
借助 Connector SDK 和 Cloud Search API,您可以创建 Cloud Search 索引队列。您可以使用这些队列来:
- 维护每个文档的多方面状况(状态、哈希值等),以便确保索引保持同步。
- 维护在遍历过程中发现的一系列项以将其编入索引。
- 根据项的状态确定其优先级。
- 维护状态信息(如检查点和更改令牌)。
队列是分配给已编入索引的项的标签(例如“默认”)。
状态和优先级
文档的优先级取决于其
ItemStatus
代码。可能的代码(按优先级从高到低排列)如下:
ERROR:项遇到了异步错误,需要重新编入索引。MODIFIED:项之前已编入索引,但在存储库中发生了更改。NEW_ITEM:项尚未编入索引。ACCEPTED:项之前已编入索引,并且未发生更改。
对于状态相同的项,在队列中停留时间最长的项具有更高的优先级。
将新项或已更改的项编入索引
图 1 显示了使用索引队列将新项或已更改的项编入索引的步骤。这些步骤反映了 REST API 调用;如需了解 SDK 等效项,请参阅 队列操作 (Connector SDK)。
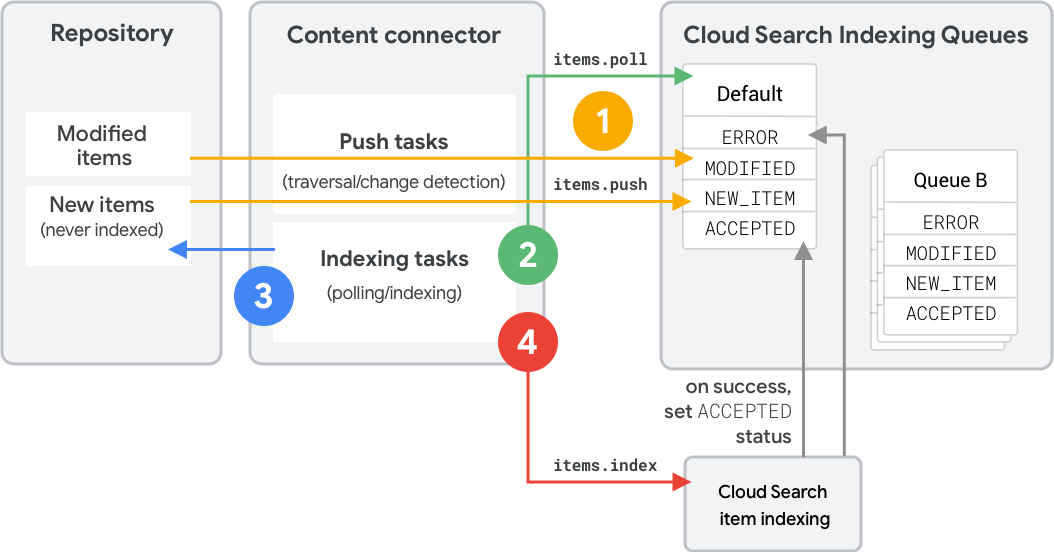
- 内容连接器使用
items.push将元数据和哈希值推送到队列中。- 如果连接器包含推送
type或contentHash,Cloud Search 会确定状态。 - 未知项会收到
NEW_ITEM状态。 - 哈希值匹配的现有项会保持
ACCEPTED状态。 - 哈希值不同的现有项会变为
MODIFIED状态。
- 如果连接器包含推送
- 连接器使用
items.poll确定要编入索引的项。Cloud Search 会按优先级顺序返回项。 - 连接器从存储库中检索项,并构建索引 API 请求。
- 连接器使用
items.index将项编入索引。项在成功处理后会进入ACCEPTED状态。
删除项
完全遍历策略使用两个队列将项编入索引并检测删除操作。图 2 显示了此策略中的第二次遍历。
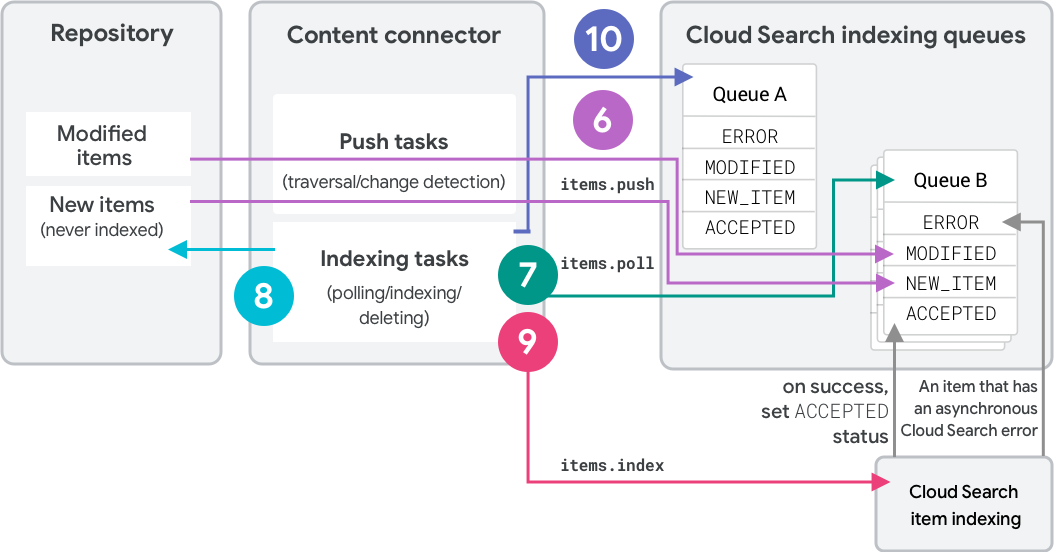
