پس از استقرار موفقیت آمیز سرویس Aggregation، می توانید از نقاط پایانی createJob و getJob برای تعامل با سرویس استفاده کنید. نمودار زیر یک نمایش بصری از معماری استقرار برای این دو نقطه پایانی ارائه می دهد:
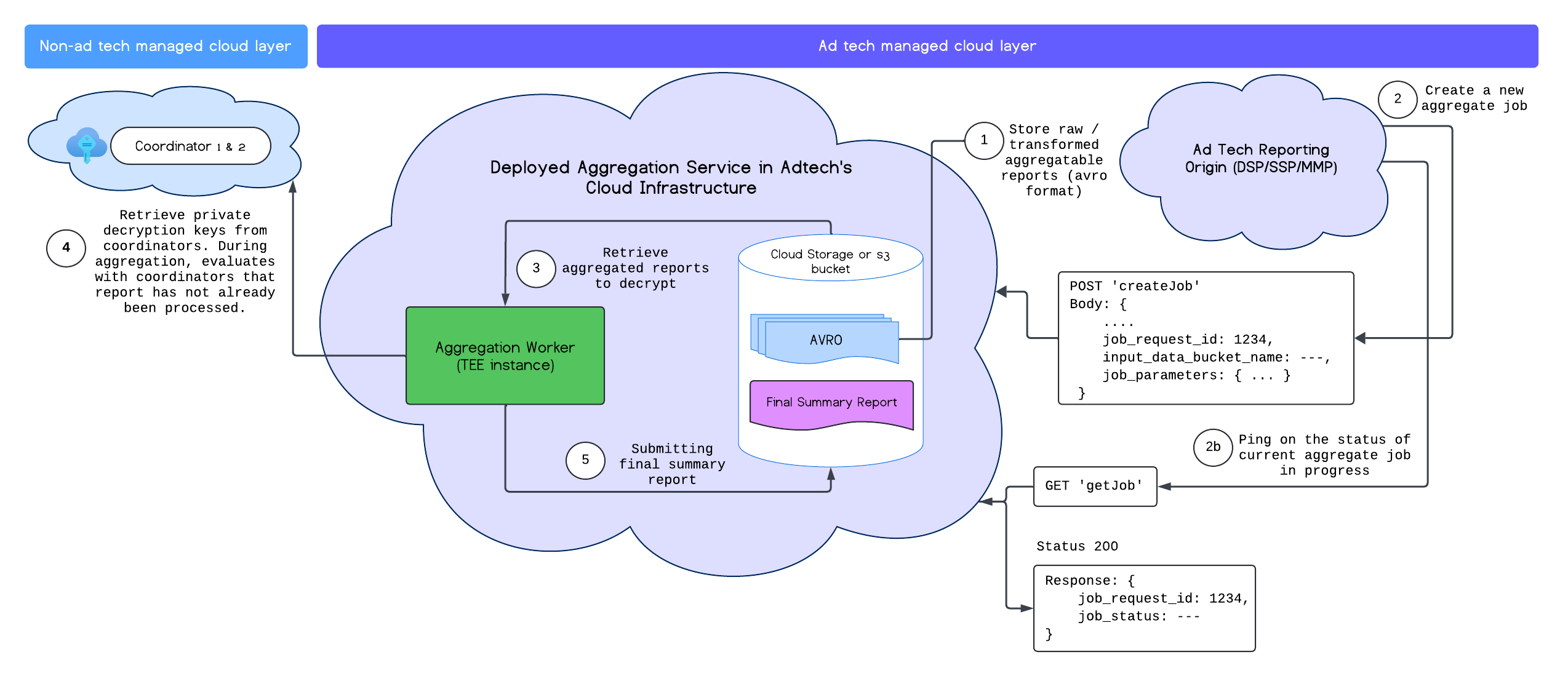
می توانید اطلاعات بیشتری در مورد نقاط پایانی createJob و getJob در اسناد Aggregation Service API بخوانید.
