
یک طرح جستجوی ابری گوگل (Google Cloud Search schema) یک ساختار JSON است که اشیاء، ویژگیها و گزینههایی را که باید در نمایهسازی و پرسوجوی دادههای شما استفاده شوند، تعریف میکند. رابط محتوای شما دادهها را از مخزن شما میخواند و بر اساس طرح ثبتشده شما، دادهها را ساختاردهی و نمایهسازی میکند.
شما میتوانید با ارائه یک شیء طرحواره JSON به API و سپس ثبت آن، یک طرحواره ایجاد کنید. قبل از اینکه بتوانید دادههای خود را فهرستبندی کنید، باید برای هر یک از مخازن خود یک شیء طرحواره ثبت کنید.
این سند اصول اولیه ایجاد طرحواره را پوشش میدهد. برای کسب اطلاعات در مورد نحوه تنظیم طرحواره خود برای بهبود تجربه جستجو، به بهبود کیفیت جستجو مراجعه کنید.
ایجاد یک طرحواره
در زیر لیستی از مراحل مورد استفاده برای ایجاد طرح جستجوی ابری شما آمده است:
- شناسایی رفتار مورد انتظار کاربر
- مقداردهی اولیه یک منبع داده
- ایجاد یک طرحواره
- طرح نمونه کامل
- طرحواره خود را ثبت کنید
- دادههای خود را فهرستبندی کنید
- طرحواره خود را آزمایش کنید
- طرحواره خود را تنظیم کنید
شناسایی رفتار مورد انتظار کاربر
پیشبینی انواع پرسوجوهایی که کاربران شما انجام میدهند، به هدایت استراتژی شما برای ایجاد طرحوارهتان کمک میکند.
برای مثال، هنگام ارسال پرسوجو به پایگاه داده فیلم، ممکن است پیشبینی کنید که کاربر پرسوجویی مانند «تمام فیلمهای با بازی رابرت ردفورد را به من نشان بده» را مطرح کند. بنابراین، طرحواره شما باید از نتایج پرسوجو بر اساس «تمام فیلمها با یک بازیگر خاص» پشتیبانی کند.
برای تعریف طرحواره خود به گونهای که الگوهای رفتاری کاربر را منعکس کند، انجام این کارها را در نظر بگیرید:
- مجموعهای متنوع از پرسوجوهای مورد نظر از کاربران مختلف را ارزیابی کنید.
- اشیایی را که ممکن است در پرسوجوها استفاده شوند، شناسایی کنید. اشیا مجموعههای منطقی از دادههای مرتبط هستند، مانند یک فیلم در پایگاه دادهای از فیلمها.
- ویژگیها و مقادیری که شیء را تشکیل میدهند و ممکن است در پرسوجوها استفاده شوند را شناسایی کنید. ویژگیها، ویژگیهای قابل فهرستبندی شیء هستند؛ آنها میتوانند شامل مقادیر اولیه یا اشیاء دیگر باشند. برای مثال، یک شیء فیلم ممکن است ویژگیهایی مانند عنوان فیلم و تاریخ انتشار را به عنوان مقادیر اولیه داشته باشد. شیء فیلم همچنین ممکن است شامل اشیاء دیگری مانند اعضای بازیگران باشد که ویژگیهای خاص خود را دارند، مانند نام یا نقش آنها.
- مقادیر معتبر نمونه برای ویژگیها را شناسایی کنید. مقادیر ، دادههای واقعی اندیسگذاری شده برای یک ویژگی هستند. برای مثال، عنوان یک فیلم در پایگاه داده شما ممکن است "مهاجمان صندوقچه گمشده" باشد.
- گزینههای مرتبسازی و رتبهبندی مورد نظر کاربران خود را تعیین کنید. برای مثال، هنگام جستجوی فیلمها، کاربران ممکن است بخواهند بر اساس ترتیب زمانی مرتبسازی و بر اساس امتیاز مخاطبان رتبهبندی شوند و نیازی به مرتبسازی الفبایی بر اساس عنوان ندارند.
- (اختیاری) در نظر بگیرید که آیا یکی از ویژگیهای شما نشاندهندهی زمینهی خاصتری است که جستجوها ممکن است در آن انجام شوند، مانند نقش شغلی یا دپارتمان کاربران، تا پیشنهادات تکمیل خودکار بر اساس زمینه ارائه شوند. به عنوان مثال، برای افرادی که در پایگاه دادهای از فیلمها جستجو میکنند، ممکن است کاربران فقط به ژانر خاصی از فیلمها علاقهمند باشند. کاربران میتوانند ژانری را که میخواهند جستجوهایشان برگرداند، احتمالاً به عنوان بخشی از پروفایل کاربری خود، تعریف کنند. سپس، هنگامی که کاربر شروع به تایپ عبارت جستجو در مورد فیلمها میکند، فقط فیلمهایی در ژانر مورد نظر او، مانند "فیلمهای اکشن"، به عنوان بخشی از پیشنهادات تکمیل خودکار پیشنهاد میشوند.
