
1. 1. Предварительные условия
Примерное время выполнения: 1-2 часа
Существует 2 режима выполнения этой кодовой лаборатории: локальное тестирование или служба агрегации . Для режима локального тестирования требуется локальный компьютер и браузер Chrome (без создания/использования ресурсов Google Cloud). Режим службы агрегации требует полного развертывания службы агрегации в Google Cloud.
Для выполнения этой лабораторной работы в любом режиме необходимо выполнить несколько предварительных условий. Каждое требование помечается соответствующим образом, требуется ли оно для локального тестирования или службы агрегации.
1.1. Полная регистрация и аттестация (служба агрегации)
Чтобы использовать API-интерфейсы Privacy Sandbox, убедитесь, что вы завершили регистрацию и аттестацию как для Chrome, так и для Android.
1.2. Включить API конфиденциальности рекламы (служба локального тестирования и агрегирования)
Поскольку мы будем использовать Privacy Sandbox, мы рекомендуем вам включить рекламные API Privacy Sandbox.
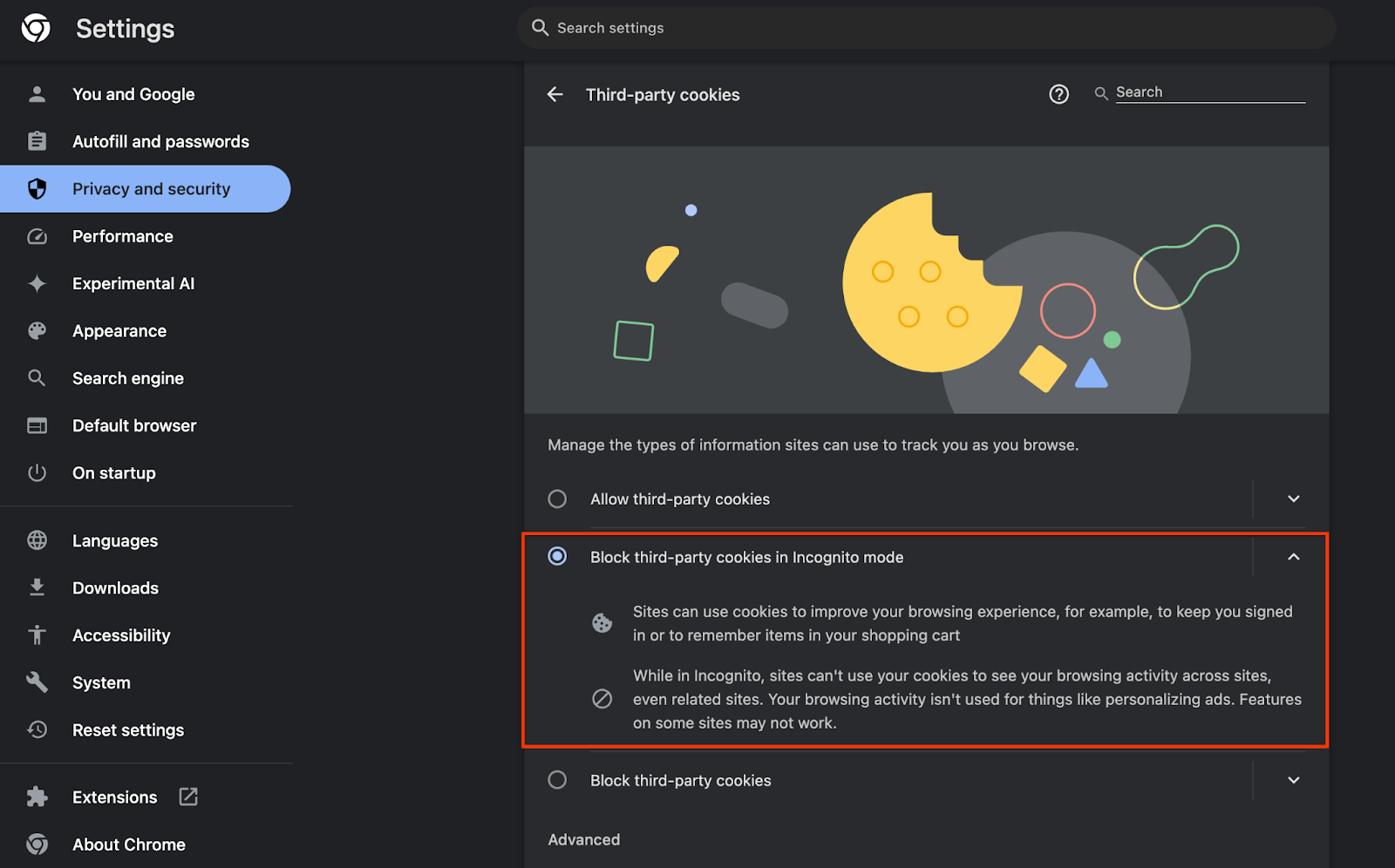
В браузере перейдите по адресу chrome://settings/adPrivacy и включите все API конфиденциальности рекламы.
Также убедитесь, что сторонние файлы cookie включены .
В chrome://settings/cookies убедитесь, что сторонние файлы cookie НЕ блокируются. В зависимости от вашей версии Chrome вы можете увидеть разные параметры в этом меню настроек, но приемлемые конфигурации включают в себя:
- «Блокировать все сторонние файлы cookie» = ОТКЛЮЧЕНО
- «Блокировать сторонние файлы cookie» = ОТКЛЮЧЕНО
- «Блокировать сторонние файлы cookie в режиме инкогнито» = ВКЛЮЧЕНО
1.3. Загрузите инструмент локального тестирования (локальное тестирование)
Для локального тестирования потребуется загрузить инструмент локального тестирования. Инструмент будет генерировать сводные отчеты на основе незашифрованных отчетов об отладке.
Инструмент локального тестирования доступен для загрузки в JAR-архивах облачных функций на GitHub . Он должен называться LocalTestingTool_{version}.jar .
1.4. Убедитесь, что установлена JAVA JRE (служба локального тестирования и агрегирования).
Откройте «Терминал» и используйте java --version , чтобы проверить, установлена ли на вашем компьютере Java или openJDK.

Если он не установлен, его можно скачать и установить с сайта Java или сайта openJDK .
1,5. Загрузите aggregatable_report_converter (локальную службу тестирования и агрегирования)
Вы можете скачать копию aggregatable_report_converter из репозитория Privacy Sandbox Demos GitHub . В репозитории GitHub упоминается использование IntelliJ или Eclipse, но ни один из них не является обязательным. Если вы не используете эти инструменты, вместо этого загрузите файл JAR в свою локальную среду.
1.6. Настройка среды GCP (служба агрегации)
Служба агрегации требует использования доверенной среды выполнения, использующей поставщика облачных услуг. В этой кодовой лаборатории Aggregation Service будет развернут в GCP, но также поддерживается AWS .
Следуйте инструкциям по развертыванию на GitHub, чтобы настроить интерфейс командной строки gcloud, загрузить двоичные файлы и модули Terraform и создать ресурсы GCP для службы агрегации.
Ключевые шаги в инструкциях по развертыванию:
- Настройте интерфейс командной строки «gcloud» и Terraform в своей среде.
- Создайте корзину Cloud Storage для хранения состояния Terraform.
- Загрузите зависимости.
- Обновите
adtech_setup.auto.tfvarsи запуститеadtech_setupTerraform. В приложении приведен пример файлаadtech_setup.auto.tfvars. Обратите внимание на имя созданного здесь сегмента данных — оно будет использоваться в лаборатории кода для хранения создаваемых нами файлов. - Обновите
dev.auto.tfvars, олицетворите учетную запись службы развертывания и запуститеdevTerraform. В приложении приведен пример файлаdev.auto.tfvars. - После завершения развертывания запишите
frontend_service_cloudfunction_urlиз выходных данных Terraform , который понадобится для отправки запросов к службе агрегации на последующих этапах.
1.7. Полное внедрение службы агрегации (служба агрегации)
Служба агрегации требует регистрации координаторов, чтобы иметь возможность использовать эту службу. Заполните форму подключения к службе агрегации, указав свой сайт отчетов и другую информацию, выбрав «Google Cloud» и указав адрес своей учетной записи службы. Эта учетная запись службы создается в соответствии с предыдущим предварительным условием (1.6. Настройка среды GCP). (Подсказка: если вы используете имена по умолчанию, эта учетная запись службы будет начинаться с «worker-sa@»).
Подождите до 2 недель для завершения процесса адаптации.
1.8. Определите свой метод вызова конечных точек API (служба агрегации).
Эта лаборатория кода предоставляет два варианта вызова конечных точек API службы агрегации: cURL и Postman . cURL — это более быстрый и простой способ вызова конечных точек API из вашего терминала, поскольку он требует минимальной настройки и не требует дополнительного программного обеспечения. Однако, если вы не хотите использовать cURL, вместо этого вы можете использовать Postman для выполнения и сохранения запросов API для будущего использования.
В разделе 3.2. Использование службы агрегации» вы найдете подробные инструкции по использованию обоих вариантов. Вы можете просмотреть их сейчас, чтобы определить, какой метод вы будете использовать. Если вы выберете Postman, выполните следующую начальную настройку.
1.8.1. Настроить рабочее пространство
Зарегистрируйте учетную запись Postman . После регистрации для вас автоматически создается рабочее пространство.
Если у вас не создано рабочее пространство, перейдите в верхний пункт навигации «Рабочие пространства» и выберите «Создать рабочее пространство».
Выберите «Пустое рабочее пространство», нажмите «Далее» и назовите его «GCP Privacy Sandbox». Выберите «Личный» и нажмите «Создать».
Загрузите предварительно настроенную конфигурацию JSON рабочей области и файлы глобальной среды .
Импортируйте оба файла JSON в «Мое рабочее пространство» с помощью кнопки «Импорт».

Это создаст для вас коллекцию «GCP Privacy Sandbox» вместе с HTTP-запросами createJob и getJob .
1.8.2. Настроить авторизацию
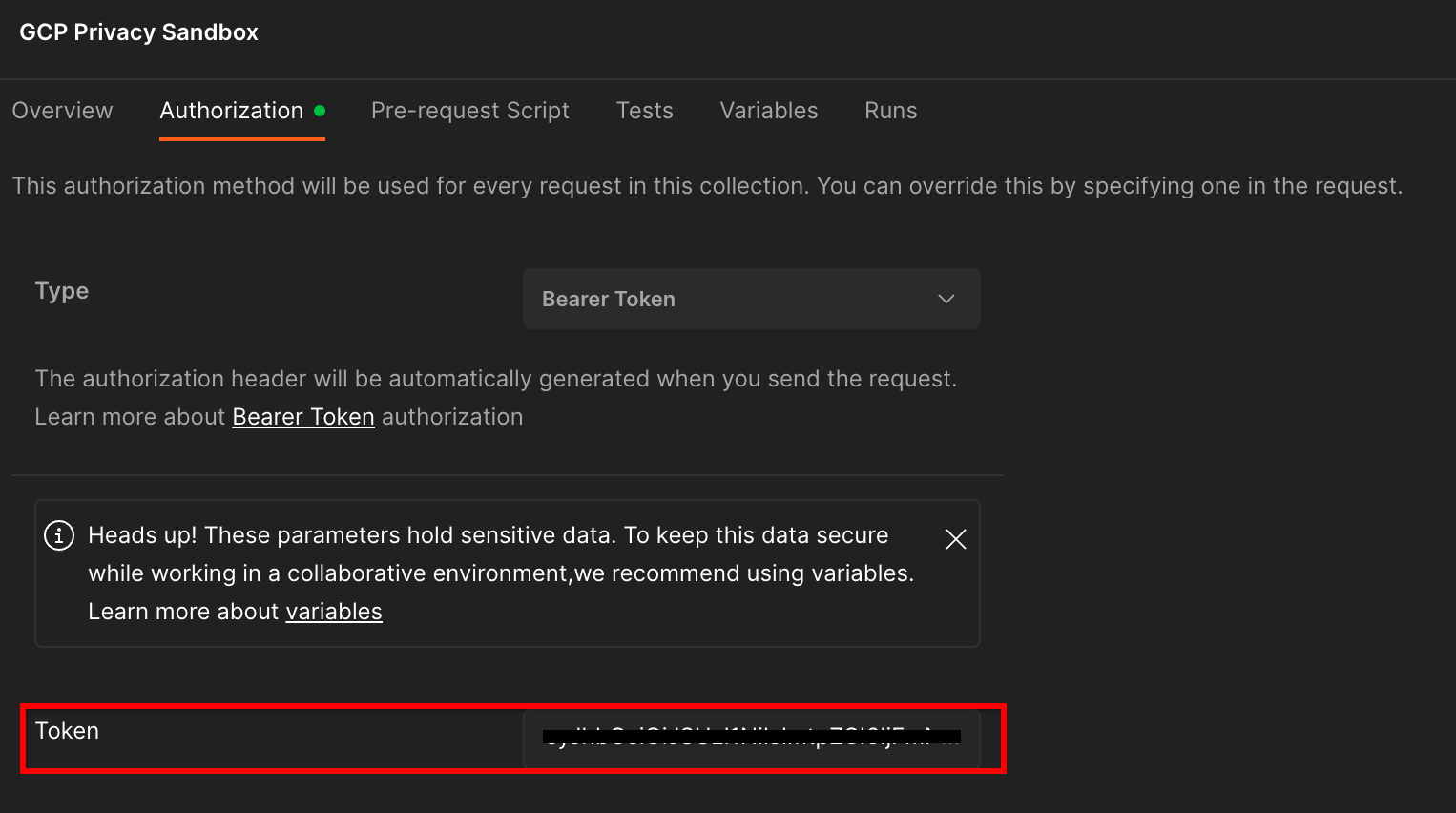
Нажмите на коллекцию «GCP Privacy Sandbox» и перейдите на вкладку «Авторизация».

