আপনি সফলভাবে অ্যাগ্রিগেশন পরিষেবা স্থাপন করার পরে, আপনি পরিষেবার সাথে ইন্টারঅ্যাক্ট করতে createJob এবং getJob এন্ডপয়েন্ট ব্যবহার করতে পারেন। নিম্নলিখিত চিত্রটি এই দুটি প্রান্তের জন্য স্থাপনার আর্কিটেকচারের একটি চাক্ষুষ উপস্থাপনা প্রদান করে:
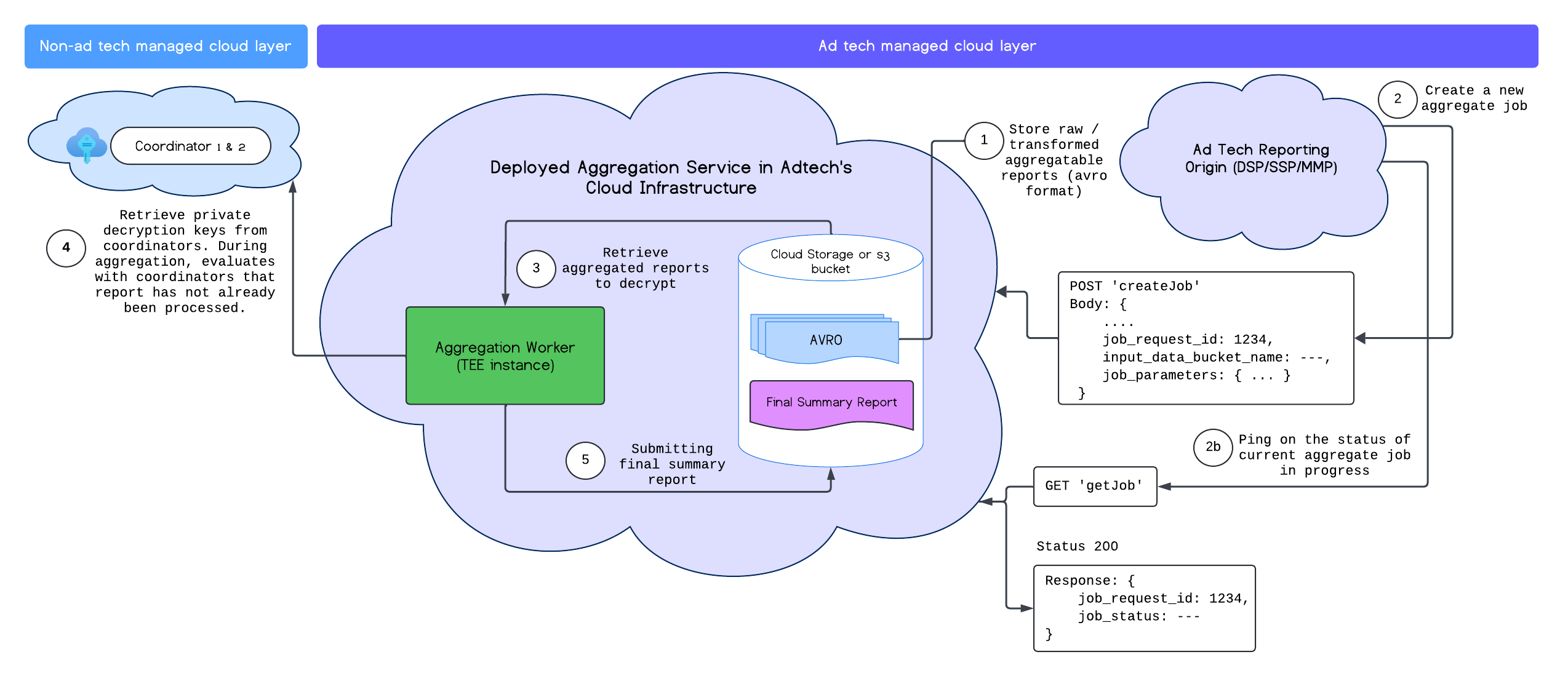
আপনি Aggregation Service API ডকুমেন্টেশনে createJob এবং getJob এন্ডপয়েন্ট সম্পর্কে আরও পড়তে পারেন।
একটি চাকরি তৈরি করুন
একটি চাকরি তৈরি করতে, createJob এন্ডপয়েন্টে একটি POST অনুরোধ পাঠান। bash POST https://<api-gateway>/stage/v1alpha/createJob -+ createJob এর জন্য রিকোয়েস্ট বডির একটি উদাহরণ:
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
একটি সফল চাকরি সৃষ্টির ফলে একটি 202 HTTP স্ট্যাটাস কোড হয়।
মনে রাখবেন যে reporting_site এবং attribution_report_to পারস্পরিক একচেটিয়া এবং শুধুমাত্র একটি প্রয়োজন।
আপনি job_parameters এ debug_run যোগ করে একটি ডিবাগ কাজের অনুরোধ করতে পারেন। ডিবাগ মোড সম্পর্কে আরও তথ্যের জন্য, আমাদের সমষ্টি ডিবাগ রান ডকুমেন্টেশন দেখুন।
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
ক্ষেত্র অনুরোধ
| প্যারামিটার | টাইপ | বর্ণনা |
|---|---|---|
job_request_id | স্ট্রিং | এটি একটি বিজ্ঞাপন প্রযুক্তি তৈরি করা অনন্য শনাক্তকারী যা 128 বা তার কম অক্ষর সহ ASCII অক্ষর হওয়া উচিত। এটি ব্যাচের কাজের অনুরোধ শনাক্ত করে এবং বিজ্ঞাপন প্রযুক্তির ক্লাউড স্টোরেজে হোস্ট করা `ইনপুট_ডেটা_বাকেট_নাম`-এ নির্দিষ্ট ইনপুট বাকেট থেকে `ইনপুট_ডেটা_ব্লব_প্রিফিক্স`-এ নির্দিষ্ট করা সমস্ত সমষ্টিগত AVRO রিপোর্ট গ্রহণ করে। অক্ষর: `az, AZ, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~ |
input_data_blob_prefix | স্ট্রিং | এই বালতি পথ. একক ফাইলের জন্য, আপনি পাথ ব্যবহার করতে পারেন। একাধিক ফাইলের জন্য, আপনি পথের উপসর্গ ব্যবহার করতে পারেন। উদাহরণ: ফোল্ডার/ফাইল ফোল্ডার/file1.avro, ফোল্ডার/file/file1.avro এবং ফোল্ডার/file1/test/file2.avro থেকে সমস্ত রিপোর্ট সংগ্রহ করে। |
input_data_bucket_name | স্ট্রিং | এটি ইনপুট ডেটা বা সমষ্টিগত প্রতিবেদনের জন্য স্টোরেজ বালতি। এটি বিজ্ঞাপন প্রযুক্তির ক্লাউড স্টোরেজে রয়েছে। |
output_data_blob_prefix | স্ট্রিং | এটি বালতিতে আউটপুট পথ। একটি একক আউটপুট ফাইল সমর্থিত। |
