
Mit Cloud Search können Mitarbeiter Informationen wie interne Dokumente, Datenbankfelder und CRM-Daten in internen Datenrepositories suchen und abrufen.
Architekturübersicht
Abbildung 1 zeigt die Hauptkomponenten einer Cloud Search-Implementierung:
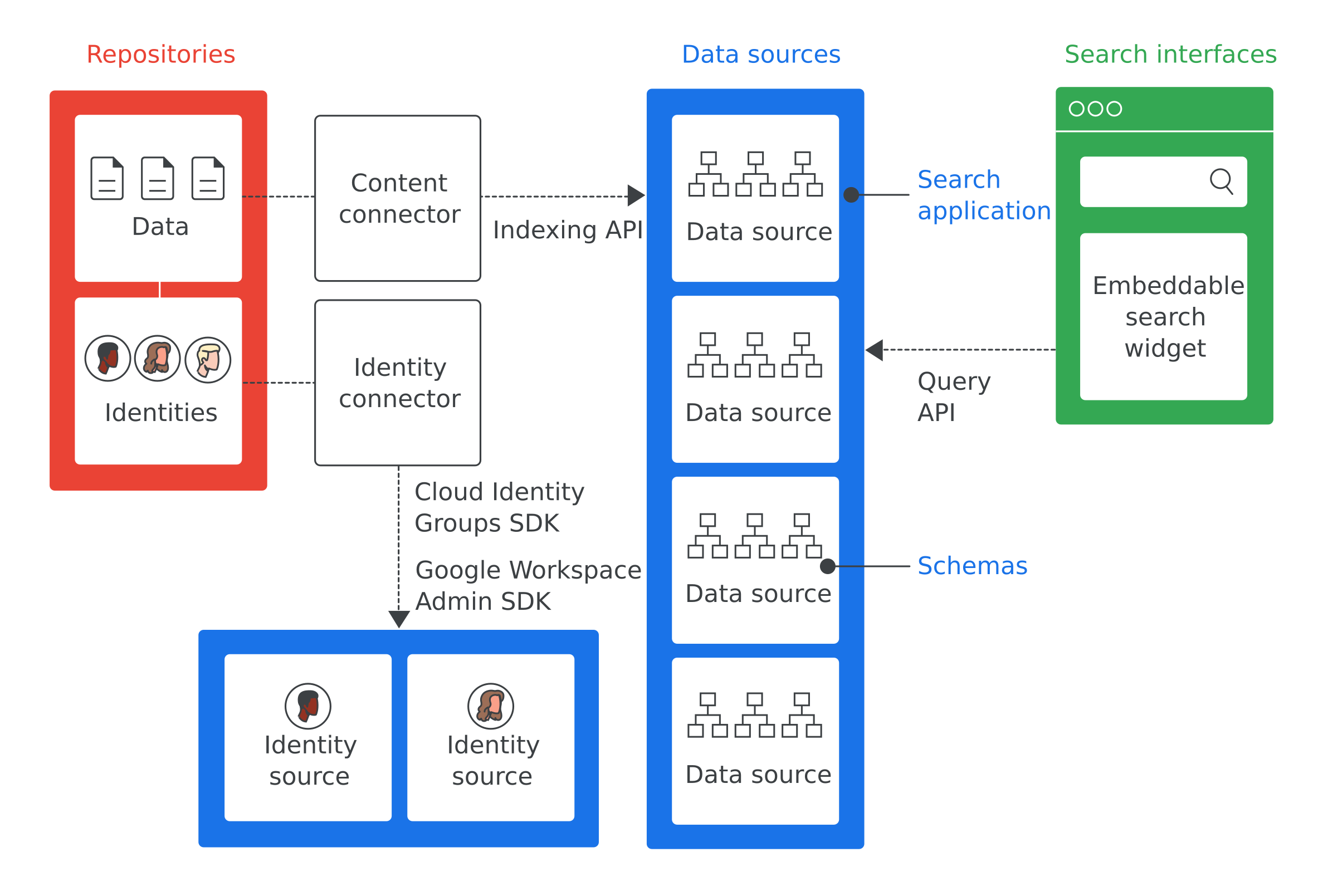
Hier finden Sie Definitionen für die wichtigsten Begriffe aus Abbildung 1:
- Repository
- Software, mit der ein Unternehmen Daten speichert, z. B. eine Datenbank für Mitarbeiterinformationen
- Datenquelle
- Daten aus einem Repository, die von Cloud Search indexiert und gespeichert werden
- Suchoberfläche
- Die Benutzeroberfläche, über die Mitarbeiter in einer Datenquelle suchen. Sie können eine Suchoberfläche für jedes Gerät entwickeln, z. B. für ein Mobiltelefon oder einen Desktop-Computer. Sie können auch das von Google bereitgestellte Such-Widget bereitstellen, um die Suche auf Ihren internen Websites zu ermöglichen. Jede Suche enthält die ID der Suchanwendung, um den Suchkontext zu identifizieren, z. B. in einem Tool für den Kundenservice. Die Website cloudsearch.google.com enthält eine Suchoberfläche.