Вы будете использовать метод «Токен на предъявителя». В среде терминала запустите эту команду и скопируйте вывод.
gcloud auth print-identity-token
Затем вставьте это значение токена в поле «Токен» на вкладке авторизации Postman:
1.8.3. Настройка среды
Перейдите к «Быстрый просмотр среды» в правом верхнем углу:
Нажмите «Изменить» и обновите «Текущее значение» «среды», «региона» и «идентификатора функции облака»:
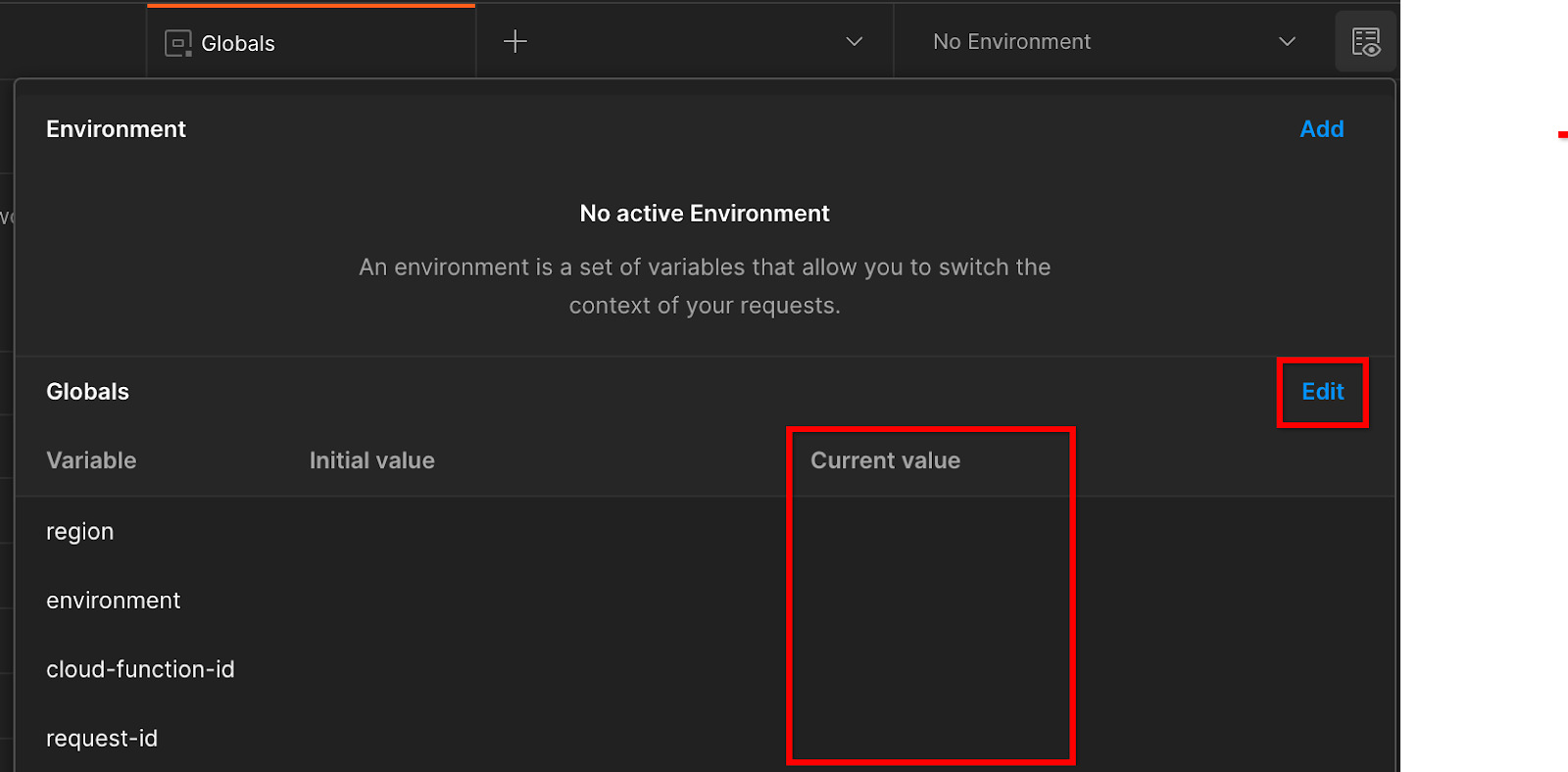
Вы можете пока оставить поле «идентификатор запроса» пустым, поскольку мы заполним его позже. Для других полей используйте значения из frontend_service_cloudfunction_url , который был возвращен после успешного завершения развертывания Terraform в предварительном условии 1.6. URL-адрес имеет следующий формат: https:// - -frontend-service- -uc.a.run.apphttps:// - -frontend-service- -uc.a.run.apphttps:// - -frontend-service- -uc.a.run.apphttps:// - -frontend-service- -uc.a.run.app
2. 2. Локальное тестирование Codelab
Примерное время выполнения: <1 час.
Вы можете использовать локальный инструмент тестирования на своем компьютере для выполнения агрегирования и создания сводных отчетов с использованием незашифрованных отчетов об отладке. Прежде чем начать , убедитесь, что вы выполнили все предварительные условия, помеченные как «Локальное тестирование».
Шаги кодовой лаборатории
Шаг 2.1. Отчет по триггеру : активируйте отчеты частного агрегирования, чтобы иметь возможность собрать отчет.
Шаг 2.2. Создать отладочный отчет AVRO . Преобразуйте собранный отчет JSON в отчет в формате AVRO. Этот шаг будет аналогичен тому, когда специалисты по рекламе собирают отчеты из конечных точек отчетности API и преобразуют отчеты JSON в отчеты в формате AVRO.
Шаг 2.3. Получите ключи от ведра . Ключи от ведра разработаны adTechs. В этой кодовой лаборатории, поскольку сегменты предварительно определены, извлеките ключи сегментов, как указано.
Шаг 2.4. Создать выходной домен AVRO . После получения ключей сегмента создайте файл AVRO выходного домена.
Шаг 2.5. Создать сводный отчет : используйте инструмент локального тестирования, чтобы иметь возможность создавать сводные отчеты в локальной среде.
Шаг 2.6. Просмотрите сводные отчеты . Просмотрите сводный отчет, созданный с помощью инструмента локального тестирования.
2.1. Триггерный отчет
Чтобы создать частный отчет по агрегированию, вы можете использовать демонстрационный сайт Privacy Sandbox (https://privacy-sandbox-demos-news.dev/?env=gcp) или свой собственный сайт (например, https://adtecexexample.com). . Если вы используете собственный сайт и не завершили регистрацию, аттестацию и подключение к службе агрегации, вам потребуется использовать флаг Chrome и переключатель CLI .
Для этой демонстрации мы будем использовать демонстрационный сайт Privacy Sandbox. Перейдите по ссылке , чтобы перейти на сайт; затем вы можете просмотреть отчеты по адресу chrome://private-aggregation-internals :
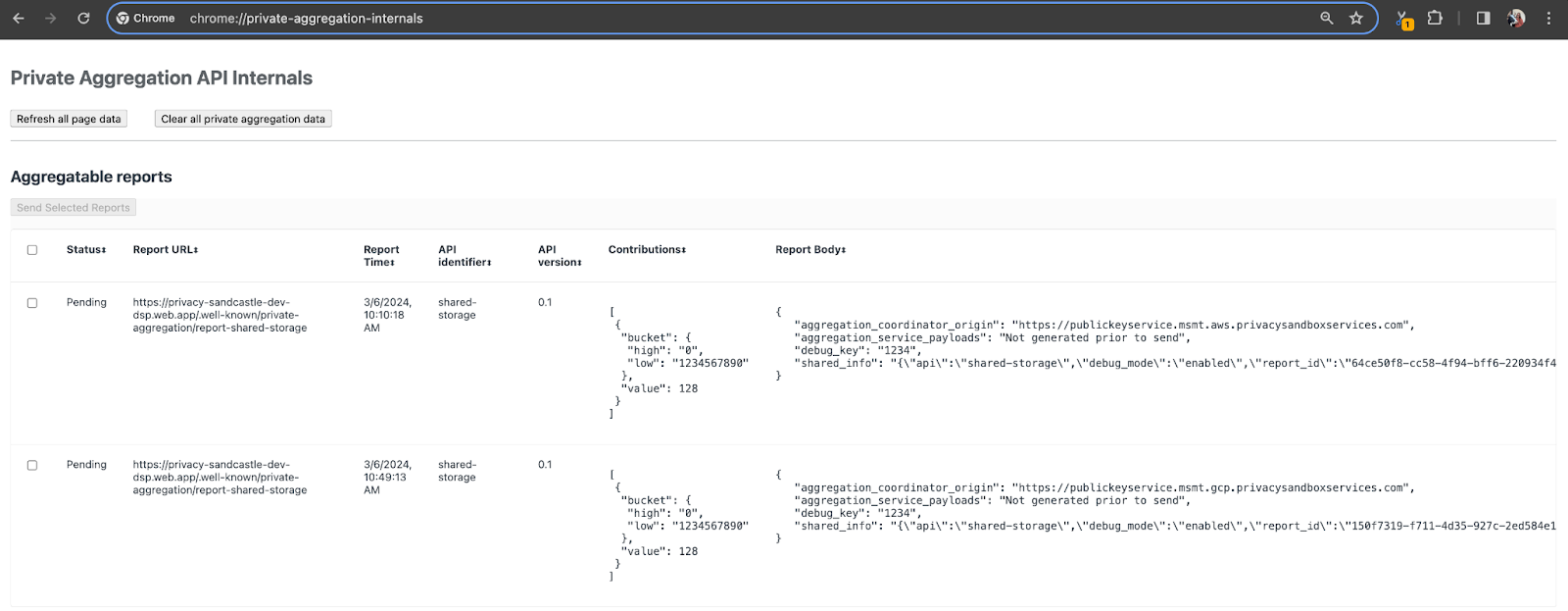
Отчет, отправляемый в конечную точку {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage также находится в «Тело отчета» отчетов, отображаемых на странице Chrome Internals.