- فهرستی از این اشیاء، ویژگیها و مقادیر نمونه که میتوانند در جستجوها استفاده شوند، تهیه کنید. (برای جزئیات بیشتر در مورد نحوه استفاده از این فهرست، به بخش گزینههای تعریف عملگر مراجعه کنید.)
منبع داده خود را مقداردهی اولیه کنید
یک منبع داده، دادههایی از یک مخزن را نشان میدهد که در Google Cloud فهرستبندی و ذخیره شده است. برای دستورالعملهای مربوط به مقداردهی اولیه یک منبع داده، به مدیریت منابع داده شخص ثالث مراجعه کنید.
نتایج جستجوی کاربر از منبع داده برگردانده میشود. وقتی کاربر روی نتیجه جستجو کلیک میکند، Cloud Search با استفاده از URL ارائه شده در درخواست نمایهسازی، کاربر را به مورد واقعی هدایت میکند.
اشیاء خود را تعریف کنید
واحد اساسی دادهها در یک طرحواره، شیء است که به آن " شیء طرحواره " نیز گفته میشود، که یک ساختار منطقی از دادهها است. در یک پایگاه داده از فیلمها، یک ساختار منطقی از دادهها "فیلم" است. شیء دیگر ممکن است "شخص" باشد که نمایانگر بازیگران و عوامل دخیل در فیلم است.
هر شیء در یک طرحواره دارای مجموعهای از ویژگیها یا صفات است که شیء را توصیف میکند، مانند عنوان و مدت زمان برای یک فیلم، یا نام و تاریخ تولد برای یک شخص. ویژگیهای یک شیء میتواند شامل مقادیر اولیه یا اشیاء دیگر باشد.
شکل ۱ اشیاء فیلم و شخص و ویژگیهای مرتبط با آنها را نشان میدهد.
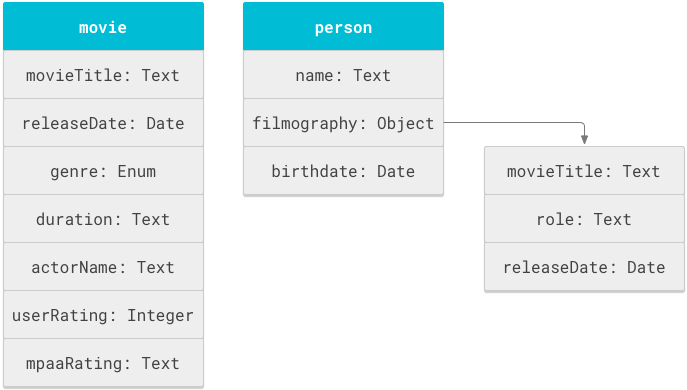
یک طرحواره جستجوی ابری اساساً فهرستی از عبارات تعریف شیء است که درون تگ objectDefinitions تعریف شدهاند. قطعه طرحواره زیر عبارات objectDefinitions را برای اشیاء طرحواره فیلم و شخص نشان میدهد.
{
"objectDefinitions": [
{
"name": "movie",
...
},
{
"name": "person",
...
}
]
}
وقتی یک شیء طرحواره تعریف میکنید، name برای شیء ارائه میدهید که باید در میان سایر اشیاء موجود در طرحواره منحصر به فرد باشد. معمولاً از مقداری name استفاده میکنید که شیء را توصیف میکند، مانند movie برای یک شیء فیلم. سرویس طرحواره از فیلد name به عنوان یک شناسه کلیدی برای اشیاء قابل فهرستبندی استفاده میکند. برای اطلاعات بیشتر در مورد فیلد name ، به بخش تعریف شیء مراجعه کنید.
تعریف ویژگیهای شیء
همانطور که در مرجع ObjectDefinition مشخص شده است، پس از نام شیء، مجموعهای از options و فهرستی از propertyDefinitions قرار میگیرد. این options میتوانند شامل freshnessOptions و displayOptions نیز باشند. freshnessOptions برای تنظیم رتبهبندی جستجو بر اساس تازگی یک آیتم استفاده میشوند. displayOptions برای تعریف اینکه آیا برچسبها و ویژگیهای خاص در نتایج جستجوی یک شیء نمایش داده شوند یا خیر، استفاده میشوند.
بخش propertyDefinitions جایی است که شما ویژگیهای یک شیء، مانند عنوان فیلم و تاریخ انتشار را تعریف میکنید.
قطعه کد زیر شیء movie را با دو ویژگی نشان میدهد: movieTitle و releaseDate .
{
"objectDefinitions": [
{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
},
"displayOptions": {
"displayLabel": "Release date"
}
...