output_data_bucket_name | স্ট্রিং | এটি হল স্টোরেজ বাকেট যেখানে output_data পাঠানো হয়। এটি বিজ্ঞাপন প্রযুক্তির ক্লাউড স্টোরেজে বিদ্যমান। |
job_parameters | অভিধান | প্রয়োজনীয় ক্ষেত্র। এই ক্ষেত্রটিতে বিভিন্ন ক্ষেত্র রয়েছে যেমন:
|
job_parameters.output_domain_blob_prefix | স্ট্রিং | input_data_blob_prefix এর অনুরূপ, এটি output_domain_bucket_name এর পথ যেখানে আপনার আউটপুট ডোমেন AVRO অবস্থিত। একাধিক ফাইলের জন্য, আপনি পথের উপসর্গ ব্যবহার করতে পারেন। একবার অ্যাগ্রিগেশন সার্ভিস ব্যাচ সম্পূর্ণ করলে, সারাংশ রিপোর্ট তৈরি করা হয় এবং আউটপুট বাকেট output_data_bucket_name এ output_data_blob_prefix নামের সাথে স্থাপন করা হয়। |
job_parameters.output_domain_bucket_name | স্ট্রিং | এটি আপনার আউটপুট ডোমেন AVRO ফাইলের স্টোরেজ বালতি। এটি বিজ্ঞাপন প্রযুক্তির ক্লাউড স্টোরেজে রয়েছে। |
job_parameters.attribution_report_to | স্ট্রিং | এই মানটি 'রিপোর্টিং_সাইট'-এর জন্য পারস্পরিকভাবে একচেটিয়া। এটি সেই রিপোর্টিং ইউআরএল বা রিপোর্টিং অরিজিন যেখানে রিপোর্টটি গৃহীত হয়েছিল। সাইটের মূলটি অ্যাগ্রিগেশন সার্ভিস অনবোর্ডিং-এ নিবন্ধিত। |
job_parameters.reporting_site | স্ট্রিং | attribution_report_to তে পারস্পরিকভাবে একচেটিয়া। এটি রিপোর্টিং URL এর হোস্টনাম বা রিপোর্টিং মূল যেখানে প্রতিবেদনটি গৃহীত হয়েছিল৷ সাইটের মূলটি অ্যাগ্রিগেশন সার্ভিস অনবোর্ডিং-এ নিবন্ধিত। দ্রষ্টব্য: আপনি একটি একক অনুরোধের মধ্যে বিভিন্ন উত্স সহ একাধিক প্রতিবেদন জমা দিতে পারেন, তবে শর্ত থাকে যে সমস্ত উত্স এই প্যারামিটারে নির্দিষ্ট করা একই রিপোর্টিং সাইটের অন্তর্গত। |
job_parameters.debug_privacy_epsilon | ফ্লোটিং পয়েন্ট, ডাবল | ঐচ্ছিক ক্ষেত্র। কোনো মান পাস না হলে, ডিফল্ট মান 10। 0 থেকে 64 পর্যন্ত একটি মান ব্যবহার করা যেতে পারে। |
job_parameters.report_error_threshold_percentage | ডাবল | ঐচ্ছিক ক্ষেত্র। এটি কাজ ব্যর্থ হওয়ার আগে অনুমোদিত ব্যর্থ রিপোর্টের সর্বাধিক শতাংশ। খালি থাকলে, ডিফল্ট মান 10%। |
job_parameters.input_report_count | দীর্ঘ মান | ঐচ্ছিক ক্ষেত্র। কাজের জন্য ইনপুট ডেটা হিসাবে প্রদত্ত রিপোর্টের মোট সংখ্যা। report_error_threshold_percentage এর সাথে একত্রে এই মানটি যখন ত্রুটির কারণে প্রতিবেদনগুলি বাদ দেওয়া হয় তখন প্রাথমিক কাজের ব্যর্থতা সক্ষম করে। |
