簡介:DNS 延遲的原因和緩解
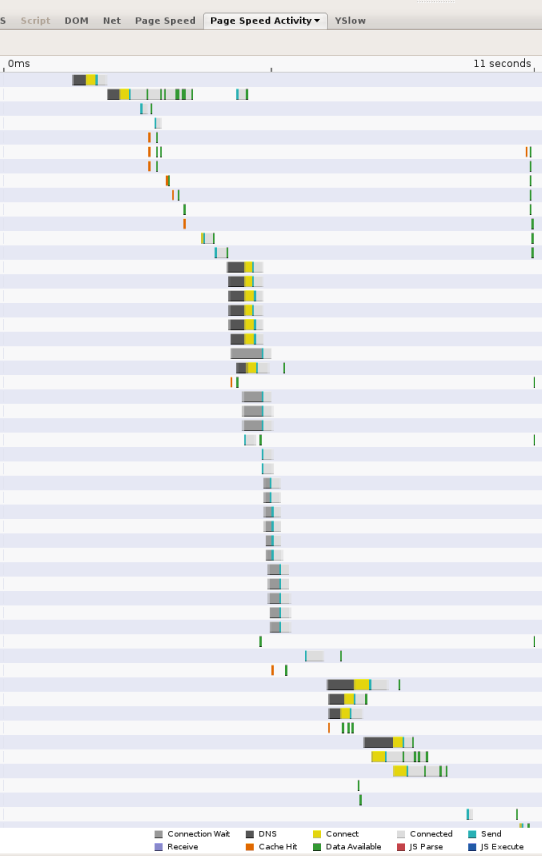
當網頁變得較為複雜,參照多個網域的資源時,DNS 查詢可能會成為瀏覽體驗的一大瓶頸。當用戶端需要透過網路查詢 DNS 解析器時,視解析器必須查詢的名稱伺服器和名稱伺服器數量而定,延遲時間可能會十分重要 (超過 2 個很少見,但可能會發生這種情況)。舉例來說,以下螢幕截圖顯示 Page Speed 網站效能評估工具回報的時間。每個長條都代表從該頁面參照的資源;黑色區段表示 DNS 查詢。在這個頁面中,網頁載入的前 11 秒內會進行 13 次查詢。 雖然系統會同時完成多筆查詢,但螢幕截圖顯示需要 5 個序列查詢時間,也就是總 11 秒的頁面載入時間總共需要幾秒。
DNS 延遲時間包含兩個部分:
- 用戶端 (使用者) 和 DNS 解析伺服器之間的延遲時間。 在大多數情況下,這主要是因為網路系統的一般往返時間 (RTT) 限制所引起:用戶端與伺服器機器之間的地理距離、網路壅塞、封包遺失和長時間重新傳輸延遲時間 (平均為一秒)、超載伺服器、阻斷服務攻擊等。
- 解析伺服器與其他名稱伺服器之間的延遲時間。
此延遲來源主要由下列因素造成:
- 快取失敗。如果無法從解析器的快取提供回應,但需要以遞迴方式查詢其他名稱伺服器,增加的網路延遲時間就非常可觀,特別是當權威伺服器是遠端的遠端伺服器時。
- 佈建中。如果 DNS 解析器超載,這些解析器必須將 DNS 解析要求和回應排入佇列,也可能開始捨棄及重新傳送封包。
- 惡意流量。 即使超額佈建 DNS 服務,DoS 流量仍會在伺服器中放置超載。同樣地,Kminsky 式攻擊也可能涉及洪水解析器,透過查詢保證略過快取,且需要傳出要求才能解析。
我們認為快取失敗因素是 DNS 延遲最主要的原因,詳情如下。
快取失敗
即使解析器擁有豐富的本機資源,與遠端名稱伺服器之間的基本延遲卻很難避免。換句話說,假設解析器已佈建足夠的容量,讓伺服器端的快取命中無時時間,在延遲方面快取失敗仍非常高。如要處理失敗,解析器必須至少與一個通訊,但通常是兩個以上的外部名稱伺服器。我們執行 Googlebot 網路檢索器後,觀察到名稱伺服器回應要求的平均解析時間平均為 130 毫秒。 不過,由於 UDP 封包遺失率及伺服器無法連線,導致 4-6% 的要求只會逾時。如果我們考量封包遺失、無效名稱伺服器、DNS 設定錯誤等失敗情況,則「實際」的平均端對端解析時間為 300-400 毫秒。不過,差異很大且長尾都很長。
雖然快取失敗率可能因 DNS 伺服器而異,但快取失敗很難避免,原因如下:
- 網際網路的規模和成長。 簡言之,隨著網際網路不斷增加,無論是新使用者還是新網站,大多數內容都是邊緣利益。儘管有少數網站 (也是 DNS 名稱) 非常熱門,但大多數使用者僅適用於少數使用者,而且很少存取。因此,大多數要求都會導致快取失敗。
- 低存留時間 (TTL) 值。 DNS 存留時間值呈現較低的趨勢,代表解析需要更頻繁的查詢。
- 快取隔離。 DNS 伺服器通常是部署在負載平衡器後方,負載平衡器則會隨機將查詢指派給不同的機器。這會導致個別伺服器維護單獨的快取,而無法重複使用共用集區的快取解析度。
因應措施
在 Google 公用 DNS 中,我們實作了幾種方式來縮短 DNS 查詢時間。其中有些做法相當符合標準,有些則是實驗性質:
- 請適當佈建伺服器,以處理用戶端流量的負載,包括惡意流量。
- 防範 DoS 和擴大攻擊雖然這大多是安全性問題,而且會影響關閉的解析器數量少於開放解析器,但能消除 DNS 伺服器帶來的額外流量負擔,這麼做也能改善效能。如要瞭解我們採用哪些方法來盡量降低攻擊風險,請參閱安全性優點相關頁面。
- 共用快取的負載平衡:提高服務叢集的匯總快取命中率。
- 提供全球涵蓋範圍,以便觸及所有使用者。
適當佈建供應叢集
快取 DNS 解析器執行的作業必須比正式名稱伺服器更高,因為許多回應無法從記憶體提供,而是需要與其他名稱伺服器進行通訊,因此需要大量網路輸入/輸出。此外,開放式解析器很容易遭受快取毒害嘗試,進而提高快取中毒嘗試率 (例如攻擊專門針對無法透過快取解析的假名稱傳送要求),以及增加流量負載的 DoS 攻擊。如果解析器未充分佈建,且無法跟上負載,可能會對效能產生嚴重負面影響。封包會遭到捨棄且需要重新傳輸、名稱伺服器要求必須排入佇列等。這些因素都會造成延誤。
因此,為高流量輸入/輸出佈建 DNS 解析器非常重要。這包括處理潛在的 DDoS 攻擊,唯一有效的解決方案就是超額佈建許多機器。但同時,您也不應在新增機器時降低快取命中率;這種做法需要實作有效的負載平衡政策,詳情請見下文。
共用共用快取的負載平衡
新增機器來調度解析器基礎架構資源,實際上可以執行反向作業,並在負載平衡未正確的情況下降低快取命中率。在一般部署作業中,負載平衡器位於負載平衡器後方,該負載平衡器會使用循環式等簡單的演算法,將流量平均分配給每部機器。這會讓每部機器都有各自的獨立快取,以便隔離不同機器間的快取內容。如果每個傳入的查詢都會分配至隨機機器,視流量的性質而定,有效快取失敗率可能會按比例提高。舉例來說,如果名稱的存留時間過長,且重複查詢,系統可能會依據叢集中的機器數量,提高快取錯誤率。(如果名稱的存留時間很短、經常查詢頻率極低,或導致無法快取回應 (0 存留時間和錯誤),新增機器並不會影響快取失敗率。
如要提高可快取名稱的命中率,請務必採用負載平衡伺服器,以免快取無法分段。Google 公用 DNS 分為兩種層級。在單一機器中,與使用者之間的非常接近,每個機器的小型快取則包含最熱門的名稱。 如果無法從這項快取滿足某項查詢,系統會將查詢傳送至另一個機器集區,並按名稱分區快取。以這個第二層快取來說,相同名稱的所有查詢都會傳送至同一部機器,而此名稱可以快取或不會。
分配放送叢集以擴大地理區域涵蓋範圍
如果是已關閉的解析器,這不會造成問題。 對於開放解析器,伺服器的位置越接近使用者,用戶端經歷的延遲時間就越短。 此外,有足夠的地理涵蓋範圍可間接改善端對端延遲時間,因為名稱伺服器通常會根據 DNS 解析器的位置傳回最佳化結果。 也就是說,如果內容供應器託管了世界各地的鏡像網站,該供應商的名稱伺服器會傳回最靠近 DNS 解析器的 IP 位址。
Google 公用 DNS 託管於全球的資料中心,透過任一傳播轉送功能,將使用者傳送至距離地理位置最近的資料中心。
此外,Google 公用 DNS 支援 EDNS 用戶端子網路 (ECS),這是解析器的 DNS 通訊協定擴充功能,可將用戶端位置轉送至名稱伺服器,系統可針對實際用戶端 IP 位址 (而非解析器的 IP 位址) 傳回位置機密的回應。詳情請參閱這份常見問題。 Google 公用 DNS 會自動偵測支援 EDNS 用戶端子網路的名稱伺服器。