Здесь вы можете увидеть множество отчетов, но для этой кодовой лаборатории используйте агрегированный отчет, специфичный для GCP и созданный конечной точкой отладки . «URL-адрес отчета» будет содержать «/debug/», а aggregation_coordinator_origin field «Тела отчета» будет содержать этот URL-адрес: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
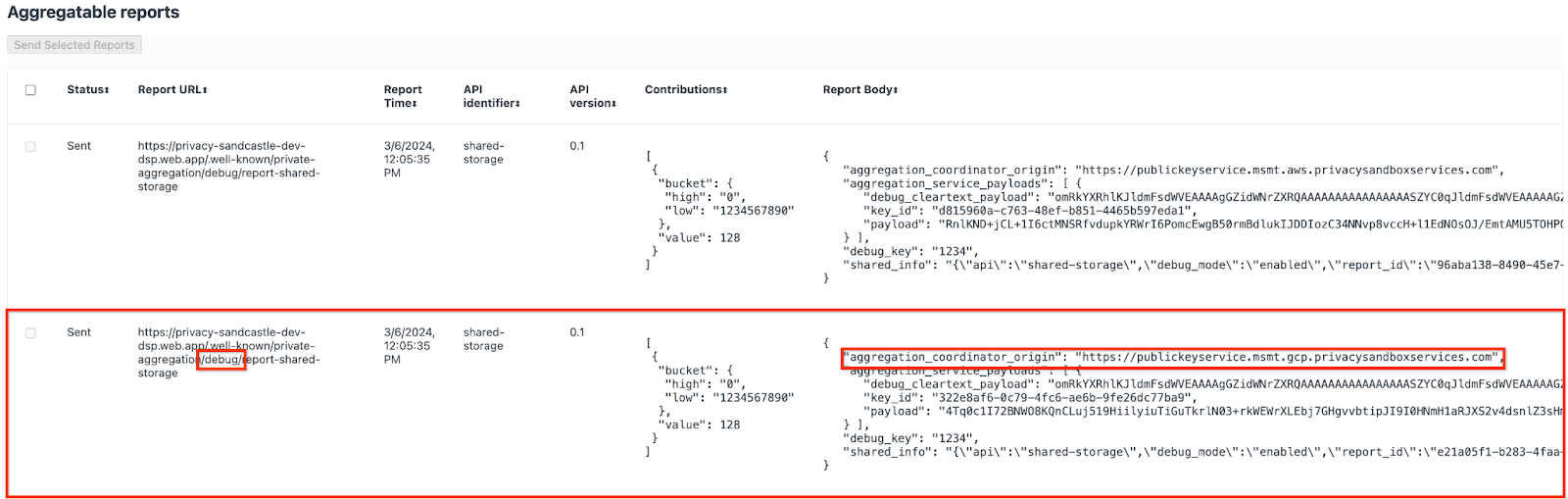
2.2. Создать сводный отчет об отладке
Скопируйте отчет, найденный в «Тело отчета» chrome://private-aggregation-internals , и создайте файл JSON в папке privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (в репозитории, загруженном в разделе «Предварительные условия»). 1.5).
В этом примере мы используем vim, поскольку используем Linux. Но вы можете использовать любой текстовый редактор, какой захотите.
vim report.json
Вставьте отчет в report.json и сохраните файл.

Получив это, используйте aggregatable_report_converter.jar , чтобы создать сводный отчет отладки. В результате в вашем текущем каталоге будет создан сводный отчет с именем report.avro .
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Получить ключ от ведра из отчета
Чтобы создать файл output_domain.avro , вам потребуются ключи сегмента, которые можно получить из отчетов.
Ключи ведра разработаны adTech. Однако в этом случае демонстрационная версия Privacy Sandbox сайта создает ключи корзины. Поскольку частное агрегирование для этого сайта находится в режиме отладки, мы можем использовать debug_cleartext_payload из «Тела отчета», чтобы получить ключ сегмента.
Продолжайте и скопируйте debug_cleartext_payload из тела отчета.

Откройте goo.gle/ags-payload-decoder , вставьте свой debug_cleartext_payload в поле «ВВОД» и нажмите «Декодировать».
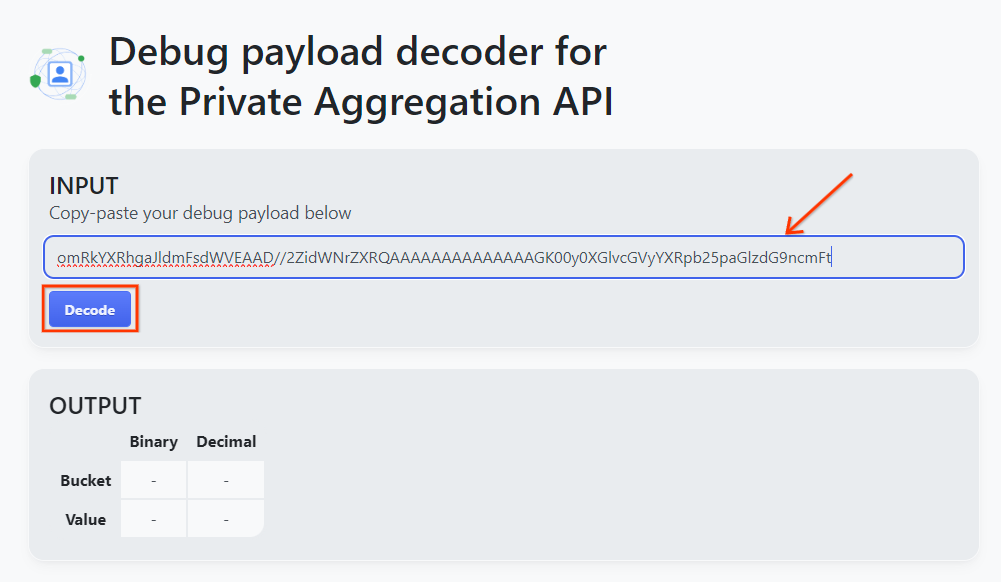
Страница возвращает десятичное значение ключа сегмента. Ниже приведен образец ключа от ведра.
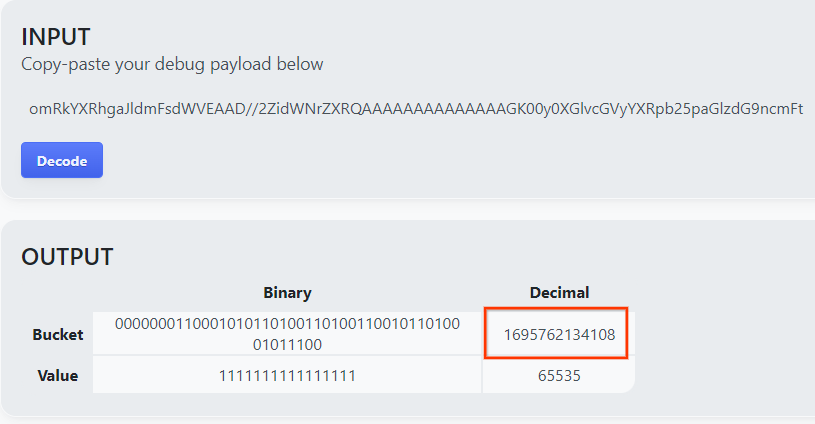
2.4. Создать выходной домен AVRO
Теперь, когда у нас есть ключ сегмента, давайте создадим output_domain.avro в той же папке, над которой мы работали. Убедитесь, что вы заменили ключ сегмента полученным ключом сегмента.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Скрипт создает файл output_domain.avro в вашей текущей папке.
2.5. Создание сводных отчетов с помощью инструмента локального тестирования
Мы будем использовать LocalTestingTool_{version}.jar , который был загружен в предварительном условии 1.3, для создания сводных отчетов с помощью приведенной ниже команды. Замените {version} версией, которую вы скачали. Не забудьте переместить LocalTestingTool_{version}.jar в текущий каталог или добавить относительный путь для ссылки на его текущее местоположение.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
После запуска команды вы должны увидеть что-то похожее на приведенное ниже. После завершения создается отчет output.avro .
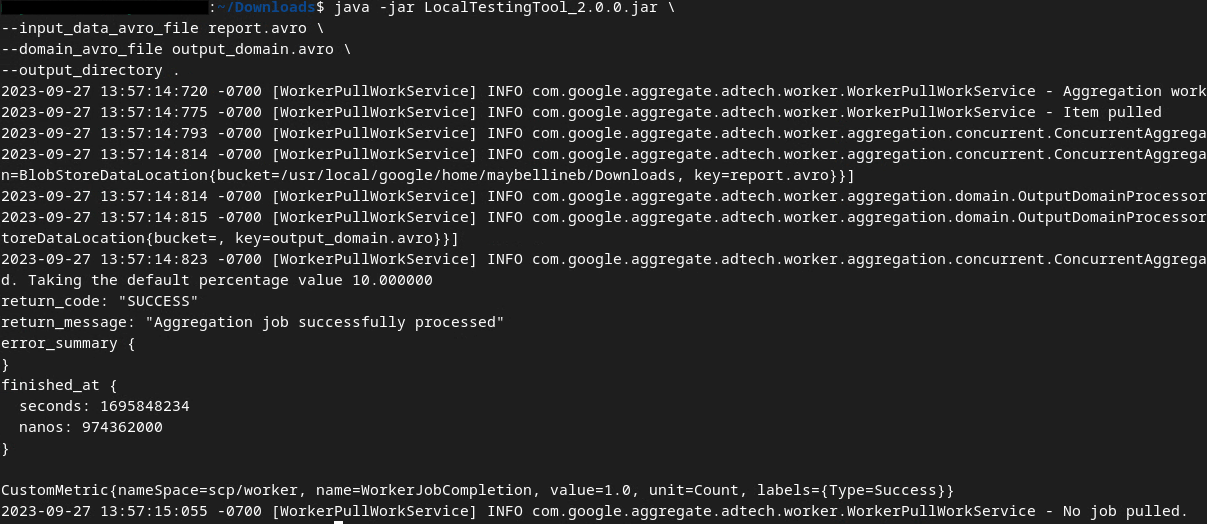
2.6. Просмотрите сводный отчет
Создаваемый сводный отчет имеет формат AVRO. Чтобы прочитать это, вам необходимо преобразовать это из AVRO в формат JSON. В идеале специалисты по рекламе должны написать код для преобразования отчетов AVRO обратно в JSON.
Мы будем использовать aggregatable_report_converter.jar , чтобы преобразовать отчет AVRO обратно в JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Это возвращает отчет, аналогичный приведенному ниже. Вместе с отчетом в том же каталоге создается output.json .

Кодлаб завершен!
Сводка: вы собрали отчет об отладке, создали выходной файл домена и создали сводный отчет с помощью локального инструмента тестирования, который имитирует поведение агрегации службы агрегации.
Дальнейшие действия: Теперь, когда вы поэкспериментировали с инструментом локального тестирования, вы можете попробовать то же самое упражнение с динамическим развертыванием службы агрегации в вашей собственной среде. Еще раз просмотрите предварительные условия, чтобы убедиться, что вы все настроили для режима «Служба агрегации», затем перейдите к шагу 3.
3. 3. Кодовая таблица службы агрегации
Примерное время выполнения: 1 час.
Прежде чем начать , убедитесь, что вы выполнили все необходимые условия, помеченные как «Служба агрегирования».
Шаги кодовой лаборатории
Шаг 3.1. Создание входных данных службы агрегации : создание отчетов службы агрегации, которые группируются для службы агрегации.
- Шаг 3.1.1. Триггерный отчет
- Шаг 3.1.2. Собирайте агрегированные отчеты
- Шаг 3.1.3. Преобразование отчетов в AVRO
- Шаг 3.1.4. Создать выходной_домен AVRO
- Шаг 3.1.5. Переместить отчеты в корзину Cloud Storage
Шаг 3.2. Использование службы агрегации . Используйте API службы агрегации для создания сводных отчетов и просмотра сводных отчетов.