job_parameters.filtering_ids | স্ট্রিং | ঐচ্ছিক ক্ষেত্র। একটি কমা দ্বারা পৃথক স্বাক্ষরবিহীন ফিল্টারিং আইডিগুলির একটি তালিকা৷ ম্যাচিং ফিল্টারিং আইডি ছাড়া অন্য সব অবদান ফিল্টার আউট করা হয়. (যেমন "filtering_ids": "12345,34455,12" )। ডিফল্ট মান 0। |
job_parameters.debug_run | বুলিয়ান | ঐচ্ছিক ক্ষেত্র। একটি ডিবাগ রান নির্বাহ করার সময়, ডোমেইন ইনপুট এবং/অথবা রিপোর্টে কোন কী উপস্থিত রয়েছে তা নির্দেশ করার জন্য নয়েজড এবং আন-নোইজড ডিবাগ সারাংশ রিপোর্ট এবং টীকা যোগ করা হয়। অতিরিক্তভাবে, ব্যাচ জুড়ে সদৃশগুলিও প্রয়োগ করা হয় না। মনে রাখবেন যে ডিবাগ রান শুধুমাত্র সেই রিপোর্টগুলিকে বিবেচনা করে যেগুলির পতাকা "debug_mode": "enabled" আছে। v2.10.0 অনুযায়ী, ডিবাগ রান প্রাইভেসি বাজেট ব্যবহার করে না । |
চাকরি পান
যখন একটি বিজ্ঞাপন প্রযুক্তি অনুরোধ করা ব্যাচের অবস্থা জানতে চায় তখন তারা getJob এন্ডপয়েন্টে কল করতে পারে। job_request_id প্যারামিটার সহ একটি HTTPS GET অনুরোধ ব্যবহার করে getJob এন্ডপয়েন্টকে কল করা হয়।
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
আপনার একটি প্রতিক্রিয়া পাওয়া উচিত যা যেকোনো ত্রুটির বার্তা সহ কাজের স্থিতি ফেরত দেয়:
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
প্রতিক্রিয়া ক্ষেত্র
| প্যারামিটার | টাইপ | বর্ণনা |
|---|---|---|
job_request_id | স্ট্রিং | এটি একটি অনন্য চাকরি/ব্যাচ আইডি যা createJob অনুরোধে উল্লেখ করা হয়েছে। |
job_status | স্ট্রিং | এটি চাকরির অনুরোধের অবস্থা। |
request_received_at | স্ট্রিং | যে সময় রিকুয়েস্ট পেয়েছি। |
request_updated_at | স্ট্রিং | চাকরির সর্বশেষ আপডেটের সময়। |
input_data_blob_prefix | স্ট্রিং | এটি হল ইনপুট ডেটা উপসর্গ যা createJob এ সেট করা হয়েছিল। |
input_data_bucket_name | স্ট্রিং | এটি হল বিজ্ঞাপন প্রযুক্তির ইনপুট ডেটা বাকেট যেখানে সমষ্টিগত প্রতিবেদনগুলি সংরক্ষণ করা হয়৷ এই ক্ষেত্র createJob এ সেট করা আছে। |
output_data_blob_prefix | স্ট্রিং | এটি আউটপুট ডেটা উপসর্গ যা createJob এ সেট করা হয়েছিল। |
output_data_bucket_name | স্ট্রিং | এটি হল বিজ্ঞাপন প্রযুক্তির আউটপুট ডেটা বাকেট যেখানে জেনারেট করা সারাংশ প্রতিবেদনগুলি সংরক্ষণ করা হয়৷ এই ক্ষেত্র createJob এ সেট করা আছে। |