]
}
]
}
تعریف ویژگی شامل موارد زیر است:
- یک رشته
name. - فهرستی از گزینههای مستقل از نوع داده، مانند
isReturnableدر قطعه کد قبلی. - یک نوع و گزینههای مختص به نوع مرتبط با آن، مانند
textPropertyOptionsوretrievalImportanceدر قطعه کد قبلی. - یک
operatorOptionsکه نحوه استفاده از ویژگی به عنوان یک عملگر جستجو را توصیف میکند. - یک یا چند
displayOptions، مانندdisplayLabelدر قطعه کد قبلی.
name یک ویژگی باید در شیء حاوی آن منحصر به فرد باشد، اما میتوان از همان نام در اشیاء و زیر-اشیاء دیگر نیز استفاده کرد. در شکل 1، عنوان و تاریخ انتشار فیلم دو بار تعریف شدهاند: یک بار در شیء movie و بار دیگر در زیر-شیء filmography شیء person . این طرحواره از فیلد movieTitle دوباره استفاده میکند تا بتواند از دو نوع رفتار جستجو پشتیبانی کند:
- نمایش نتایج فیلم هنگام جستجوی عنوان یک فیلم توسط کاربران.
- نمایش نتایج جستجو به کاربران زمانی که کاربران عنوان فیلمی را که یک بازیگر در آن بازی کرده است، جستجو میکنند.
به طور مشابه، این طرحواره از فیلد releaseDate دوباره استفاده میکند زیرا برای دو فیلد movieTitle معنای یکسانی دارد.
در توسعه طرحواره خودتان، در نظر بگیرید که چگونه مخزن شما ممکن است فیلدهای مرتبطی داشته باشد که حاوی دادههایی هستند که میخواهید بیش از یک بار در طرحواره خود اعلام کنید.
گزینههای وابسته به نوع را اضافه کنید
تعریف ویژگی (PropertyDefinition) گزینههای عمومی عملکرد جستجو را که برای همه ویژگیها صرف نظر از نوع داده مشترک است، فهرست میکند.
-
isReturnable- نشان میدهد که آیا این ویژگی، دادههایی را شناسایی میکند که باید از طریق API کوئری در نتایج جستجو بازگردانده شوند یا خیر. همه ویژگیهای فیلم مثال، قابل بازگشت هستند. ویژگیهای غیر قابل بازگشت میتوانند برای جستجو یا رتبهبندی نتایج بدون بازگشت به کاربر استفاده شوند. -
isRepeatable- نشان میدهد که آیا میتوان چندین مقدار برای این ویژگی در نظر گرفت یا خیر. برای مثال، یک فیلم فقط یک تاریخ انتشار دارد اما میتواند چندین بازیگر داشته باشد. -
isSortable- نشان میدهد که میتوان از این ویژگی برای مرتبسازی استفاده کرد. این موضوع نمیتواند برای ویژگیهایی که تکرارپذیر هستند، صادق باشد. برای مثال، نتایج فیلم ممکن است بر اساس تاریخ انتشار یا رتبهبندی مخاطبان مرتب شوند. -
isFacetable- نشان میدهد که این ویژگی میتواند برای تولید وجهها (facets) استفاده شود. وجه برای اصلاح نتایج جستجو استفاده میشود که در آن کاربر نتایج اولیه را میبیند و سپس معیارها یا وجههایی را برای اصلاح بیشتر آن نتایج اضافه میکند. این گزینه برای ویژگیهایی که نوع آنها object است نمیتواند درست باشد وisReturnableباید برای تنظیم این گزینه درست باشد. در نهایت، این گزینه فقط برای ویژگیهای enum، boolean و text پشتیبانی میشود. به عنوان مثال، در طرحواره نمونه ما، ممکن استgenre،actorName،userRatingوmpaaRatingرا به facetable تبدیل کنیم تا امکان استفاده از آنها برای اصلاح تعاملی نتایج جستجو فراهم شود. -
isWildcardSearchableنشان میدهد که کاربران میتوانند برای این ویژگی جستجوی wildcard انجام دهند. این گزینه فقط برای ویژگیهای متنی در دسترس است. نحوه عملکرد جستجوی wildcard در فیلد متن به مقدار تنظیم شده در فیلد exactMatchWithOperator بستگی دارد. اگرexactMatchWithOperatorرویtrueتنظیم شده باشد، مقدار متن به عنوان یک مقدار اتمی توکنسازی میشود و جستجوی wildcard روی آن انجام میشود. به عنوان مثال، اگر مقدار متنscience-fictionباشد، یک کوئری wildcardscience-*با آن مطابقت دارد. اگرexactMatchWithOperatorرویfalseتنظیم شده باشد، مقدار متن توکنسازی میشود و جستجوی wildcard روی هر توکن انجام میشود. به عنوان مثال، اگر مقدار متن "science-fiction" باشد، کوئریهای wildcard باsci*یاfi*با مورد مطابقت دارند، اماscience-*مطابقت ندارند.
این پارامترهای عمومی عملکرد جستجو، همگی مقادیر بولی هستند؛ همه آنها مقدار پیشفرض false دارند و برای استفاده باید روی true تنظیم شوند.