- Шаг 3.2.1. Использование
createJobEndpoint для пакетной обработки - Шаг 3.2.2. Использование конечной точки
getJobдля получения статуса пакета - Шаг 3.2.3. Просмотр сводного отчета
3.1. Создание входных данных службы агрегации
Перейдите к созданию отчетов AVRO для пакетной передачи в службу агрегации. Команды оболочки на этих этапах можно запускать в Cloud Shell GCP (при условии, что зависимости из предварительных условий клонированы в вашу среду Cloud Shell) или в локальной среде выполнения.
3.1.1. Триггерный отчет
Перейдите по ссылке , чтобы перейти на сайт; затем вы можете просмотреть отчеты по адресу chrome://private-aggregation-internals :
Отчет, отправляемый в конечную точку {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage также находится в «Тело отчета» отчетов, отображаемых на странице Chrome Internals.
Здесь вы можете увидеть множество отчетов, но для этой кодовой лаборатории используйте агрегированный отчет, специфичный для GCP и созданный конечной точкой отладки . «URL-адрес отчета» будет содержать «/debug/», а aggregation_coordinator_origin field «Тела отчета» будет содержать этот URL-адрес: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. Собирайте агрегированные отчеты
Собирайте агрегированные отчеты с хорошо известных конечных точек соответствующего API.
- Частное агрегирование:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Отчеты по атрибуции – сводный отчет:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
В этой кодовой лаборатории мы выполняем сбор отчетов вручную. Ожидается, что на производстве специалисты по рекламе будут программно собирать и преобразовывать отчеты.
Давайте скопируем отчет JSON в «Тело отчета» из chrome://private-aggregation-internals .
В этом примере мы используем vim, поскольку используем Linux. Но вы можете использовать любой текстовый редактор, какой захотите.
vim report.json
Вставьте отчет в report.json и сохраните файл.
3.1.3. Преобразование отчетов в AVRO
Отчеты, полученные от .well-known конечных точек, имеют формат JSON, и их необходимо преобразовать в формат отчетов AVRO. Получив отчет в формате JSON, перейдите туда, где хранится report.json , и используйте aggregatable_report_converter.jar , чтобы создать сводный отчет отладки. В результате в вашем текущем каталоге будет создан сводный отчет с именем report.avro .
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. Создать выходной_домен AVRO
Чтобы создать файл output_domain.avro , вам потребуются ключи сегмента, которые можно получить из отчетов.
Ключи ведра разработаны adTech. Однако в этом случае демонстрационная версия Privacy Sandbox сайта создает ключи корзины. Поскольку частное агрегирование для этого сайта находится в режиме отладки, мы можем использовать debug_cleartext_payload из «Тела отчета», чтобы получить ключ сегмента.
Продолжайте и скопируйте debug_cleartext_payload из тела отчета.
Откройте goo.gle/ags-payload-decoder , вставьте свой debug_cleartext_payload в поле «ВВОД» и нажмите «Декодировать».
Страница возвращает десятичное значение ключа сегмента. Ниже приведен образец ключа от ведра.
Теперь, когда у нас есть ключ сегмента, давайте создадим output_domain.avro в той же папке, над которой мы работали. Убедитесь, что вы заменили ключ сегмента полученным ключом сегмента.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Скрипт создает файл output_domain.avro в вашей текущей папке.
3.1.5. Переместить отчеты в корзину Cloud Storage
После создания отчетов AVRO и выходного домена приступайте к перемещению отчетов и выходного домена в корзину в облачном хранилище (что вы отметили в предварительном условии 1.6).
Если в вашей локальной среде установлен интерфейс командной строки gcloud, используйте приведенные ниже команды, чтобы скопировать файлы в соответствующие папки.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
В противном случае загрузите файлы в корзину вручную. Создайте папку с названием «reports» и загрузите туда файл report.avro . Создайте папку с именем «output_domains» и загрузите туда файл output_domain.avro .
3.2. Использование службы агрегации
Напомним, что в предварительном условии 1.8 вы выбрали cURL или Postman для отправки запросов API к конечным точкам службы агрегации. Ниже вы найдете инструкции для обоих вариантов.
Если ваше задание завершается с ошибкой, ознакомьтесь с нашей документацией по устранению неполадок на GitHub, чтобы получить дополнительную информацию о том, как действовать дальше.
3.2.1. Использование createJob Endpoint для пакетной обработки
Используйте приведенные ниже инструкции cURL или Postman, чтобы создать задание.
КУЛЬ
В своем «Терминале» создайте файл тела запроса ( body.json ) и вставьте его ниже. Обязательно обновите значения заполнителей. Обратитесь к этой документации API для получения дополнительной информации о том, что представляет собой каждое поле.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Выполните приведенный ниже запрос. Замените заполнители в URL-адресе запроса cURL значениями из frontend_service_cloudfunction_url , которые выводятся после успешного завершения развертывания Terraform в предварительном условии 1.6.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
Вы должны получить ответ HTTP 202, как только запрос будет принят службой агрегации. Другие возможные коды ответа описаны в спецификациях API .
Почтальон
Для конечной точки createJob требуется тело запроса, чтобы предоставить службе агрегации расположение и имена файлов агрегируемых отчетов, выходных доменов и сводных отчетов.
Перейдите на вкладку «Тело» запроса createJob :

Замените заполнители в предоставленном JSON. Дополнительную информацию об этих полях и о том, что они представляют, можно найти в документации API .
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
«Отправьте» запрос API createJob :

Код ответа можно найти в нижней половине страницы:

Вы должны получить ответ HTTP 202, как только запрос будет принят службой агрегации. Другие возможные коды ответа описаны в спецификациях API .
3.2.2. Использование конечной точки getJob для получения статуса пакета
Используйте приведенные ниже инструкции cURL или Postman, чтобы получить работу.
КУЛЬ
Выполните приведенный ниже запрос в своем терминале. Замените заполнители в URL-адресе значениями из frontend_service_cloudfunction_url , который является тем же URL-адресом, который вы использовали для запроса createJob . В качестве «job_request_id» используйте значение из задания, которое вы создали с помощью конечной точки createJob .
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
Результат должен вернуть статус вашего запроса задания со статусом HTTP 200. Запрос «Тело» содержит необходимую информацию, такую как job_status , return_message и error_messages (если задание выполнено с ошибкой).
Почтальон
Чтобы проверить статус запроса на работу, вы можете использовать конечную точку getJob . В разделе «Параметры» запроса getJob обновите значение job_request_id на job_request_id , отправленное в запросе createJob .
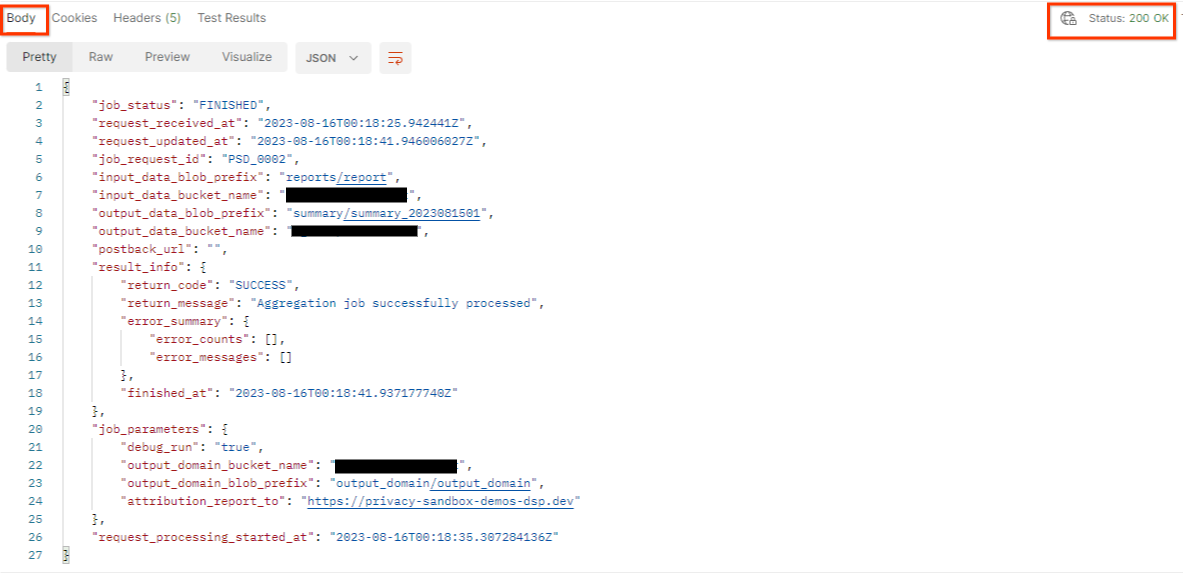
«Отправить» запрос getJob :

Результат должен вернуть статус вашего запроса задания со статусом HTTP 200. Запрос «Тело» содержит необходимую информацию, такую как job_status , return_message и error_messages (если задание выполнено с ошибкой).
3.2.3. Просмотр сводного отчета
Как только вы получите сводный отчет в выходной сегмент Cloud Storage, вы сможете загрузить его в свою локальную среду. Сводные отчеты имеют формат AVRO и могут быть преобразованы обратно в JSON. Вы можете использовать aggregatable_report_converter.jar для чтения отчета с помощью приведенной ниже команды.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Это возвращает JSON агрегированных значений каждого ключа сегмента, который выглядит примерно так, как показано ниже.

Если ваш запрос createJob включает в debug_run значение true, вы можете получить сводный отчет в папке отладки, которая находится в файле output_data_blob_prefix . Отчет имеет формат AVRO и может быть преобразован с помощью приведенной выше команды в JSON.
Отчет содержит ключ сегмента, нешумированную метрику и шум, который добавляется к нешумовой метрике для формирования сводного отчета. Отчет аналогичен приведенному ниже.

Аннотации также содержат «in_reports» и/или «in_domain», что означает:
- in_reports — ключ сегмента доступен внутри агрегируемых отчетов.
- in_domain — ключ сегмента доступен внутри файла AVRO выходного_домена.
Кодлаб завершен!
Краткое описание: вы развернули службу агрегации в своей облачной среде, собрали отчет об отладке, создали файл выходного домена, сохранили эти файлы в корзине облачного хранилища и успешно выполнили задание!
Следующие шаги: продолжайте использовать службу агрегации в своей среде или удалите только что созданные облачные ресурсы, следуя инструкциям по очистке на шаге 4.
4. 4. Очистка
Чтобы удалить ресурсы, созданные для службы агрегации через Terraform, используйте команду уничтожения в папках adtech_setup и dev (или другой среды):
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
Чтобы удалить корзину Cloud Storage, содержащую ваши агрегированные и сводные отчеты:
$ gcloud storage buckets delete gs://my-bucket
Вы также можете вернуть настройки файлов cookie Chrome из предварительного условия 1.2 в предыдущее состояние.
5. 5. Приложение
Пример файла adtech_setup.auto.tfvars
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
Пример файла dev.auto.tfvars
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20
1. 1. Предварительные условия
Примерное время выполнения: 1-2 часа
Существует 2 режима выполнения этой кодовой лаборатории: локальное тестирование или служба агрегации . Для режима локального тестирования требуется локальный компьютер и браузер Chrome (без создания/использования ресурсов Google Cloud). Режим службы агрегации требует полного развертывания службы агрегации в Google Cloud.
Для выполнения этой лабораторной работы в любом режиме необходимо выполнить несколько предварительных условий. Каждое требование помечается соответствующим образом, требуется ли оно для локального тестирования или службы агрегации.
1.1. Полная регистрация и аттестация (служба агрегации)
Чтобы использовать API-интерфейсы Privacy Sandbox, убедитесь, что вы завершили регистрацию и аттестацию как для Chrome, так и для Android.
1.2. Включить API конфиденциальности рекламы (служба локального тестирования и агрегирования)
Поскольку мы будем использовать Privacy Sandbox, мы рекомендуем вам включить рекламные API Privacy Sandbox.
В браузере перейдите по адресу chrome://settings/adPrivacy и включите все API конфиденциальности рекламы.