شغل ایجاد کنید
برای ایجاد یک کار، یک درخواست POST به نقطه پایانی createJob ارسال کنید. bash POST https://<api-gateway>/stage/v1alpha/createJob -+ نمونه ای از بدنه درخواست برای createJob :
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
ایجاد شغل موفق منجر به کد وضعیت HTTP 202 می شود.
توجه داشته باشید که reporting_site و attribution_report_to متقابلاً انحصاری هستند و فقط یکی مورد نیاز است.
همچنین می توانید با افزودن debug_run به job_parameters یک کار اشکال زدایی درخواست کنید. برای اطلاعات بیشتر در مورد حالت اشکال زدایی، مستندات اجرای اشکال زدایی تجمع ما را بررسی کنید.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
فیلدهای درخواست
| پارامتر | تایپ کنید | توضیحات |
|---|---|---|
job_request_id | رشته | این یک شناسه منحصر به فرد ایجاد شده توسط فناوری تبلیغات است که باید حروف ASCII با 128 کاراکتر یا کمتر باشد. این درخواست کار دستهای را شناسایی میکند و همه گزارشهای AVRO جمعآوریشده در «input_data_blob_prefix» را از سطل ورودی مشخصشده در «input_data_bucket_name» که در فضای ذخیرهسازی ابری فناوری آگهی میزبانی میشود، میگیرد. کاراکترها: `az, AZ, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~ |
input_data_blob_prefix | رشته | این مسیر سطل است. برای فایل های تک می توانید از مسیر استفاده کنید. برای چندین فایل، می توانید از پیشوند موجود در مسیر استفاده کنید. مثال: پوشه/فایل همه گزارشها را از folder/file1.avro، folder/file/file1.avro و folder/file1/test/file2.avro جمعآوری میکند. |
input_data_bucket_name | رشته | این سطل ذخیره سازی برای داده های ورودی یا گزارش های جمع آوری است. این در فضای ذخیره سازی ابری فناوری تبلیغات است. |
output_data_blob_prefix | رشته | این مسیر خروجی در سطل است. یک فایل خروجی واحد پشتیبانی می شود. |
output_data_bucket_name | رشته | این سطل ذخیره سازی است که output_data در آن ارسال می شود. این در حافظه ابری فناوری تبلیغات وجود دارد. |
job_parameters | فرهنگ لغت | فیلد الزامی این فیلد شامل فیلدهای مختلفی است از جمله:
|
job_parameters.output_domain_blob_prefix | رشته | مشابه input_data_blob_prefix ، این مسیر در output_domain_bucket_name است که دامنه خروجی شما AVRO در آن قرار دارد. برای چندین فایل، می توانید از پیشوند موجود در مسیر استفاده کنید. هنگامی که سرویس جمعآوری دسته را تکمیل کرد، گزارش خلاصه ایجاد میشود و در سطل خروجی output_data_bucket_name با نام output_data_blob_prefix قرار میگیرد. |
job_parameters.output_domain_bucket_name | رشته | این سطل ذخیره سازی فایل AVRO دامنه خروجی شما است. این در فضای ذخیره سازی ابری فناوری تبلیغات است. |
job_parameters.attribution_report_to | رشته | این مقدار متقابلاً منحصر به «سایت_گزارشدهی» است. این نشانی وب گزارش یا مبدا گزارشی است که گزارش از آنجا دریافت شده است. منبع سایت در Aggregation Service Onboarding ثبت شده است. |
job_parameters.reporting_site | رشته | متقابلاً منحصر به attribution_report_to است. این نام میزبان نشانی وب گزارش یا مبدا گزارشی است که گزارش از آنجا دریافت شده است. منبع سایت در Aggregation Service Onboarding ثبت شده است. توجه: شما می توانید چندین گزارش با مبداهای مختلف در یک درخواست ارسال کنید، مشروط بر اینکه همه مبدا متعلق به یک سایت گزارش مشخص شده در این پارامتر باشد. |
job_parameters.debug_privacy_epsilon | نقطه شناور، دوبل | فیلد اختیاری اگر مقداری ارسال نشود، مقدار پیشفرض 10 است. میتوان از مقدار 0 تا 64 استفاده کرد. |