جدول زیر پارامترهای بولی را نشان میدهد که برای تمام ویژگیهای شیء movie روی true تنظیم شدهاند:
| ملک | isReturnable | isRepeatable | isSortable | isFacetable | isWildcardSearchable |
|---|---|---|---|---|---|
movieTitle | درست | درست | |||
releaseDate | درست | درست | |||
genre | درست | درست | درست | ||
duration | درست | ||||
actorName | درست | درست | درست | درست | |
userRating | درست | درست | |||
mpaaRating | درست | درست |
هر دو genre و actorName دارای مقدار true برای isRepeatable هستند، زیرا یک فیلم ممکن است به بیش از یک ژانر تعلق داشته باشد و معمولاً بیش از یک بازیگر دارد. اگر یک ویژگی تکرارپذیر باشد یا در یک زیرشیء تکرارپذیر قرار داشته باشد، نمیتواند قابل مرتبسازی باشد.
تعریف نوع
بخش مرجع PropertyDefinition چندین xxPropertyOptions را فهرست میکند که در آنها xx یک نوع خاص، مانند boolean است. برای تنظیم نوع دادهی ویژگی، باید شیء نوع دادهی مناسب را تعریف کنید. تعریف یک شیء نوع داده برای یک ویژگی، نوع دادهی آن ویژگی را تعیین میکند. به عنوان مثال، تعریف textPropertyOptions برای ویژگی movieTitle نشان میدهد که عنوان فیلم از نوع متن است. قطعه کد زیر ویژگی movieTitle را با تنظیم نوع داده textPropertyOptions نشان میدهد.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
...
},
...
},
یک ویژگی میتواند فقط یک نوع داده مرتبط داشته باشد. برای مثال، در طرحواره فیلم ما، releaseDate فقط میتواند یک تاریخ (مثلاً 2016-01-13 ) یا یک رشته (مثلاً January 13, 2016 ) باشد، اما نمیتواند هر دو را با هم داشته باشد.
در اینجا اشیاء نوع دادهای که برای مشخص کردن انواع داده برای ویژگیهای موجود در طرحواره فیلم نمونه استفاده میشوند، آمده است:
| ملک | شیء از نوع داده |
|---|---|
movieTitle | textPropertyOptions |
releaseDate | datePropertyOptions |
genre | enumPropertyOptions |
duration | textPropertyOptions |
actorName | textPropertyOptions |
userRating | integerPropertyOptions |
mpaaRating | textPropertyOptions |
نوع دادهای که برای ویژگی انتخاب میکنید به موارد استفاده مورد انتظار شما بستگی دارد. در سناریوی تصور شده از این طرحواره فیلم، انتظار میرود کاربران بخواهند نتایج را به ترتیب زمانی مرتب کنند، بنابراین releaseDate یک شیء تاریخ است. اگر، برای مثال، یک مورد استفاده مورد انتظار برای مقایسه نسخههای دسامبر در طول سالها با نسخههای ژانویه وجود داشته باشد، آنگاه یک قالب رشتهای ممکن است مفید باشد.
پیکربندی گزینههای خاص نوع
بخش مرجع PropertyDefinition به گزینههای مربوط به هر نوع پیوند میدهد. اکثر گزینههای مختص به نوع، به جز لیست possibleValues در enumPropertyOptions ، اختیاری هستند. علاوه بر این، گزینه orderedRanking به شما امکان میدهد مقادیر را نسبت به یکدیگر رتبهبندی کنید. قطعه کد زیر ویژگی movieTitle را با تنظیم نوع داده توسط textPropertyOptions و با گزینه مختص به نوع retrievalImportance نشان میدهد.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
...
},
...
}
در اینجا گزینههای اضافی مربوط به نوع داده که در طرح نمونه استفاده شدهاند، آورده شده است:
| ملک | نوع | گزینههای خاص هر نوع |
|---|---|---|
movieTitle | textPropertyOptions | retrievalImportance |
releaseDate | datePropertyOptions | |
genre | enumPropertyOptions | |
duration | textPropertyOptions | |
actorName | textPropertyOptions | |
userRating | integerPropertyOptions | orderedRanking ، maximumValue |
mpaaRating | textPropertyOptions |
تعریف گزینههای اپراتور
علاوه بر گزینههای مختص به نوع، هر نوع دارای مجموعهای از operatorOptions اختیاری است. این گزینهها نحوه استفاده از ویژگی به عنوان یک عملگر جستجو را شرح میدهند. قطعه کد زیر ویژگی movieTitle را به همراه textPropertyOptions که نوع داده را تنظیم میکند و با گزینههای مختص به نوع retrievalImportance و operatorOptions نشان میدهد.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
...