Также убедитесь, что сторонние файлы cookie включены .
В chrome://settings/cookies убедитесь, что сторонние файлы cookie НЕ блокируются. В зависимости от вашей версии Chrome вы можете увидеть разные параметры в этом меню настроек, но приемлемые конфигурации включают в себя:
- «Блокировать все сторонние файлы cookie» = ОТКЛЮЧЕНО
- «Блокировать сторонние файлы cookie» = ОТКЛЮЧЕНО
- «Блокировать сторонние файлы cookie в режиме инкогнито» = ВКЛЮЧЕНО
1.3. Загрузите инструмент локального тестирования (локальное тестирование)
Для локального тестирования потребуется загрузить инструмент локального тестирования. Инструмент будет генерировать сводные отчеты на основе незашифрованных отчетов об отладке.
Инструмент локального тестирования доступен для загрузки в JAR-архивах облачных функций на GitHub . Он должен называться LocalTestingTool_{version}.jar .
1.4. Убедитесь, что установлена JAVA JRE (служба локального тестирования и агрегирования).
Откройте «Терминал» и используйте java --version , чтобы проверить, установлена ли на вашем компьютере Java или openJDK.
Если он не установлен, его можно скачать и установить с сайта Java или сайта openJDK .
1,5. Загрузите aggregatable_report_converter (локальную службу тестирования и агрегирования)
Вы можете скачать копию aggregatable_report_converter из репозитория Privacy Sandbox Demos GitHub . В репозитории GitHub упоминается использование IntelliJ или Eclipse, но ни один из них не является обязательным. Если вы не используете эти инструменты, вместо этого загрузите файл JAR в свою локальную среду.
1.6. Настройка среды GCP (служба агрегации)
Служба агрегации требует использования доверенной среды выполнения, использующей поставщика облачных услуг. В этой кодовой лаборатории Aggregation Service будет развернут в GCP, но также поддерживается AWS .
Следуйте инструкциям по развертыванию на GitHub, чтобы настроить интерфейс командной строки gcloud, загрузить двоичные файлы и модули Terraform и создать ресурсы GCP для службы агрегации.
Ключевые шаги в инструкциях по развертыванию:
- Настройте интерфейс командной строки «gcloud» и Terraform в своей среде.
- Создайте корзину Cloud Storage для хранения состояния Terraform.
- Загрузите зависимости.
- Обновите
adtech_setup.auto.tfvarsи запуститеadtech_setupTerraform. В приложении приведен пример файлаadtech_setup.auto.tfvars. Обратите внимание на имя созданного здесь сегмента данных — оно будет использоваться в лаборатории кода для хранения создаваемых нами файлов. - Обновите
dev.auto.tfvars, олицетворите учетную запись службы развертывания и запуститеdevTerraform. В приложении приведен пример файлаdev.auto.tfvars. - После завершения развертывания запишите
frontend_service_cloudfunction_urlиз выходных данных Terraform , который понадобится для отправки запросов к службе агрегации на последующих этапах.
1.7. Полное внедрение службы агрегации (служба агрегации)
Служба агрегации требует регистрации координаторов, чтобы иметь возможность использовать эту службу. Заполните форму подключения к службе агрегации, указав свой сайт отчетов и другую информацию, выбрав «Google Cloud» и указав адрес своей учетной записи службы. Эта учетная запись службы создается в соответствии с предыдущим предварительным условием (1.6. Настройка среды GCP). (Подсказка: если вы используете имена по умолчанию, эта учетная запись службы будет начинаться с «worker-sa@»).
Подождите до 2 недель для завершения процесса адаптации.
1.8. Определите свой метод вызова конечных точек API (служба агрегации).
Эта лаборатория кода предоставляет два варианта вызова конечных точек API службы агрегации: cURL и Postman . cURL — это более быстрый и простой способ вызова конечных точек API из вашего терминала, поскольку он требует минимальной настройки и не требует дополнительного программного обеспечения. Однако, если вы не хотите использовать cURL, вместо этого вы можете использовать Postman для выполнения и сохранения запросов API для будущего использования.
В разделе 3.2. Использование службы агрегации» вы найдете подробные инструкции по использованию обоих вариантов. Вы можете просмотреть их сейчас, чтобы определить, какой метод вы будете использовать. Если вы выберете Postman, выполните следующую начальную настройку.
1.8.1. Настроить рабочее пространство
Зарегистрируйте учетную запись Postman . После регистрации для вас автоматически создается рабочее пространство.
Если у вас не создано рабочее пространство, перейдите в верхний пункт навигации «Рабочие пространства» и выберите «Создать рабочее пространство».
Выберите «Пустое рабочее пространство», нажмите «Далее» и назовите его «GCP Privacy Sandbox». Выберите «Личный» и нажмите «Создать».
Загрузите предварительно настроенную конфигурацию JSON рабочей области и файлы глобальной среды .
Импортируйте оба файла JSON в «Мое рабочее пространство» с помощью кнопки «Импорт».
Это создаст для вас коллекцию «GCP Privacy Sandbox» вместе с HTTP-запросами createJob и getJob .
1.8.2. Настроить авторизацию
Нажмите на коллекцию «GCP Privacy Sandbox» и перейдите на вкладку «Авторизация».
Вы будете использовать метод «Токен на предъявителя». В среде терминала запустите эту команду и скопируйте вывод.
gcloud auth print-identity-token
Затем вставьте это значение токена в поле «Токен» на вкладке авторизации Postman:
1.8.3. Настройка среды
Перейдите к «Быстрый просмотр среды» в правом верхнем углу:
Нажмите «Изменить» и обновите «Текущее значение» «среды», «региона» и «идентификатора функции облака»:
Вы можете пока оставить поле «идентификатор запроса» пустым, поскольку мы заполним его позже. Для других полей используйте значения из frontend_service_cloudfunction_url , который был возвращен после успешного завершения развертывания Terraform в предварительном условии 1.6. URL-адрес имеет следующий формат: https:// - -frontend-service- -uc.a.run.apphttps:// - -frontend-service- -uc.a.run.apphttps:// - -frontend-service- -uc.a.run.apphttps:// - -frontend-service- -uc.a.run.app
2. 2. Локальное тестирование Codelab
Примерное время выполнения: <1 час.
Вы можете использовать локальный инструмент тестирования на своем компьютере для выполнения агрегирования и создания сводных отчетов с использованием незашифрованных отчетов об отладке. Прежде чем начать , убедитесь, что вы выполнили все предварительные условия, помеченные как «Локальное тестирование».
Шаги кодовой лаборатории
Шаг 2.1. Отчет по триггеру : активируйте отчеты частного агрегирования, чтобы иметь возможность собрать отчет.
Шаг 2.2. Создать отладочный отчет AVRO . Преобразуйте собранный отчет JSON в отчет в формате AVRO. Этот шаг будет аналогичен тому, когда специалисты по рекламе собирают отчеты из конечных точек отчетности API и преобразуют отчеты JSON в отчеты в формате AVRO.
Шаг 2.3. Получите ключи от ведра . Ключи от ведра разработаны adTechs. В этой кодовой лаборатории, поскольку сегменты предварительно определены, извлеките ключи сегментов, как указано.
Шаг 2.4. Создать выходной домен AVRO . После получения ключей сегмента создайте файл AVRO выходного домена.
Шаг 2.5. Создать сводный отчет : используйте инструмент локального тестирования, чтобы иметь возможность создавать сводные отчеты в локальной среде.
Шаг 2.6. Просмотрите сводные отчеты . Просмотрите сводный отчет, созданный с помощью инструмента локального тестирования.
2.1. Триггерный отчет
Чтобы создать частный отчет по агрегированию, вы можете использовать демонстрационный сайт Privacy Sandbox (https://privacy-sandbox-demos-news.dev/?env=gcp) или свой собственный сайт (например, https://adtecexexample.com). . Если вы используете собственный сайт и не завершили регистрацию, аттестацию и подключение к службе агрегации, вам потребуется использовать флаг Chrome и переключатель CLI .
Для этой демонстрации мы будем использовать демонстрационный сайт Privacy Sandbox. Перейдите по ссылке , чтобы перейти на сайт; затем вы можете просмотреть отчеты по адресу chrome://private-aggregation-internals :
Отчет, отправляемый в конечную точку {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage также находится в «Тело отчета» отчетов, отображаемых на странице Chrome Internals.
Здесь вы можете увидеть множество отчетов, но для этой кодовой лаборатории используйте агрегированный отчет, специфичный для GCP и созданный конечной точкой отладки . «URL-адрес отчета» будет содержать «/debug/», а aggregation_coordinator_origin field «Тела отчета» будет содержать этот URL-адрес: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
2.2. Создать сводный отчет об отладке
Скопируйте отчет, найденный в «Тело отчета» chrome://private-aggregation-internals , и создайте файл JSON в папке privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (в репозитории, загруженном в разделе «Предварительные условия»). 1.5).
В этом примере мы используем vim, поскольку используем Linux. Но вы можете использовать любой текстовый редактор, какой захотите.
vim report.json
Вставьте отчет в report.json и сохраните файл.
Получив это, используйте aggregatable_report_converter.jar , чтобы создать сводный отчет отладки. В результате в вашем текущем каталоге будет создан сводный отчет с именем report.avro .
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Получить ключ от ведра из отчета
Чтобы создать файл output_domain.avro , вам потребуются ключи сегмента, которые можно получить из отчетов.
Ключи ведра разработаны adTech. Однако в этом случае демонстрационная версия Privacy Sandbox сайта создает ключи корзины. Поскольку частное агрегирование для этого сайта находится в режиме отладки, мы можем использовать debug_cleartext_payload из «Тела отчета», чтобы получить ключ сегмента.
Продолжайте и скопируйте debug_cleartext_payload из тела отчета.
Откройте goo.gle/ags-payload-decoder , вставьте свой debug_cleartext_payload в поле «ВВОД» и нажмите «Декодировать».
Страница возвращает десятичное значение ключа сегмента. Ниже приведен образец ключа от ведра.
2.4. Создать выходной домен AVRO
Теперь, когда у нас есть ключ сегмента, давайте создадим output_domain.avro в той же папке, над которой мы работали. Убедитесь, что вы заменили ключ сегмента полученным ключом сегмента.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Скрипт создает файл output_domain.avro в вашей текущей папке.
2.5. Создание сводных отчетов с помощью инструмента локального тестирования
Мы будем использовать LocalTestingTool_{version}.jar , который был загружен в предварительном условии 1.3, для создания сводных отчетов с помощью приведенной ниже команды. Замените {version} версией, которую вы скачали. Не забудьте переместить LocalTestingTool_{version}.jar в текущий каталог или добавить относительный путь для ссылки на его текущее местоположение.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
После запуска команды вы должны увидеть что-то похожее на приведенное ниже. После завершения создается отчет output.avro .
2.6. Просмотрите сводный отчет
Создаваемый сводный отчет имеет формат AVRO. Чтобы прочитать это, вам необходимо преобразовать это из AVRO в формат JSON. В идеале специалисты по рекламе должны написать код для преобразования отчетов AVRO обратно в JSON.
Мы будем использовать aggregatable_report_converter.jar , чтобы преобразовать отчет AVRO обратно в JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Это возвращает отчет, аналогичный приведенному ниже. Вместе с отчетом в том же каталоге создается output.json .
Кодлаб завершен!
Сводка: вы собрали отчет об отладке, создали выходной файл домена и создали сводный отчет с помощью локального инструмента тестирования, который имитирует поведение агрегации службы агрегации.
Дальнейшие действия: Теперь, когда вы поэкспериментировали с инструментом локального тестирования, вы можете попробовать то же самое упражнение с динамическим развертыванием службы агрегации в вашей собственной среде. Еще раз просмотрите предварительные условия, чтобы убедиться, что вы все настроили для режима «Служба агрегации», затем перейдите к шагу 3.
3. 3. Кодовая таблица службы агрегации
Примерное время выполнения: 1 час.