- Suchanwendung
- Eine Gruppe von Einstellungen, die, wenn sie mit einer Suchoberfläche verknüpft sind, kontextbezogene Informationen zu Suchen bereitstellen. Zu solchen Informationen gehören die Datenquellen und Suchranglisten, die für eine Suche verwendet werden. Suchanwendungen enthalten auch Mechanismen zum Filtern von Ergebnissen und ermöglichen die Berichterstellung über Datenquellen, z. B. hinsichtlich der Anzahl von Abfragen, die in einem bestimmten Zeitraum durchgeführt wurden.
- Schema
- Eine Datenstruktur, in der beschrieben wird, wie Daten in einem Unternehmensrepository für Cloud Search dargestellt werden sollten. Ein Schema definiert Google Cloud Search für Ihre Mitarbeiter, z. B. wie Dinge gefiltert und angezeigt werden.
- Inhaltsconnector
- Ein Programm, mit dem in den Daten eines Unternehmensrepositorys gesucht wird, um eine Datenquelle zu befüllen
- Identitätsconnector
- Ein Programm, mit dem Unternehmensidentitäten (Nutzer und Gruppen) mit den für Cloud Search erforderlichen Identitäten synchronisiert werden
Cloud Search – Anwendungsfälle
Beispiele für Anwendungsfälle für Cloud Search:
- Mitarbeiter müssen Unternehmensrichtlinien, Dokumente und Inhalte finden, die von anderen Mitarbeitern verfasst wurden.
- Kundendienstmitarbeiter müssen die Möglichkeit haben, nach wichtigen Dokumenten zur Fehlerbehebung zu suchen, um sie an Kunden senden zu können.
- Mitarbeiter müssen interne Informationen zu Unternehmensprojekten finden können.
- Ein Vertriebsmitarbeiter möchte sich den Status aller Supportanfragen eines bestimmten Kunden anzeigen lassen.
- Mitarbeiter wünschen sich eine Definition für einen unternehmensspezifischen Begriff.
Der erste Schritt bei der Implementierung von Cloud Search ist, die relevanten Anwendungsfälle zu ermitteln.
Cloud Search implementieren
Daten aus Google Workspace, z. B. aus Google-Dokumenten und ‑Tabellen, werden standardmäßig von Cloud Search indexiert. Dieser Dienst muss für Google Workspace-Daten also nicht extra implementiert werden. Für Daten, die nicht aus Google Workspace stammen, sondern z. B. aus einer Datenbank eines Drittanbieters, aus einem Dateisystem wie Windows File Share oder OneDrive oder aus Intranetportalen wie SharePoint, ist eine Implementierung von Cloud Search jedoch Grundvoraussetzung. Gehen Sie dazu bitte folgendermaßen vor:
- Ermitteln Sie einen Anwendungsfall, für den Cloud Search hilfreich ist.
- Identifizieren Sie die für den Anwendungsfall relevanten Repositories.
- Identifizieren Sie die Identitätssysteme, die Ihr Unternehmen verwendet, um den Zugriff auf die Daten in den einzelnen Repositories zu steuern.
- Konfigurieren Sie den Zugriff auf die Google Cloud Search API.
- Fügen Sie Cloud Search eine Datenquelle hinzu.
- Erstellen und registrieren Sie ein Schema für jede Datenquelle.
- Stellen Sie fest, ob für Ihr Repository ein Inhaltsconnector verfügbar ist. Eine Liste vorkonfigurierter Connectors finden Sie im Verzeichnis der Cloud Search-Connectors. Ist ein Inhaltsconnector verfügbar, fahren Sie mit Schritt 9 fort.
- Erstellen Sie einen Inhaltsconnector um auf die Daten in den einzelnen Repositories zugreifen zu können. Starten Sie dann die Indexierung, um sie in eine Cloud Search-Datenquelle aufzunehmen.
- Ermitteln Sie, ob Sie einen Identitätsconnectorbenötigen. Falls nicht, fahren Sie mit Schritt 11 fort.
- Erstellen Sie einen Identitätsconnector um Ihr Repository oder Ihre Unternehmensidentitäten Google-Identitäten zuzuordnen.
- Richten Sie Suchanwendungen ein.
- Erstellen Sie eine Suchoberfläche für Suchabfragen.
- Stellen Sie Ihre Connectors und Suchoberflächen bereit. Wenn Sie einen vorkonfigurierten Connector verwenden wollen, folgen Sie der Anleitung, um den Connector zu erhalten und bereitzustellen. Verfügbare Connectors sind im Verzeichnis der Cloud Search-Connectors aufgeführt.
Nächste Schritte
- Testen Sie das Tutorial: Einführung in Cloud Search.
- Bestimmen Sie die Anwendungsfälle für Cloud Search.
- Identifizieren Sie die für diese Anwendungsfälle relevanten Repositories.
- Identifizieren Sie alle Identitätssysteme, die von diesen Repositories verwendet werden.
- Konfigurieren Sie den Zugriff auf die Cloud Search API.