}
هر operatorOptions یک operatorName دارد، مانند title برای movieTitle . عملگر name عملگر جستجو برای ویژگی است. عملگر جستجو پارامتر واقعی است که انتظار دارید کاربران هنگام محدود کردن جستجو از آن استفاده کنند. به عنوان مثال، برای جستجوی فیلمها بر اساس عنوان آنها، کاربر title:movieName تایپ میکند، که movieName نام یک فیلم است.
نام عملگرها لازم نیست با نام ویژگی یکسان باشد. در عوض، باید از نام عملگرهایی استفاده کنید که منعکس کننده رایجترین کلمات مورد استفاده کاربران در سازمان شما باشند. برای مثال، اگر کاربران شما اصطلاح "name" را به جای "title" برای عنوان یک فیلم ترجیح میدهند، نام عملگر باید روی "name" تنظیم شود.
شما میتوانید از یک نام عملگر برای چندین ویژگی استفاده کنید، مادامی که همه ویژگیها به یک نوع تبدیل شوند. هنگام استفاده از یک نام عملگر مشترک در طول یک پرسوجو، تمام ویژگیهایی که از آن نام عملگر استفاده میکنند بازیابی میشوند. برای مثال، فرض کنید شیء فیلم دارای ویژگیهای plotSummary و plotSynopsis است و هر یک از این ویژگیها دارای operatorName با plot هستند. مادامی که هر دوی این ویژگیها متن ( textPropertyOptions ) باشند، یک پرسوجوی واحد با استفاده از عملگر جستجوی plot هر دوی آنها را بازیابی میکند.
علاوه بر operatorName ، ویژگیهایی که قابل مرتبسازی هستند میتوانند فیلدهای lessThanOperatorName و greaterThanOperatorName را در operatorOptions داشته باشند. کاربران میتوانند از این گزینهها برای ایجاد پرسوجوها بر اساس مقایسه با یک مقدار ارسالی استفاده کنند.
در نهایت، textOperatorOptions یک فیلد exactMatchWithOperator در operatorOptions دارد. اگر exactMatchWithOperator را روی true تنظیم کنید، رشته پرسوجو باید با کل مقدار ویژگی مطابقت داشته باشد، نه اینکه صرفاً در متن یافت شود. مقدار متن در جستجوهای عملگر و تطابقهای وجهی به عنوان یک مقدار اتمی در نظر گرفته میشود.
برای مثال، فهرستبندی اشیاء کتاب یا فیلم با ویژگیهای ژانر را در نظر بگیرید. ژانرها میتوانند شامل "علمی-تخیلی"، "علم" و "داستان تخیلی" باشند. با تنظیم exactMatchWithOperator روی false یا حذف آن، جستجوی یک ژانر یا انتخاب وجه "علمی" یا "داستان تخیلی" نیز نتایج "علمی-تخیلی" را برمیگرداند زیرا متن توکنگذاری شده است و توکنهای "علمی" و "داستان تخیلی" در "علمی-تخیلی" وجود دارند. وقتی exactMatchWithOperator روی true تنظیم شده باشد، متن به عنوان یک توکن واحد در نظر گرفته میشود، بنابراین نه "علم" و نه "داستان تخیلی" با "علمی-تخیلی" مطابقت ندارند.
(اختیاری) بخش displayOptions را اضافه کنید
در انتهای هر بخش propertyDefinition یک بخش اختیاری به نام displayOptions وجود دارد. این بخش شامل یک رشته displayLabel است. displayLabel یک برچسب متنی کاربرپسند و توصیهشده برای ویژگی است. اگر ویژگی با استفاده از ObjectDisplayOptions برای نمایش پیکربندی شده باشد، این برچسب در جلوی ویژگی نمایش داده میشود. اگر ویژگی برای نمایش پیکربندی شده باشد و displayLabel تعریف نشده باشد، فقط مقدار ویژگی نمایش داده میشود.
قطعه کد زیر ویژگی movieTitle را با برچسب displayLabel تنظیم شده روی 'Title' نشان میدهد.
{
"name": "movieTitle",
"isReturnable": true,
"isWildcardSearchable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "title"
}
},
"displayOptions": {
"displayLabel": "Title"
}
},
در زیر مقادیر displayLabel برای تمام ویژگیهای شیء movie در طرحواره نمونه آمده است:
| ملک | displayLabel |
|---|---|
movieTitle | Title |
releaseDate | Release date |
genre | Genre |
duration | Run length |
actorName | Actor |
userRating | Audience score |
mpaaRating | MPAA rating |
(اختیاری) بخش suggestionFilteringOperators[] اضافه کنید
در انتهای هر بخش propertyDefinition ، یک بخش اختیاری به نام suggestionFilteringOperators[] وجود دارد. از این بخش برای تعریف یک ویژگی که برای فیلتر کردن پیشنهادات تکمیل خودکار استفاده میشود، استفاده کنید. برای مثال، میتوانید عملگر genre را برای فیلتر کردن پیشنهادات بر اساس ژانر فیلم مورد نظر کاربر تعریف کنید. سپس، هنگامی که کاربر عبارت جستجوی خود را تایپ میکند، فقط فیلمهایی که با ژانر مورد نظر او مطابقت دارند، به عنوان بخشی از پیشنهادات تکمیل خودکار نمایش داده میشوند.