Прежде чем начать , убедитесь, что вы выполнили все необходимые условия, помеченные как «Служба агрегирования».
Шаги кодовой лаборатории
Шаг 3.1. Создание входных данных службы агрегации : создание отчетов службы агрегации, которые группируются для службы агрегации.
- Шаг 3.1.1. Триггерный отчет
- Шаг 3.1.2. Собирайте агрегированные отчеты
- Шаг 3.1.3. Преобразование отчетов в AVRO
- Шаг 3.1.4. Создать выходной_домен AVRO
- Шаг 3.1.5. Переместить отчеты в корзину Cloud Storage
Шаг 3.2. Использование службы агрегации . Используйте API службы агрегации для создания сводных отчетов и просмотра сводных отчетов.
- Шаг 3.2.1. Использование
createJobEndpoint для пакетной обработки - Шаг 3.2.2. Использование конечной точки
getJobдля получения статуса пакета - Шаг 3.2.3. Просмотр сводного отчета
3.1. Создание входных данных службы агрегации
Перейдите к созданию отчетов AVRO для пакетной передачи в службу агрегации. Команды оболочки на этих этапах можно запускать в Cloud Shell GCP (при условии, что зависимости из предварительных условий клонированы в вашу среду Cloud Shell) или в локальной среде выполнения.
3.1.1. Триггерный отчет
Перейдите по ссылке , чтобы перейти на сайт; затем вы можете просмотреть отчеты по адресу chrome://private-aggregation-internals :
Отчет, отправляемый в конечную точку {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage также находится в «Тело отчета» отчетов, отображаемых на странице Chrome Internals.
Здесь вы можете увидеть множество отчетов, но для этой кодовой лаборатории используйте агрегированный отчет, специфичный для GCP и созданный конечной точкой отладки . «URL-адрес отчета» будет содержать «/debug/», а aggregation_coordinator_origin field «Тела отчета» будет содержать этот URL-адрес: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. Собирайте агрегированные отчеты
Собирайте агрегированные отчеты с хорошо известных конечных точек соответствующего API.
- Частное агрегирование:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Отчеты по атрибуции – сводный отчет:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
В этой кодовой лаборатории мы выполняем сбор отчетов вручную. Ожидается, что на производстве специалисты по рекламе будут программно собирать и преобразовывать отчеты.
Давайте скопируем отчет JSON в «Тело отчета» из chrome://private-aggregation-internals .
В этом примере мы используем vim, поскольку используем Linux. Но вы можете использовать любой текстовый редактор, какой захотите.
vim report.json
Вставьте отчет в report.json и сохраните файл.
3.1.3. Преобразование отчетов в AVRO
Отчеты, полученные от .well-known конечных точек, имеют формат JSON, и их необходимо преобразовать в формат отчетов AVRO. Получив отчет в формате JSON, перейдите туда, где хранится report.json , и используйте aggregatable_report_converter.jar , чтобы создать сводный отчет отладки. В результате в вашем текущем каталоге будет создан сводный отчет с именем report.avro .
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. Создать выходной_домен AVRO
Чтобы создать файл output_domain.avro , вам потребуются ключи сегмента, которые можно получить из отчетов.
Ключи ведра разработаны adTech. Однако в этом случае демонстрационная версия Privacy Sandbox сайта создает ключи корзины. Поскольку частное агрегирование для этого сайта находится в режиме отладки, мы можем использовать debug_cleartext_payload из «Тела отчета», чтобы получить ключ сегмента.
Продолжайте и скопируйте debug_cleartext_payload из тела отчета.
Откройте goo.gle/ags-payload-decoder , вставьте свой debug_cleartext_payload в поле «ВВОД» и нажмите «Декодировать».
Страница возвращает десятичное значение ключа сегмента. Ниже приведен образец ключа от ведра.
Теперь, когда у нас есть ключ сегмента, давайте создадим output_domain.avro в той же папке, над которой мы работали. Убедитесь, что вы заменили ключ сегмента полученным ключом сегмента.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Скрипт создает файл output_domain.avro в вашей текущей папке.
3.1.5. Переместить отчеты в корзину Cloud Storage
После создания отчетов AVRO и выходного домена приступайте к перемещению отчетов и выходного домена в корзину в облачном хранилище (что вы отметили в предварительном условии 1.6).
Если в вашей локальной среде установлен интерфейс командной строки gcloud, используйте приведенные ниже команды, чтобы скопировать файлы в соответствующие папки.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
В противном случае загрузите файлы в корзину вручную. Создайте папку с названием «reports» и загрузите туда файл report.avro . Создайте папку с именем «output_domains» и загрузите туда файл output_domain.avro .
3.2. Использование службы агрегации
Напомним, что в предварительном условии 1.8 вы выбрали cURL или Postman для отправки запросов API к конечным точкам службы агрегации. Ниже вы найдете инструкции для обоих вариантов.
Если ваше задание завершается с ошибкой, ознакомьтесь с нашей документацией по устранению неполадок на GitHub, чтобы получить дополнительную информацию о том, как действовать дальше.
3.2.1. Использование createJob Endpoint для пакетной обработки
Используйте приведенные ниже инструкции cURL или Postman, чтобы создать задание.
КУЛЬ
В своем «Терминале» создайте файл тела запроса ( body.json ) и вставьте его ниже. Обязательно обновите значения заполнителей. Обратитесь к этой документации API для получения дополнительной информации о том, что представляет собой каждое поле.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Выполните приведенный ниже запрос. Замените заполнители в URL-адресе запроса cURL значениями из frontend_service_cloudfunction_url , которые выводятся после успешного завершения развертывания Terraform в предварительном условии 1.6.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
Вы должны получить ответ HTTP 202, как только запрос будет принят службой агрегации. Другие возможные коды ответа описаны в спецификациях API .
Почтальон
Для конечной точки createJob требуется тело запроса, чтобы предоставить службе агрегации расположение и имена файлов агрегируемых отчетов, выходных доменов и сводных отчетов.
Перейдите на вкладку «Тело» запроса createJob :
Замените заполнители в предоставленном JSON. Дополнительную информацию об этих полях и о том, что они представляют, можно найти в документации API .
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
«Отправьте» запрос API createJob :
Код ответа можно найти в нижней половине страницы:
Вы должны получить ответ HTTP 202, как только запрос будет принят службой агрегации. Другие возможные коды ответа описаны в спецификациях API .
3.2.2. Использование конечной точки getJob для получения статуса пакета
Используйте приведенные ниже инструкции cURL или Postman, чтобы получить работу.
КУЛЬ
Выполните приведенный ниже запрос в своем терминале. Замените заполнители в URL-адресе значениями из frontend_service_cloudfunction_url , который является тем же URL-адресом, который вы использовали для запроса createJob . В качестве «job_request_id» используйте значение из задания, которое вы создали с помощью конечной точки createJob .
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
Результат должен вернуть статус вашего запроса задания со статусом HTTP 200. Запрос «Тело» содержит необходимую информацию, такую как job_status , return_message и error_messages (если задание выполнено с ошибкой).
Почтальон
Чтобы проверить статус запроса на работу, вы можете использовать конечную точку getJob . В разделе «Параметры» запроса getJob обновите значение job_request_id на job_request_id , отправленное в запросе createJob .
«Отправить» запрос getJob :
Результат должен вернуть статус вашего запроса задания со статусом HTTP 200. Запрос «Тело» содержит необходимую информацию, такую как job_status , return_message и error_messages (если задание выполнено с ошибкой).
3.2.3. Просмотр сводного отчета
Как только вы получите сводный отчет в выходной сегмент Cloud Storage, вы сможете загрузить его в свою локальную среду. Сводные отчеты имеют формат AVRO и могут быть преобразованы обратно в JSON. Вы можете использовать aggregatable_report_converter.jar для чтения отчета с помощью приведенной ниже команды.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Это возвращает JSON агрегированных значений каждого ключа сегмента, который выглядит примерно так, как показано ниже.
Если ваш запрос createJob включает в debug_run значение true, вы можете получить сводный отчет в папке отладки, которая находится в файле output_data_blob_prefix . Отчет имеет формат AVRO и может быть преобразован с помощью приведенной выше команды в JSON.
Отчет содержит ключ сегмента, нешумированную метрику и шум, который добавляется к нешумовой метрике для формирования сводного отчета. Отчет аналогичен приведенному ниже.
Аннотации также содержат «in_reports» и/или «in_domain», что означает:
- in_reports — ключ сегмента доступен внутри агрегируемых отчетов.
- in_domain — ключ сегмента доступен внутри файла AVRO выходного_домена.
Кодлаб завершен!
Краткое описание: вы развернули службу агрегации в своей облачной среде, собрали отчет об отладке, создали файл выходного домена, сохранили эти файлы в корзине облачного хранилища и успешно выполнили задание!
Следующие шаги: продолжайте использовать службу агрегации в своей среде или удалите только что созданные облачные ресурсы, следуя инструкциям по очистке на шаге 4.
4. 4. Очистка
Чтобы удалить ресурсы, созданные для службы агрегации через Terraform, используйте команду уничтожения в папках adtech_setup и dev (или другой среды):
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
Чтобы удалить корзину Cloud Storage, содержащую ваши агрегированные и сводные отчеты:
$ gcloud storage buckets delete gs://my-bucket
Вы также можете вернуть настройки файлов cookie Chrome из предварительного условия 1.2 в предыдущее состояние.
5. 5. Приложение
Пример файла adtech_setup.auto.tfvars
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
Пример файла dev.auto.tfvars
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20
1. 1. Предварительные условия
Примерное время выполнения: 1-2 часа
Существует 2 режима выполнения этой кодовой лаборатории: локальное тестирование или служба агрегации . Для режима локального тестирования требуется локальный компьютер и браузер Chrome (без создания/использования ресурсов Google Cloud). Режим службы агрегации требует полного развертывания службы агрегации в Google Cloud.
Для выполнения этой лабораторной работы в любом режиме необходимо выполнить несколько предварительных условий. Каждое требование помечается соответствующим образом, требуется ли оно для локального тестирования или службы агрегации.
1.1. Полная регистрация и аттестация (служба агрегации)
Чтобы использовать API-интерфейсы Privacy Sandbox, убедитесь, что вы завершили регистрацию и аттестацию как для Chrome, так и для Android.
1.2. Включить API конфиденциальности рекламы (служба локального тестирования и агрегирования)
Поскольку мы будем использовать Privacy Sandbox, мы рекомендуем вам включить рекламные API Privacy Sandbox.
В браузере перейдите по адресу chrome://settings/adPrivacy и включите все API конфиденциальности рекламы.
Также убедитесь, что сторонние файлы cookie включены .
В chrome://settings/cookies убедитесь, что сторонние файлы cookie НЕ блокируются. В зависимости от вашей версии Chrome вы можете увидеть разные параметры в этом меню настроек, но приемлемые конфигурации включают в себя:
- «Блокировать все сторонние файлы cookie» = ОТКЛЮЧЕНО
- «Блокировать сторонние файлы cookie» = ОТКЛЮЧЕНО
- «Блокировать сторонние файлы cookie в режиме инкогнито» = ВКЛЮЧЕНО
1.3. Загрузите инструмент локального тестирования (локальное тестирование)
Для локального тестирования потребуется загрузить инструмент локального тестирования. Инструмент будет генерировать сводные отчеты на основе незашифрованных отчетов об отладке.
Инструмент локального тестирования доступен для загрузки в JAR-архивах облачных функций на GitHub . Он должен называться LocalTestingTool_{version}.jar .
1.4. Убедитесь, что установлена JAVA JRE (служба локального тестирования и агрегирования).
Откройте «Терминал» и используйте java --version , чтобы проверить, установлена ли на вашем компьютере Java или openJDK.
Если он не установлен, его можно скачать и установить с сайта Java или сайта openJDK .
1,5. Загрузите aggregatable_report_converter (локальную службу тестирования и агрегирования)
Вы можете скачать копию aggregatable_report_converter из репозитория Privacy Sandbox Demos GitHub . В репозитории GitHub упоминается использование IntelliJ или Eclipse, но ни один из них не является обязательным. Если вы не используете эти инструменты, вместо этого загрузите файл JAR в свою локальную среду.