- 在初始遍历时,连接器会将项作为
NEW_ITEM推送到“队列 A”中。每个项都会收到标签“A”。 - 连接器会轮询队列 A 并将项编入索引。
- 在第二次完全遍历时,连接器会将项推送到“队列 B”中。
- 未知项会收到标签“B”和
NEW_ITEM状态。 - 哈希值匹配的现有项会将其标签更改为“B”并保持
ACCEPTED状态。 - 哈希值不同的现有项会将其标签更改为“B”并变为
MODIFIED状态。
- 未知项会收到标签“B”和
- 连接器会轮询队列 B 并将项编入索引。
- 最后,连接器会对队列 A 调用
deleteQueueItems。这会删除所有之前已编入索引且仍具有标签“A”的项。 - 后续遍历会交换这两个队列的角色。
队列操作 (Connector SDK)
使用
pushItems
构建器推送项。SDK 会自动使用 Repository 类的
getDoc
方法按
优先级顺序从队列中拉取项。
队列操作 (REST API)
- 如需推送,请使用
Items.push。 - 如需轮询,请使用
Items.poll.
您还可以在编入索引期间使用
Items.index
推送项。这些项会自动收到 ACCEPTED 状态。
Items.push
此方法会将 ID 添加到队列中。
type
决定了结果。推送新 ID 会添加一个具有 NEW_ITEM 状态的条目。
可选的载荷会在轮询期间返回。
轮询的项是 预留的,无法通过其他轮询调用返回。使用 Items.push 并将 type 设置为 NOT_MODIFIED、REPOSITORY_ERROR 或 REQUEUE 会 取消预留 条目。
采用哈希值的 Items.push
在推送请求中指定元数据或内容哈希值。
Cloud Search 会将这些值与存储的值进行比较。如果它们不匹配,条目会变为 MODIFIED。不匹配且不存在的 ID 会变为 NEW_ITEM。
Items.poll
此方法会检索高优先级的条目。每个返回的条目都会被预留,直到超时、重新编入索引或使用 Items.push 取消预留为止。