طرحواره خود را ثبت کنید
برای اینکه دادههای ساختاریافته از کوئریهای Cloud Search برگردانده شوند، باید طرحواره خود را در سرویس طرحواره Cloud Search ثبت کنید. ثبت یک طرحواره به شناسه منبع دادهای که در مرحله «مقداردهی اولیه منبع داده» به دست آوردهاید، نیاز دارد.
با استفاده از شناسه منبع داده، یک درخواست UpdateSchema برای ثبت طرحواره خود صادر کنید.
همانطور که در صفحه مرجع UpdateSchema توضیح داده شده است، درخواست HTTP زیر را برای ثبت طرحواره خود صادر کنید:
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
متن درخواست شما باید شامل موارد زیر باشد:
{
"validateOnly": // true or false,
"schema": {
// ... Your complete schema object ...
}
}
از گزینه validateOnly برای آزمایش اعتبار طرحواره خود بدون ثبت واقعی آن استفاده کنید.
دادههای خود را فهرستبندی کنید
پس از ثبت طرحواره، منبع داده را با استفاده از فراخوانیهای فهرست (Index ) پر کنید. فهرستبندی معمولاً درون رابط محتوای شما انجام میشود.
با استفاده از طرحواره فیلم، یک درخواست نمایهسازی REST API برای یک فیلم واحد به این شکل خواهد بود:
{
"name": "datasource/<data_source_id>/items/titanic",
"acl": {
"readers": [
{
"gsuitePrincipal": {
"gsuiteDomain": true
}
}
]
},
"metadata": {
"title": "Titanic",
"sourceRepositoryUrl": "http://www.imdb.com/title/tt2234155/?ref_=nv_sr_1",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [
{
"name": "movieTitle",
"textValues": {
"values": [
"Titanic"
]
}
},
{
"name": "releaseDate",
"dateValues": {
"values": [
{
"year": 1997,
"month": 12,
"day": 19
}
]
}
},
{
"name": "actorName",
"textValues": {
"values": [
"Leonardo DiCaprio",
"Kate Winslet",
"Billy Zane"
]
}
},
{
"name": "genre",
"enumValues": {
"values": [
"Drama",
"Action"
]
}
},
{
"name": "userRating",
"integerValues": {
"values": [
8
]
}
},
{
"name": "mpaaRating",
"textValues": {
"values": [
"PG-13"
]
}
},
{
"name": "duration",
"textValues": {
"values": [
"3 h 14 min"
]
}
}
]
}
},
"content": {
"inlineContent": "A seventeen-year-old aristocrat falls in love with a kind but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.",
"contentFormat": "TEXT"
},
"version": "01",
"itemType": "CONTENT_ITEM"
}
توجه داشته باشید که چگونه مقدار movie در فیلد objectType با نام تعریف شیء در طرحواره مطابقت دارد. با تطبیق این دو مقدار، Cloud Search میداند که از کدام شیء طرحواره در طول فهرستبندی استفاده کند.
همچنین توجه داشته باشید که چگونه اندیسگذاری ویژگی طرحواره releaseDate از زیرویژگیهای year ، month و day که از آنها ارثبری میکند، استفاده میکند، زیرا از طریق datePropertyOptions به عنوان یک نوع داده date تعریف شده است. با این حال، از آنجا که year ، month و day در طرحواره تعریف نشدهاند، نمیتوانید روی یکی از آن ویژگیها (مثلاً year ) به صورت جداگانه پرسوجو کنید.
و همچنین توجه داشته باشید که چگونه ویژگی تکرارپذیر actorName با استفاده از لیستی از مقادیر، اندیسگذاری میشود.
شناسایی مشکلات احتمالی ایندکس گذاری
دو مشکل رایج مربوط به طرحوارهها و نمایهسازی عبارتند از:
درخواست ایندکسگذاری شما شامل یک شیء یا نام ویژگی طرحواره است که در سرویس طرحواره ثبت نشده است. این مشکل باعث میشود که ویژگی یا شیء نادیده گرفته شود.
درخواست نمایهسازی شما دارای خاصیتی با مقدار نوع متفاوت از نوع ثبتشده در طرحواره است. این مشکل باعث میشود Cloud Search در زمان نمایهسازی خطا برگرداند.
طرحواره خود را با چندین نوع پرس و جو آزمایش کنید
قبل از اینکه طرحواره خود را برای یک مخزن داده بزرگ عملیاتی ثبت کنید، آزمایش با یک مخزن داده آزمایشی کوچکتر را در نظر بگیرید. آزمایش با یک مخزن داده آزمایشی کوچکتر به شما این امکان را میدهد که به سرعت طرحواره خود را تنظیم کنید و دادههای فهرستبندی شده را حذف کنید، بدون اینکه روی یک شاخص بزرگتر یا یک شاخص تولید موجود تأثیر بگذارید. برای یک مخزن داده آزمایشی، یک ACL ایجاد کنید که فقط یک کاربر آزمایشی را مجاز کند تا سایر کاربران این دادهها را در نتایج جستجو نبینند.