job_parameters.report_error_threshold_percentage | دوبل | فیلد اختیاری این حداکثر درصد گزارش های ناموفق مجاز قبل از شکست کار است. اگر خالی بماند، مقدار پیش فرض 10٪ است. |
job_parameters.input_report_count | ارزش طولانی | فیلد اختیاری تعداد کل گزارش های ارائه شده به عنوان داده های ورودی برای کار. این مقدار، در ارتباط با report_error_threshold_percentage شکست زودهنگام شغلی را در زمانی که گزارشها به دلیل خطا حذف میشوند، ممکن میسازد. |
job_parameters.filtering_ids | رشته | فیلد اختیاری فهرستی از شناسههای فیلتر بدون امضا که با کاما از هم جدا شدهاند. همه مشارکتهای غیر از شناسه فیلتر منطبق فیلتر میشوند. (به عنوان مثال "filtering_ids": "12345,34455,12" ). مقدار پیش فرض 0 است. |
job_parameters.debug_run | بولی | فیلد اختیاری هنگام اجرای یک اجرای اشکال زدایی، گزارش های خلاصه اشکال زدایی نویز و بدون نویز و حاشیه نویسی اضافه می شود تا مشخص شود کدام کلیدها در ورودی و/یا گزارش های دامنه وجود دارند. علاوه بر این، موارد تکراری در دستهها نیز اجرا نمیشوند. توجه داشته باشید که اجرای اشکالزدایی فقط گزارشهایی را در نظر میگیرد که دارای پرچم "debug_mode": "enabled" هستند. از نسخه 2.10.0، اجرای اشکال زدایی بودجه حفظ حریم خصوصی را مصرف نمی کند. |
کار پیدا کن
هنگامی که یک فناوری تبلیغات می خواهد از وضعیت یک دسته درخواستی مطلع شود، می تواند با نقطه پایانی getJob تماس بگیرد. نقطه پایانی getJob با استفاده از یک درخواست HTTPS GET همراه با پارامتر job_request_id فراخوانی می شود.
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
شما باید پاسخی دریافت کنید که وضعیت شغلی را همراه با هر پیام خطا برمی گرداند:
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
فیلدهای پاسخ
| پارامتر | تایپ کنید | توضیحات |
|---|---|---|
job_request_id | رشته | این شناسه کار/دسته منحصر به فرد است که در درخواست createJob مشخص شده است. |
job_status | رشته | این وضعیت درخواست کار است. |
request_received_at | رشته | زمانی که درخواست دریافت شد. |
request_updated_at | رشته | زمانی که کار آخرین بار به روز شد. |
input_data_blob_prefix | رشته | این پیشوند داده ورودی است که در createJob تنظیم شده است. |
input_data_bucket_name | رشته | این سطل داده های ورودی فناوری تبلیغات است که در آن گزارش های جمع آوری شده ذخیره می شود. این فیلد در createJob تنظیم شده است. |
output_data_blob_prefix | رشته | این پیشوند داده خروجی است که در createJob تنظیم شده است. |
output_data_bucket_name | رشته | این سطل دادههای خروجی فناوری تبلیغات است که گزارشهای خلاصه تولید شده در آن ذخیره میشوند. این فیلد در createJob تنظیم شده است. |
request_processing_started_at | رشته | زمانی که آخرین تلاش برای پردازش آغاز شده است. این شامل زمان انتظار در صف کار نمی شود. (کل زمان پردازش = request_updated_at - request_processing_started_at ) |
result_info | فرهنگ لغت | این نتیجه درخواست createJob است و شامل تمام اطلاعات موجود است. این مقادیر return_code ، return_message ، finished_at و error_summary را نشان می دهد. |
result_info.return_code | رشته | کد بازگشت نتیجه کار این اطلاعات برای عیب یابی در صورت وجود مشکل در سرویس تجمع مورد نیاز است. |
result_info.return_message | رشته | پیام موفقیت یا شکست در نتیجه کار برگشت داده شد. این اطلاعات همچنین برای عیب یابی مشکلات مربوط به سرویس تجمع مورد نیاز است. |
