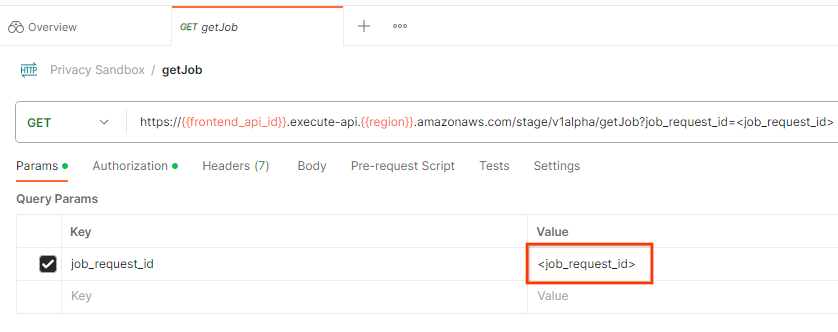
Le résultat de getJob doit renvoyer l'état de votre requête de tâche avec un état HTTP de 200. Le corps de la requête contient les informations nécessaires, telles que job_status, return_message et error_messages (si la tâche a généré une erreur).
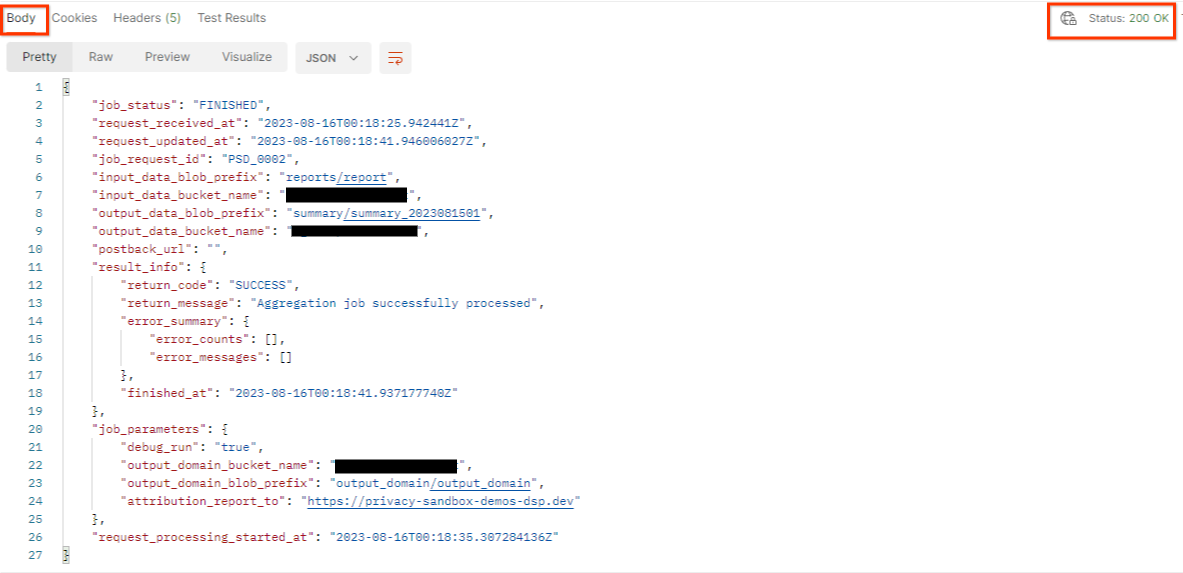
Étant donné que le site de création de rapports du rapport de démonstration généré est différent de celui de votre site intégré à votre ID AWS, vous pouvez recevoir une réponse avec le code de retour PRIVACY_BUDGET_AUTHORIZATION_ERROR. Cela est normal, car le site de l'origine des rapports ne correspond pas au site de création de rapports intégré pour l'ID AWS.
{
"job_status": "FINISHED",
"request_received_at": "2023-12-07T22:50:58.830956Z",
"request_updated_at": "2023-12-07T22:51:10.526326456Z",
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"postback_url": "",
"result_info": {
"return_code": "PRIVACY_BUDGET_AUTHORIZATION_ERROR",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-12-07T22:51:10.517730898Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"attribution_report_to": "https://privacy-sandbox-demos-dsp.dev",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
},
"request_processing_started_at": "2023-12-07T22:51:06.034472697Z"
}
5.3. Examiner le rapport récapitulatif
Une fois que vous avez reçu votre rapport récapitulatif dans votre bucket S3 de sortie, vous pouvez le télécharger dans votre environnement local. Les rapports récapitulatifs sont au format AVRO et peuvent être convertis en JSON. Vous pouvez utiliser aggregatable_report_converter.jar pour lire votre rapport à l'aide de la commande suivante.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Cette opération renvoie un JSON des valeurs agrégées de chaque clé de bucket, qui ressemble à l'image suivante.

Si votre requête createJob inclut debug_run en tant que true, vous pouvez recevoir votre rapport récapitulatif dans le dossier de débogage situé dans output_data_blob_prefix. Le rapport est au format AVRO et peut être converti en JSON à l'aide de la commande précédente.
Le rapport contient la clé de bucket, la métrique non bruitée et le bruit ajouté à la métrique non bruitée pour former le rapport récapitulatif. Le rapport ressemble à l'image suivante.

Les annotations contiennent également in_reports et in_domain, ce qui signifie:
- in_reports : la clé de bucket est disponible dans les rapports agrégables.
- in_domain : la clé du bucket est disponible dans le fichier AVRO output_domain.