برای ایجاد یک رابط جستجو جهت اعتبارسنجی عبارات جستجو، به رابط جستجو مراجعه کنید.
این بخش شامل چندین نمونه کوئری مختلف است که میتوانید برای آزمایش طرحواره فیلم از آنها استفاده کنید.
با یک پرس و جوی عمومی تست کنید
یک پرسوجوی عمومی، تمام موارد موجود در منبع داده حاوی یک رشته خاص را برمیگرداند. با استفاده از یک رابط جستجو، میتوانید با تایپ کلمه "titanic" و فشردن کلید Return ، یک پرسوجوی عمومی را روی یک منبع داده فیلم اجرا کنید. تمام فیلمهایی که کلمه "titanic" در آنها وجود دارد، باید در نتایج جستجو نمایش داده شوند.
با یک اپراتور تست کنید
افزودن یک عملگر به پرسوجو، نتایج را به مواردی که با آن مقدار عملگر مطابقت دارند، محدود میکند. برای مثال، ممکن است بخواهید از عملگر actor برای یافتن تمام فیلمهایی که یک بازیگر خاص در آنها بازی میکند، استفاده کنید. با استفاده از یک رابط جستجو، میتوانید این پرسوجوی اپراتوری را به سادگی با تایپ کردن یک جفت عملگر=مقدار ، مانند "بازیگر:زین" و فشار دادن کلید بازگشت ، انجام دهید. تمام فیلمهایی که زین به عنوان بازیگر در آنها حضور دارد، باید در نتایج جستجو نمایش داده شوند.
طرحواره خود را تنظیم کنید
پس از اینکه طرحواره و دادههای شما مورد استفاده قرار گرفتند، به نظارت بر آنچه برای کاربران شما کار میکند و آنچه کار نمیکند، ادامه دهید. شما باید طرحواره خود را برای موقعیتهای زیر تنظیم کنید:
- فهرستبندی فیلدی که قبلاً فهرستبندی نشده بود. برای مثال، کاربران شما ممکن است بارها و بارها بر اساس نام کارگردان به دنبال فیلمها بگردند، بنابراین میتوانید طرحواره خود را طوری تنظیم کنید که از نام کارگردان به عنوان یک عملگر پشتیبانی کند.
- تغییر نام اپراتورهای جستجو بر اساس بازخورد کاربر. نام اپراتورها برای کاربرپسند بودن در نظر گرفته شدهاند. اگر کاربران شما دائماً نام اپراتور اشتباه را "به خاطر میسپارند"، میتوانید تغییر آن را در نظر بگیرید.
فهرستبندی مجدد پس از تغییر طرحواره
تغییر هر یک از مقادیر زیر در schema شما نیازی به فهرستبندی مجدد دادهها ندارد . میتوانید به سادگی یک درخواست UpdateSchema جدید ارسال کنید و فهرست شما به کار خود ادامه خواهد داد:
- نام اپراتورها.
- حداقل و حداکثر مقادیر صحیح.
- رتبهبندی مرتبشده اعداد صحیح و شمارشی.
- گزینههای تازگی.
- گزینههای نمایش.
برای تغییرات زیر، دادههای ایندکسشده قبلی طبق طرحواره ثبتشده قبلی به کار خود ادامه خواهند داد. با این حال، اگر طرحواره بهروزرسانیشده این تغییرات را داشته باشد، باید ورودیهای موجود را دوباره ایندکس کنید تا تغییرات را بر اساس آن مشاهده کنید:
- اضافه کردن یا حذف کردن یک ویژگی یا شیء جدید
- تغییر
isReturnable،isFacetableیاisSortableازfalseبهtrue.
شما فقط در صورتی باید isFacetable یا isSortable را روی true تنظیم کنید که مورد استفاده و نیاز مشخصی داشته باشید.
در نهایت، وقتی طرحواره خود را با علامتگذاری یک ویژگی isSuggestable بهروزرسانی میکنید، باید دادههای خود را مجدداً فهرستبندی کنید که باعث تأخیر در استفاده از تکمیل خودکار برای آن ویژگی میشود.
تغییرات غیرمجاز در ملک
برخی از تغییرات در طرحواره مجاز نیستند، حتی اگر دادههای خود را دوباره فهرستبندی کنید، زیرا این تغییرات باعث اختلال در فهرستبندی یا تولید نتایج جستجوی ضعیف یا متناقض میشوند. این تغییرات شامل موارد زیر است:
- نوع داده ویژگی
- نام ملک.
- تنظیم
exactMatchWithOperator. - تنظیم
retrievalImportance.