result_info.error_summary | فرهنگ لغت | خطاهایی که از کار برمی گردند. این شامل تعداد گزارش ها به همراه نوع خطاهایی است که با آن مواجه شده اند. |
result_info.finished_at | مهر زمان | مهر زمانی که نشان دهنده اتمام کار است. |
result_info.error_summary.error_counts | فهرست کنید | این لیستی از پیام های خطا را به همراه تعداد گزارش هایی که با همان پیام خطا ناموفق بوده اند، برمی گرداند. هر تعداد خطا شامل یک دسته، error_count و description است. |
result_info.error_summary.error_messages | فهرست کنید | این فهرستی از پیامهای خطای گزارشهایی را که پردازش نشدند، برمیگرداند. |
job_parameters | فرهنگ لغت | این شامل پارامترهای شغلی است که در درخواست createJob ارائه شده است. ویژگیهای مرتبط مانند «output_domain_blob_prefix» و «output_domain_bucket_name». |
job_parameters.attribution_report_to | رشته | به طور متقابل منحصر به reporting_site است. این نشانی وب گزارش یا مبدا محل دریافت گزارش است. مبدا بخشی از سایتی است که در Aggregation Service Onboarding ثبت شده است. این در درخواست createJob مشخص شده است. |
job_parameters.reporting_site | رشته | متقابلاً منحصر به attribution_report_to است. این نام میزبان URL گزارش یا مبدأ جایی است که گزارش دریافت شده است. مبدا بخشی از سایتی است که در Aggregation Service Onboarding ثبت شده است. توجه داشته باشید که میتوانید گزارشهایی را با چندین منبع گزارش در یک درخواست ارسال کنید تا زمانی که همه مبداهای گزارش متعلق به همان سایت ذکر شده در این پارامتر باشند. این در درخواست createJob مشخص شده است. علاوه بر این، اطمینان حاصل کنید که سطل فقط حاوی گزارش هایی است که می خواهید در زمان ایجاد شغل جمع آوری کنید. هر گزارش اضافه شده به سطل داده های ورودی با مبدا گزارش مطابق با سایت گزارش مشخص شده در پارامتر کار پردازش می شود. سرویس جمعآوری فقط گزارشهایی را در سطل دادهها در نظر میگیرد که با منبع گزارش ثبتشده کار مطابقت دارند. برای مثال، اگر مبدأ ثبتشده https://exampleabc.com باشد، فقط گزارشهایی از https://exampleabc.com شامل میشود، حتی اگر سطل حاوی گزارشهایی از زیر دامنهها باشد ( https://1.exampleabc.com و غیره. ) یا دامنه های کاملاً متفاوت ( https://3.examplexyz.com ). |
job_parameters.debug_privacy_epsilon | نقطه شناور، دوبل | فیلد اختیاری اگر مقداری ارسال نشود، از مقدار پیش فرض 10 استفاده می شود. مقادیر می توانند از 0 تا 64 باشند. این مقدار در درخواست createJob مشخص شده است. |
job_parameters.report_error_threshold_percentage | دوبل | فیلد اختیاری این درصد آستانه گزارش هایی است که می توانند قبل از شکست شغلی با شکست مواجه شوند. اگر مقداری تخصیص داده نشود، از مقدار پیش فرض 10% استفاده می شود. این در درخواست createJob مشخص شده است. |
job_parameters.input_report_count | ارزش طولانی | فیلد اختیاری تعداد کل گزارش های ارائه شده به عنوان داده های ورودی برای این کار. «report_error_threshold_percentage»، همراه با این مقدار، اگر تعداد قابل توجهی از گزارشها به دلیل خطا حذف شوند، باعث شکست زودهنگام شغلی میشود. این تنظیم در درخواست «createJob» مشخص شده است. |
job_parameters.filtering_ids | رشته | فیلد اختیاری فهرستی از شناسههای فیلتر بدون امضا که با کاما از هم جدا شدهاند. همه مشارکتهای غیر از شناسه فیلتر منطبق فیلتر میشوند. این در درخواست createJob مشخص شده است. (به عنوان مثال "filtering_ids":"12345,34455,12" . مقدار پیش فرض "0" است.) |