request_processing_started_at | স্ট্রিং | যে সময় সর্বশেষ প্রক্রিয়াকরণ প্রচেষ্টা শুরু হয়েছে। এটি কাজের সারিতে অপেক্ষার সময় বাদ দেয়। (মোট প্রক্রিয়াকরণের সময় = request_updated_at - request_processing_started_at ) |
result_info | অভিধান | এটি createJob অনুরোধের ফলাফল এবং এতে উপলব্ধ সমস্ত তথ্য রয়েছে। এটি return_code , return_message , finished_at এবং error_summary মান দেখায়। |
result_info.return_code | স্ট্রিং | কাজের ফলাফল রিটার্ন কোড। এগ্রিগেশন সার্ভিসে কোনো সমস্যা থাকলে সমস্যা সমাধানের জন্য এই তথ্যের প্রয়োজন। |
result_info.return_message | স্ট্রিং | হয় সাফল্য বা ব্যর্থতার বার্তা কাজের ফলে ফিরে আসে। এগ্রিগেশন পরিষেবা সংক্রান্ত সমস্যা সমাধানের জন্যও এই তথ্যের প্রয়োজন। |
result_info.error_summary | অভিধান | যে ত্রুটিগুলো চাকরি থেকে ফিরে আসে। এতে রিপোর্টের সংখ্যা সহ ত্রুটির ধরন রয়েছে। |
result_info.finished_at | টাইমস্ট্যাম্প | টাইমস্ট্যাম্প কাজ সমাপ্তি নির্দেশ করে। |
result_info.error_summary.error_counts | তালিকা | এটি একই ত্রুটি বার্তার সাথে ব্যর্থ হওয়া রিপোর্টের সংখ্যা সহ ত্রুটি বার্তাগুলির একটি তালিকা প্রদান করে। প্রতিটি ত্রুটি গণনায় একটি বিভাগ, error_count এবং description থাকে। |
result_info.error_summary.error_messages | তালিকা | এটি রিপোর্ট থেকে ত্রুটি বার্তাগুলির একটি তালিকা প্রদান করে যা প্রক্রিয়া করতে ব্যর্থ হয়েছে৷ |
job_parameters | অভিধান | এটি createJob অনুরোধে প্রদত্ত কাজের পরামিতি ধারণ করে। প্রাসঙ্গিক বৈশিষ্ট্য যেমন `output_domain_blob_prefix` এবং `output_domain_bucket_name`। |
job_parameters.attribution_report_to | স্ট্রিং | reporting_site জন্য পারস্পরিকভাবে একচেটিয়া। এটি রিপোর্টিং ইউআরএল বা যেখানে প্রতিবেদনটি গৃহীত হয়েছিল তার উৎস। মূল হল সেই সাইটের অংশ যা অ্যাগ্রিগেশন সার্ভিস অনবোর্ডিং-এ নিবন্ধিত। এটি createJob অনুরোধে উল্লেখ করা হয়েছে। |