1.6. Настройка среды GCP (служба агрегации)
Служба агрегации требует использования доверенной среды выполнения, использующей поставщика облачных услуг. В этой кодовой лаборатории Aggregation Service будет развернут в GCP, но также поддерживается AWS .
Следуйте инструкциям по развертыванию на GitHub, чтобы настроить интерфейс командной строки gcloud, загрузить двоичные файлы и модули Terraform и создать ресурсы GCP для службы агрегации.
Ключевые шаги в инструкциях по развертыванию:
- Настройте интерфейс командной строки «gcloud» и Terraform в своей среде.
- Создайте корзину Cloud Storage для хранения состояния Terraform.
- Загрузите зависимости.
- Обновите
adtech_setup.auto.tfvarsи запуститеadtech_setupTerraform. В приложении приведен пример файлаadtech_setup.auto.tfvars. Обратите внимание на имя созданного здесь сегмента данных — оно будет использоваться в лаборатории кода для хранения создаваемых нами файлов. - Обновите
dev.auto.tfvars, олицетворите учетную запись службы развертывания и запуститеdevTerraform. В приложении приведен пример файлаdev.auto.tfvars. - После завершения развертывания запишите
frontend_service_cloudfunction_urlиз выходных данных Terraform , который понадобится для отправки запросов к службе агрегации на последующих этапах.
1.7. Полное внедрение службы агрегации (служба агрегации)
Служба агрегации требует регистрации координаторов, чтобы иметь возможность использовать эту службу. Заполните форму подключения к службе агрегации, указав свой сайт отчетов и другую информацию, выбрав «Google Cloud» и указав адрес своей учетной записи службы. Эта учетная запись службы создается в соответствии с предыдущим предварительным условием (1.6. Настройка среды GCP). (Подсказка: если вы используете имена по умолчанию, эта учетная запись службы будет начинаться с «worker-sa@»).
Подождите до 2 недель для завершения процесса адаптации.
1.8. Определите свой метод вызова конечных точек API (служба агрегации).
Эта лаборатория кода предоставляет два варианта вызова конечных точек API службы агрегации: cURL и Postman . cURL — это более быстрый и простой способ вызова конечных точек API из вашего терминала, поскольку он требует минимальной настройки и не требует дополнительного программного обеспечения. Однако, если вы не хотите использовать cURL, вместо этого вы можете использовать Postman для выполнения и сохранения запросов API для будущего использования.
В разделе 3.2. Использование службы агрегации» вы найдете подробные инструкции по использованию обоих вариантов. Вы можете просмотреть их сейчас, чтобы определить, какой метод вы будете использовать. Если вы выберете Postman, выполните следующую начальную настройку.
1.8.1. Настроить рабочее пространство
Зарегистрируйте учетную запись Postman . После регистрации для вас автоматически создается рабочее пространство.
Если у вас не создано рабочее пространство, перейдите в верхний пункт навигации «Рабочие пространства» и выберите «Создать рабочее пространство».
Выберите «Пустое рабочее пространство», нажмите «Далее» и назовите его «GCP Privacy Sandbox». Выберите «Личный» и нажмите «Создать».
Загрузите предварительно настроенную конфигурацию JSON рабочей области и файлы глобальной среды .
Импортируйте оба файла JSON в «Мое рабочее пространство» с помощью кнопки «Импорт».
Это создаст для вас коллекцию «GCP Privacy Sandbox» вместе с HTTP-запросами createJob и getJob .
1.8.2. Настроить авторизацию
Нажмите на коллекцию «GCP Privacy Sandbox» и перейдите на вкладку «Авторизация».
Вы будете использовать метод «Токен на предъявителя». В среде терминала запустите эту команду и скопируйте вывод.
gcloud auth print-identity-token
Затем вставьте это значение токена в поле «Токен» на вкладке авторизации Postman:
1.8.3. Настройка среды
Перейдите к «Быстрый просмотр среды» в правом верхнем углу:
Нажмите «Изменить» и обновите «Текущее значение» «среды», «региона» и «идентификатора функции облака»:
Вы можете пока оставить поле «идентификатор запроса» пустым, поскольку мы заполним его позже. Для других полей используйте значения из frontend_service_cloudfunction_url , который был возвращен после успешного завершения развертывания Terraform в предварительном условии 1.6. URL-адрес имеет следующий формат: https:// - -frontend-service- -uc.a.run.apphttps:// - -frontend-service- -uc.a.run.apphttps:// - -frontend-service- -uc.a.run.apphttps:// - -frontend-service- -uc.a.run.app
2. 2. Локальное тестирование Codelab
Примерное время выполнения: <1 час.
Вы можете использовать локальный инструмент тестирования на своем компьютере для выполнения агрегирования и создания сводных отчетов с использованием незашифрованных отчетов об отладке. Прежде чем начать , убедитесь, что вы выполнили все предварительные условия, помеченные как «Локальное тестирование».
Шаги кодовой лаборатории
Шаг 2.1. Отчет по триггеру : активируйте отчеты частного агрегирования, чтобы иметь возможность собрать отчет.
Шаг 2.2. Создать отладочный отчет AVRO . Преобразуйте собранный отчет JSON в отчет в формате AVRO. Этот шаг будет аналогичен тому, когда специалисты по рекламе собирают отчеты из конечных точек отчетности API и преобразуют отчеты JSON в отчеты в формате AVRO.
Шаг 2.3. Получите ключи от ведра . Ключи от ведра разработаны adTechs. В этой кодовой лаборатории, поскольку сегменты предварительно определены, извлеките ключи сегментов, как указано.
Шаг 2.4. Создать выходной домен AVRO . После получения ключей сегмента создайте файл AVRO выходного домена.
Шаг 2.5. Создать сводный отчет : используйте инструмент локального тестирования, чтобы иметь возможность создавать сводные отчеты в локальной среде.
Шаг 2.6. Просмотрите сводные отчеты . Просмотрите сводный отчет, созданный с помощью инструмента локального тестирования.
2.1. Триггерный отчет
Чтобы создать частный отчет по агрегированию, вы можете использовать демонстрационный сайт Privacy Sandbox (https://privacy-sandbox-demos-news.dev/?env=gcp) или свой собственный сайт (например, https://adtecexexample.com). . Если вы используете собственный сайт и не завершили регистрацию, аттестацию и подключение к службе агрегации, вам потребуется использовать флаг Chrome и переключатель CLI .
Для этой демонстрации мы будем использовать демонстрационный сайт Privacy Sandbox. Перейдите по ссылке , чтобы перейти на сайт; затем вы можете просмотреть отчеты по адресу chrome://private-aggregation-internals :
Отчет, отправляемый в конечную точку {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage также находится в «Тело отчета» отчетов, отображаемых на странице Chrome Internals.
Здесь вы можете увидеть множество отчетов, но для этой кодовой лаборатории используйте агрегированный отчет, специфичный для GCP и созданный конечной точкой отладки . «URL-адрес отчета» будет содержать «/debug/», а aggregation_coordinator_origin field «Тела отчета» будет содержать этот URL-адрес: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
2.2. Создать сводный отчет об отладке
Скопируйте отчет, найденный в «Тело отчета» chrome://private-aggregation-internals , и создайте файл JSON в папке privacy-sandbox-demos/tools/aggregatable_report_converter/out/artifacts/aggregatable_report_converter_jar (в репозитории, загруженном в разделе «Предварительные условия»). 1.5).
В этом примере мы используем vim, поскольку используем Linux. Но вы можете использовать любой текстовый редактор, какой захотите.
vim report.json
Вставьте отчет в report.json и сохраните файл.
Получив это, используйте aggregatable_report_converter.jar , чтобы создать сводный отчет отладки. В результате в вашем текущем каталоге будет создан сводный отчет с именем report.avro .
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json \
--debug
2.3. Получить ключ от ведра из отчета
Чтобы создать файл output_domain.avro , вам потребуются ключи сегмента, которые можно получить из отчетов.
Ключи ведра разработаны adTech. Однако в этом случае демонстрационная версия Privacy Sandbox сайта создает ключи корзины. Поскольку частное агрегирование для этого сайта находится в режиме отладки, мы можем использовать debug_cleartext_payload из «Тела отчета», чтобы получить ключ сегмента.
Продолжайте и скопируйте debug_cleartext_payload из тела отчета.
Откройте goo.gle/ags-payload-decoder , вставьте свой debug_cleartext_payload в поле «ВВОД» и нажмите «Декодировать».
Страница возвращает десятичное значение ключа сегмента. Ниже приведен образец ключа от ведра.
2.4. Создать выходной домен AVRO
Теперь, когда у нас есть ключ сегмента, давайте создадим output_domain.avro в той же папке, над которой мы работали. Убедитесь, что вы заменили ключ сегмента полученным ключом сегмента.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Скрипт создает файл output_domain.avro в вашей текущей папке.
2.5. Создание сводных отчетов с помощью инструмента локального тестирования
Мы будем использовать LocalTestingTool_{version}.jar , который был загружен в предварительном условии 1.3, для создания сводных отчетов с помощью приведенной ниже команды. Замените {version} версией, которую вы скачали. Не забудьте переместить LocalTestingTool_{version}.jar в текущий каталог или добавить относительный путь для ссылки на его текущее местоположение.
java -jar LocalTestingTool_{version}.jar \
--input_data_avro_file report.avro \
--domain_avro_file output_domain.avro \
--output_directory .
После запуска команды вы должны увидеть что-то похожее на приведенное ниже. После завершения создается отчет output.avro .
2.6. Просмотрите сводный отчет
Создаваемый сводный отчет имеет формат AVRO. Чтобы прочитать это, вам необходимо преобразовать это из AVRO в формат JSON. В идеале специалисты по рекламе должны написать код для преобразования отчетов AVRO обратно в JSON.
Мы будем использовать aggregatable_report_converter.jar , чтобы преобразовать отчет AVRO обратно в JSON.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file output.avro
Это возвращает отчет, аналогичный приведенному ниже. Вместе с отчетом в том же каталоге создается output.json .
Кодлаб завершен!
Сводка: вы собрали отчет об отладке, создали выходной файл домена и создали сводный отчет с помощью локального инструмента тестирования, который имитирует поведение агрегации службы агрегации.
Дальнейшие действия: Теперь, когда вы поэкспериментировали с инструментом локального тестирования, вы можете попробовать то же самое упражнение с динамическим развертыванием службы агрегации в вашей собственной среде. Еще раз просмотрите предварительные условия, чтобы убедиться, что вы все настроили для режима «Служба агрегации», затем перейдите к шагу 3.
3. 3. Кодовая таблица службы агрегации
Примерное время выполнения: 1 час.
Прежде чем начать , убедитесь, что вы выполнили все необходимые условия, помеченные как «Служба агрегирования».
Шаги кодовой лаборатории
Шаг 3.1. Создание входных данных службы агрегации : создание отчетов службы агрегации, которые группируются для службы агрегации.
- Шаг 3.1.1. Триггерный отчет
- Шаг 3.1.2. Собирайте агрегированные отчеты
- Шаг 3.1.3. Преобразование отчетов в AVRO
- Шаг 3.1.4. Создать выходной_домен AVRO
- Шаг 3.1.5. Переместить отчеты в корзину Cloud Storage
Шаг 3.2. Использование службы агрегации . Используйте API службы агрегации для создания сводных отчетов и просмотра сводных отчетов.
- Шаг 3.2.1. Использование
createJobEndpoint для пакетной обработки - Шаг 3.2.2. Использование конечной точки
getJobдля получения статуса пакета - Шаг 3.2.3. Просмотр сводного отчета
3.1. Создание входных данных службы агрегации
Перейдите к созданию отчетов AVRO для пакетной передачи в службу агрегации. Команды оболочки на этих этапах можно запускать в Cloud Shell GCP (при условии, что зависимости из предварительных условий клонированы в вашу среду Cloud Shell) или в локальной среде выполнения.