با این حال، راهی برای دور زدن این محدودیت وجود دارد.
ایجاد یک تغییر پیچیده در طرحواره
برای جلوگیری از تغییراتی که منجر به نتایج جستجوی ضعیف یا فهرست جستجوی خراب میشوند، Cloud Search از انواع خاصی از تغییرات در درخواستهای UpdateSchema پس از فهرستبندی مخزن جلوگیری میکند. به عنوان مثال، نوع داده یا نام یک ویژگی پس از تنظیم آنها قابل تغییر نیست. این تغییرات را نمیتوان از طریق یک درخواست UpdateSchema ساده انجام داد، حتی اگر دادههای خود را دوباره فهرستبندی کنید.
در شرایطی که باید تغییری را در طرحواره خود ایجاد کنید که در غیر این صورت مجاز نیست ، اغلب میتوانید مجموعهای از تغییرات مجاز را ایجاد کنید که همان اثر را به دست آورند. به طور کلی، این شامل ابتدا انتقال ویژگیهای ایندکس شده از تعریف شیء قدیمیتر به تعریف جدیدتر و سپس ارسال یک درخواست ایندکس گذاری است که فقط از ویژگی جدیدتر استفاده میکند.
مراحل زیر نحوه تغییر نوع داده یا نام یک ویژگی را نشان میدهد:
- یک ویژگی جدید به تعریف شیء در طرحواره خود اضافه کنید. از نامی متفاوت از نام ویژگی مورد نظر برای تغییر استفاده کنید.
- درخواست UpdateSchema را با تعریف جدید ارسال کنید. به یاد داشته باشید که کل طرحواره، شامل هر دو ویژگی جدید و قدیمی، را در درخواست ارسال کنید.
ایندکس را از مخزن دادهها دوباره پر کنید. برای پر کردن مجدد ایندکس، تمام درخواستهای ایندکسگذاری را با استفاده از ویژگی جدید ارسال کنید، اما از ویژگی قدیمی استفاده نکنید ، زیرا این کار منجر به شمارش مجدد تطابقهای پرسوجو میشود.
- در حین اندیسگذاری backfill، برای جلوگیری از رفتار ناهماهنگ، ویژگی جدید را بررسی کنید و پیشفرض را روی ویژگی قدیمی قرار دهید.
- پس از اتمام پر کردن مجدد، برای تأیید، کوئریهای آزمایشی اجرا کنید.
ویژگی قدیمی را حذف کنید. یک درخواست UpdateSchema دیگر بدون نام ویژگی قدیمی صادر کنید و استفاده از نام ویژگی قدیمی را در درخواستهای نمایهسازی آینده متوقف کنید.
هرگونه استفاده از ویژگی قدیمی را به ویژگی جدید منتقل کنید. برای مثال، اگر نام ویژگی را از creator به author تغییر دهید، باید کد پرس و جوی خود را به گونهای بهروزرسانی کنید که در جایی که قبلاً به creator ارجاع میداد، از author استفاده کند.
جستجوی ابری (Cloud Search) سابقهای از هرگونه ویژگی یا شیء حذفشده را به مدت 30 روز نگه میدارد تا از هرگونه استفاده مجدد که میتواند منجر به نتایج نمایهسازی غیرمنتظره شود، جلوگیری کند. در طول این 30 روز، شما باید از هرگونه استفاده از شیء یا ویژگی حذفشده، از جمله حذف آنها از درخواستهای نمایهسازی آینده، اجتناب کنید. این تضمین میکند که اگر بعداً تصمیم به بازگرداندن آن ویژگی یا شیء گرفتید، میتوانید این کار را به روشی انجام دهید که صحت نمایهسازی شما حفظ شود.
محدودیتهای اندازه را بشناسید
جستجوی ابری محدودیتهایی را بر اندازه اشیاء و طرحوارههای داده ساختاریافته اعمال میکند. این محدودیتها عبارتند از:
- حداکثر تعداد اشیاء سطح بالا 10 شیء است.
- حداکثر عمق یک سلسله مراتب داده ساختاریافته ۱۰ سطح است.
- تعداد کل فیلدها در یک شیء به ۱۰۰۰ محدود میشود که شامل تعداد فیلدهای اولیه به علاوه مجموع تعداد فیلدها در هر شیء تو در تو است.
مراحل بعدی
در اینجا چند گام بعدی که میتوانید بردارید، آورده شده است:
برای آزمایش طرحواره خود، یک رابط جستجو ایجاد کنید.
طرحواره خود را برای بهبود کیفیت جستجو تنظیم کنید.
یاد بگیرید که چگونه از طرحواره
_dictionaryEntryبرای تعریف مترادفهای اصطلاحات رایج در شرکت خود استفاده کنید. برای استفاده از طرحواره_dictionaryEntry، به بخش «تعریف مترادفها» مراجعه کنید.یک رابط ایجاد کنید.