job_parameters.reporting_site | স্ট্রিং | attribution_report_to তে পারস্পরিকভাবে একচেটিয়া। এটি রিপোর্টিং ইউআরএলের হোস্টনাম বা যেখানে রিপোর্টটি গৃহীত হয়েছিল তার উৎস। মূল হল সেই সাইটের অংশ যা অ্যাগ্রিগেশন সার্ভিস অনবোর্ডিং-এ নিবন্ধিত। মনে রাখবেন যে আপনি একই অনুরোধে একাধিক প্রতিবেদনের উত্স সহ প্রতিবেদন জমা দিতে পারেন যতক্ষণ না সমস্ত প্রতিবেদনের উত্স এই প্যারামিটারে উল্লিখিত একই সাইটের অন্তর্গত। এটি createJob অনুরোধে উল্লেখ করা হয়েছে। অতিরিক্তভাবে, নিশ্চিত করুন যে বালতিতে শুধুমাত্র সেই রিপোর্ট রয়েছে যা আপনি চাকরি তৈরির সময় একত্রিত করতে চান। কাজের প্যারামিটারে উল্লিখিত রিপোর্টিং সাইটের সাথে মেলে রিপোর্টিং উত্স সহ ইনপুট ডেটা বাকেটে যোগ করা যেকোনো প্রতিবেদন প্রক্রিয়া করা হয়। অ্যাগ্রিগেশন সার্ভিস শুধুমাত্র ডেটা বাকেটের মধ্যে থাকা রিপোর্টগুলিকে বিবেচনা করে যা চাকরির নিবন্ধিত রিপোর্টিং মূলের সাথে মেলে। উদাহরণস্বরূপ, যদি নিবন্ধিত মূলটি https://exampleabc.com হয় তবে শুধুমাত্র https://exampleabc.com থেকে রিপোর্টগুলি অন্তর্ভুক্ত করা হয়, এমনকি যদি বাকেটটিতে সাবডোমেনগুলি থেকে রিপোর্ট থাকে ( https://1.exampleabc.com , ইত্যাদি ) বা সম্পূর্ণ ভিন্ন ডোমেন ( https://3.examplexyz.com )। |
job_parameters.debug_privacy_epsilon | ফ্লোটিং পয়েন্ট, ডাবল | ঐচ্ছিক ক্ষেত্র। কোন মান পাস না হলে, 10 এর ডিফল্ট মান ব্যবহার করা হয়। মানগুলি 0 থেকে 64 পর্যন্ত হতে পারে৷ এই মানটি createJob অনুরোধে উল্লেখ করা হয়েছে৷ |
job_parameters.report_error_threshold_percentage | ডাবল | ঐচ্ছিক ক্ষেত্র। এটি এমন রিপোর্টের থ্রেশহোল্ড শতাংশ যা চাকরির ব্যর্থতার আগে ব্যর্থ হতে পারে। যদি কোন মান বরাদ্দ না করা হয়, 10% এর ডিফল্ট মান ব্যবহার করা হয়। এটি createJob অনুরোধে উল্লেখ করা হয়েছে। |
job_parameters.input_report_count | দীর্ঘ মান | ঐচ্ছিক ক্ষেত্র। এই কাজের জন্য ইনপুট ডেটা হিসাবে দেওয়া রিপোর্টের মোট সংখ্যা। এই মানের সাথে মিলিত `report_error_threshold_percentage`, যদি ত্রুটির কারণে উল্লেখযোগ্য সংখ্যক প্রতিবেদন বাদ দেওয়া হয় তাহলে প্রাথমিক কাজের ব্যর্থতাকে ট্রিগার করে। এই সেটিংটি `createJob` অনুরোধে উল্লেখ করা হয়েছে। |
job_parameters.filtering_ids | স্ট্রিং | ঐচ্ছিক ক্ষেত্র। কমা দ্বারা পৃথক স্বাক্ষরবিহীন ফিল্টারিং আইডিগুলির একটি তালিকা৷ ম্যাচিং ফিল্টারিং আইডি ছাড়া অন্য সব অবদান ফিল্টার আউট করা হয়. এটি createJob অনুরোধে উল্লেখ করা হয়েছে। (যেমন "filtering_ids":"12345,34455,12" । ডিফল্ট মান হল "0"।) |