3.1.1. Триггерный отчет
Перейдите по ссылке , чтобы перейти на сайт; затем вы можете просмотреть отчеты по адресу chrome://private-aggregation-internals :
Отчет, отправляемый в конечную точку {reporting-origin}/.well-known/private-aggregation/debug/report-shared-storage также находится в «Тело отчета» отчетов, отображаемых на странице Chrome Internals.
Здесь вы можете увидеть множество отчетов, но для этой кодовой лаборатории используйте агрегированный отчет, специфичный для GCP и созданный конечной точкой отладки . «URL-адрес отчета» будет содержать «/debug/», а aggregation_coordinator_origin field «Тела отчета» будет содержать этот URL-адрес: https://publickeyservice.msmt.gcp.privacysandboxservices.com.
3.1.2. Собирайте агрегированные отчеты
Собирайте агрегированные отчеты с хорошо известных конечных точек соответствующего API.
- Частное агрегирование:
{reporting-origin}/.well-known/private-aggregation/report-shared-storage - Отчеты по атрибуции – сводный отчет:
{reporting-origin}/.well-known/attribution-reporting/report-aggregate-attribution
В этой кодовой лаборатории мы выполняем сбор отчетов вручную. Ожидается, что на производстве специалисты по рекламе будут программно собирать и преобразовывать отчеты.
Давайте скопируем отчет JSON в «Тело отчета» из chrome://private-aggregation-internals .
В этом примере мы используем vim, поскольку используем Linux. Но вы можете использовать любой текстовый редактор, какой захотите.
vim report.json
Вставьте отчет в report.json и сохраните файл.
3.1.3. Преобразование отчетов в AVRO
Отчеты, полученные от .well-known конечных точек, имеют формат JSON, и их необходимо преобразовать в формат отчетов AVRO. Получив отчет в формате JSON, перейдите туда, где хранится report.json , и используйте aggregatable_report_converter.jar , чтобы создать сводный отчет отладки. В результате в вашем текущем каталоге будет создан сводный отчет с именем report.avro .
java -jar aggregatable_report_converter.jar \
--request_type convertToAvro \
--input_file report.json
3.1.4. Создать выходной_домен AVRO
Чтобы создать файл output_domain.avro , вам потребуются ключи сегмента, которые можно получить из отчетов.
Ключи ведра разработаны adTech. Однако в этом случае демонстрационная версия Privacy Sandbox сайта создает ключи корзины. Поскольку частное агрегирование для этого сайта находится в режиме отладки, мы можем использовать debug_cleartext_payload из «Тела отчета», чтобы получить ключ сегмента.
Продолжайте и скопируйте debug_cleartext_payload из тела отчета.
Откройте goo.gle/ags-payload-decoder , вставьте свой debug_cleartext_payload в поле «ВВОД» и нажмите «Декодировать».
Страница возвращает десятичное значение ключа сегмента. Ниже приведен образец ключа от ведра.
Теперь, когда у нас есть ключ сегмента, давайте создадим output_domain.avro в той же папке, над которой мы работали. Убедитесь, что вы заменили ключ сегмента полученным ключом сегмента.
java -jar aggregatable_report_converter.jar \
--request_type createDomainAvro \
--bucket_key <bucket key>
Скрипт создает файл output_domain.avro в вашей текущей папке.
3.1.5. Переместить отчеты в корзину Cloud Storage
После создания отчетов AVRO и выходного домена приступайте к перемещению отчетов и выходного домена в корзину в облачном хранилище (что вы отметили в предварительном условии 1.6).
Если в вашей локальной среде установлен интерфейс командной строки gcloud, используйте приведенные ниже команды, чтобы скопировать файлы в соответствующие папки.
gcloud storage cp report.avro gs://<bucket_name>/reports/
gcloud storage cp output_domain.avro gs://<bucket_name>/output_domain/
В противном случае загрузите файлы в корзину вручную. Создайте папку с названием «reports» и загрузите туда файл report.avro . Создайте папку с именем «output_domains» и загрузите туда файл output_domain.avro .
3.2. Использование службы агрегации
Напомним, что в предварительном условии 1.8 вы выбрали cURL или Postman для отправки запросов API к конечным точкам службы агрегации. Ниже вы найдете инструкции для обоих вариантов.
Если ваше задание завершается с ошибкой, ознакомьтесь с нашей документацией по устранению неполадок на GitHub, чтобы получить дополнительную информацию о том, как действовать дальше.
3.2.1. Использование createJob Endpoint для пакетной обработки
Используйте приведенные ниже инструкции cURL или Postman, чтобы создать задание.
КУЛЬ
В своем «Терминале» создайте файл тела запроса ( body.json ) и вставьте его ниже. Обязательно обновите значения заполнителей. Обратитесь к этой документации API для получения дополнительной информации о том, что представляет собой каждое поле.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
Выполните приведенный ниже запрос. Замените заполнители в URL-адресе запроса cURL значениями из frontend_service_cloudfunction_url , которые выводятся после успешного завершения развертывания Terraform в предварительном условии 1.6.
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-d @body.json \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/createJob
Вы должны получить ответ HTTP 202, как только запрос будет принят службой агрегации. Другие возможные коды ответа описаны в спецификациях API .
Почтальон
Для конечной точки createJob требуется тело запроса, чтобы предоставить службе агрегации расположение и имена файлов агрегируемых отчетов, выходных доменов и сводных отчетов.
Перейдите на вкладку «Тело» запроса createJob :
Замените заполнители в предоставленном JSON. Дополнительную информацию об этих полях и о том, что они представляют, можно найти в документации API .
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<domain of reporting origin(s) of report>", // Only one of attribution_report_to or reporting_site is required as of v2.7.0
"report_error_threshold_percentage": "10",
"debug_run": "true"
}
}
«Отправьте» запрос API createJob :
Код ответа можно найти в нижней половине страницы:
Вы должны получить ответ HTTP 202, как только запрос будет принят службой агрегации. Другие возможные коды ответа описаны в спецификациях API .
3.2.2. Использование конечной точки getJob для получения статуса пакета
Используйте приведенные ниже инструкции cURL или Postman, чтобы получить работу.
КУЛЬ
Выполните приведенный ниже запрос в своем терминале. Замените заполнители в URL-адресе значениями из frontend_service_cloudfunction_url , который является тем же URL-адресом, который вы использовали для запроса createJob . В качестве «job_request_id» используйте значение из задания, которое вы создали с помощью конечной точки createJob .
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<environment>-<region>-frontend-service-<cloud-function-id>-uc.a.run.app/v1alpha/getJob?job_request_id=<job_request_id>
Результат должен вернуть статус вашего запроса задания со статусом HTTP 200. Запрос «Тело» содержит необходимую информацию, такую как job_status , return_message и error_messages (если задание выполнено с ошибкой).
Почтальон
Чтобы проверить статус запроса на работу, вы можете использовать конечную точку getJob . В разделе «Параметры» запроса getJob обновите значение job_request_id на job_request_id , отправленное в запросе createJob .
«Отправить» запрос getJob :
Результат должен вернуть статус вашего запроса задания со статусом HTTP 200. Запрос «Тело» содержит необходимую информацию, такую как job_status , return_message и error_messages (если задание выполнено с ошибкой).
3.2.3. Просмотр сводного отчета
Как только вы получите сводный отчет в выходной сегмент Cloud Storage, вы сможете загрузить его в свою локальную среду. Сводные отчеты имеют формат AVRO и могут быть преобразованы обратно в JSON. Вы можете использовать aggregatable_report_converter.jar для чтения отчета с помощью приведенной ниже команды.
java -jar aggregatable_report_converter.jar \
--request_type convertToJson \
--input_file <summary_report_avro>
Это возвращает JSON агрегированных значений каждого ключа сегмента, который выглядит примерно так, как показано ниже.
Если ваш запрос createJob включает в debug_run значение true, вы можете получить сводный отчет в папке отладки, которая находится в файле output_data_blob_prefix . Отчет имеет формат AVRO и может быть преобразован с помощью приведенной выше команды в JSON.
Отчет содержит ключ сегмента, нешумированную метрику и шум, который добавляется к нешумовой метрике для формирования сводного отчета. Отчет аналогичен приведенному ниже.
Аннотации также содержат «in_reports» и/или «in_domain», что означает:
- in_reports — ключ сегмента доступен внутри агрегируемых отчетов.
- in_domain — ключ сегмента доступен внутри файла AVRO выходного_домена.
Кодлаб завершен!
Краткое описание: вы развернули службу агрегации в своей облачной среде, собрали отчет об отладке, создали файл выходного домена, сохранили эти файлы в корзине облачного хранилища и успешно выполнили задание!
Следующие шаги: продолжайте использовать службу агрегации в своей среде или удалите только что созданные облачные ресурсы, следуя инструкциям по очистке на шаге 4.
4. 4. Очистка
Чтобы удалить ресурсы, созданные для службы агрегации через Terraform, используйте команду уничтожения в папках adtech_setup и dev (или другой среды):
$ cd <repository_root>/terraform/gcp/environments/adtech_setup
$ terraform destroy
$ cd <repository_root>/terraform/gcp/environments/dev
$ terraform destroy
Чтобы удалить корзину Cloud Storage, содержащую ваши агрегированные и сводные отчеты:
$ gcloud storage buckets delete gs://my-bucket
Вы также можете вернуть настройки файлов cookie Chrome из предварительного условия 1.2 в предыдущее состояние.
5. 5. Приложение
Пример файла adtech_setup.auto.tfvars
/**
* Copyright 2023 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
project = "my-project-id"
# Required to generate identity token for access of Adtech Services API endpoints
service_account_token_creator_list = ["user:me@email.com"]
# Uncomment the below line if you like Terraform to create an Artifact registry repository
# for self-build container artifacts. "artifact_repo_location" defaults to "us".
artifact_repo_name = "my-ags-artifacts"
# Note: Either one of [1] or [2] must be uncommented.
# [1] Uncomment below lines if you like Terraform grant needed permissions to
# pre-existing service accounts
# deploy_service_account_email = "<YourDeployServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# worker_service_account_email = "<YourWorkerServiceAccountName>@<ProjectID>.iam.gserviceaccount.com"
# [2] Uncomment below lines if you like Terraform to create service accounts
# and needed permissions granted e.g "deploy-sa" or "worker-sa"
deploy_service_account_name = "deploy-sa"
worker_service_account_name = "worker-sa"
# Uncomment the below line if you want Terraform to create the
# below bucket. "data_bucket_location" defaults to "us".
data_bucket_name = "my-ags-data"
# Uncomment the below lines if you want to specify service account customer role names
# deploy_sa_role_name = "<YourDeploySACustomRole>"
# worker_sa_role_name = "<YourWorkerSACustomRole>"
Пример файла dev.auto.tfvars
/**
* Copyright 2022 Google LLC
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
# Example values required by job_service.tf
#
# These values should be modified for each of your environments.
region = "us-central1"
region_zone = "us-central1-c"
project_id = "my-project-id"
environment = "operator-demo-env"
# Co-locate your Cloud Spanner instance configuration with the region above.
# https://cloud.google.com/spanner/docs/instance-configurations#regional-configurations
spanner_instance_config = "regional-us-central1"
# Adjust this based on the job load you expect for your deployment.
# Monitor the spanner instance utilization to decide on scale out / scale in.
# https://console.cloud.google.com/spanner/instances
spanner_processing_units = 100
# Uncomment the line below at your own risk to disable Spanner database protection.
# This needs to be set to false and applied before destroying all resources is possible.
spanner_database_deletion_protection = false
instance_type = "n2d-standard-8" # 8 cores, 32GiB
# Container image location that packages the job service application
# If not set otherwise, uncomment and edit the line below:
#worker_image = "<location>/<project>/<repository>/<image>:<tag or digest>"
# Service account created and onboarded for worker
user_provided_worker_sa_email = "worker-sa@my-project-id.iam.gserviceaccount.com"
min_worker_instances = 1
max_worker_instances = 20