
Interfejs Google Docs API umożliwia dostęp do treści z dowolnej karty w dokumencie.
Czym są karty?
Dokumenty Google mają warstwę organizacyjną zwaną kartami. Dokumenty umożliwiają tworzenie jednej lub większej liczby kart w jednym dokumencie, podobnie jak w Arkuszach. Każda karta ma własny tytuł i identyfikator (dołączony do adresu URL). Karta może też mieć karty podrzędne, czyli karty zagnieżdżone pod inną kartą.
zmiany strukturalne w sposobie reprezentowania treści dokumentu w zasobie dokumentu;
W przeszłości dokumenty nie miały koncepcji kart, więc zasób Document bezpośrednio zawierał całą treść tekstową w tych polach:
document.bodydocument.headersdocument.footersdocument.footnotesdocument.documentStyledocument.suggestedDocumentStyleChangesdocument.namedStylesdocument.suggestedNamedStylesChangesdocument.listsdocument.namedRangesdocument.inlineObjectsdocument.positionedObjects
Dzięki dodatkowej hierarchii strukturalnej kart te pola nie reprezentują już semantycznie treści tekstowych ze wszystkich kart w dokumencie. Treści tekstowe są teraz reprezentowane w innej warstwie. Właściwości kart i treści w Dokumentach Google są dostępne za pomocą document.tabs, czyli listy obiektów Tab, z których każdy zawiera wszystkie wymienione powyżej pola treści tekstowej. W dalszych sekcjach znajdziesz krótkie omówienie, a w sekcji Reprezentacja JSON karty znajdziesz bardziej szczegółowe informacje.
Właściwości karty dostępu
Dostęp do właściwości karty uzyskasz za pomocą tab.tabProperties, które zawierają informacje takie jak identyfikator, tytuł i położenie karty.
Dostęp do treści tekstowych na karcie
Rzeczywista zawartość dokumentu na karcie jest widoczna jako tab.documentTab.
Wszystkie wymienione wyżej pola treści tekstowych są dostępne za pomocą symbolutab.documentTab. Na przykład zamiast document.body użyj document.tabs[indexOfTab].documentTab.body.
Hierarchia kart
Karty podrzędne są reprezentowane w interfejsie API jako pole
tab.childTabs w Tab. Aby uzyskać dostęp do wszystkich kart w dokumencie, musisz przejść przez „drzewo” kart podrzędnych. Załóżmy na przykład, że dokument zawiera hierarchię kart w tej postaci:
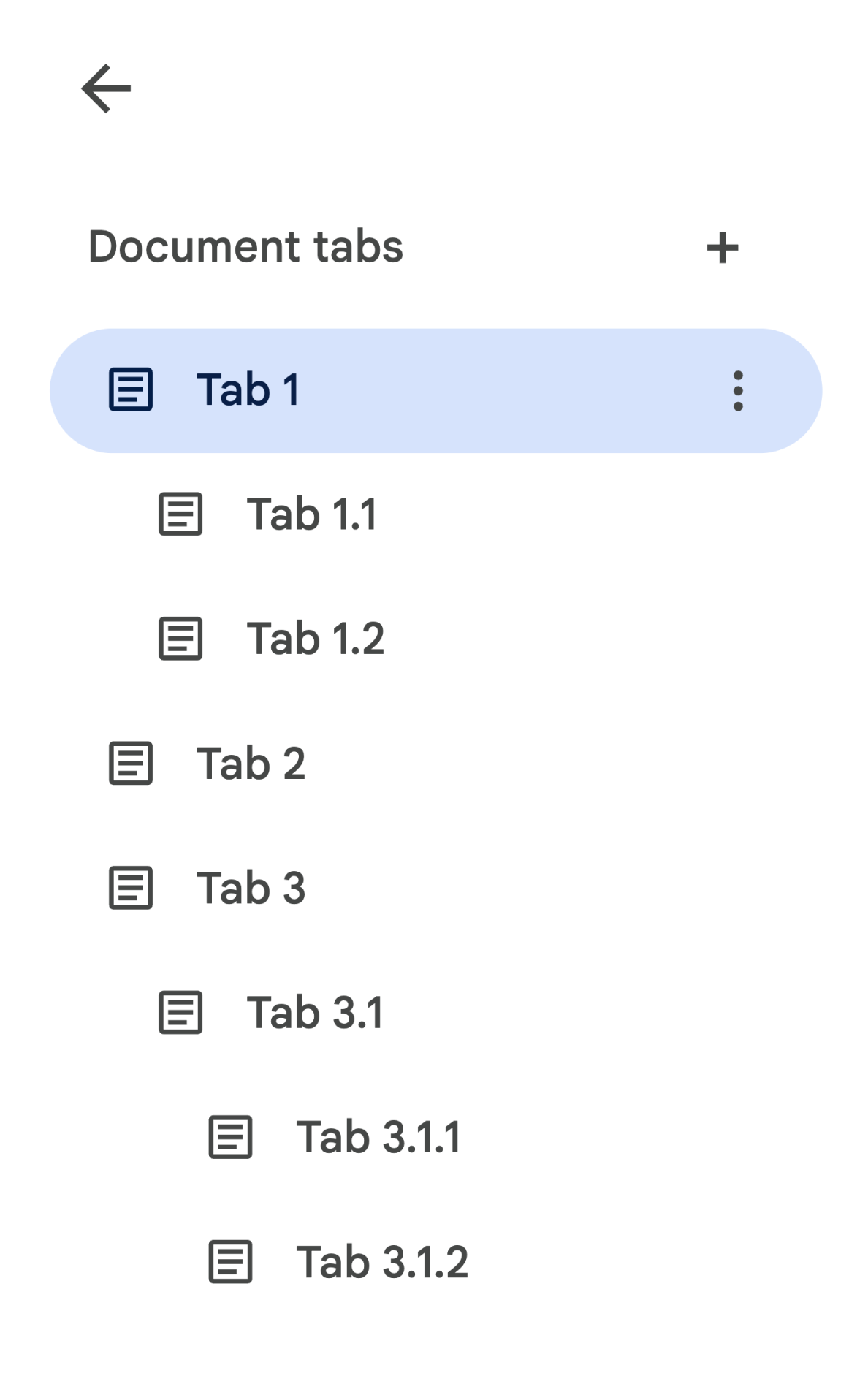
Aby pobrać Body z karty 3.1.2, musisz uzyskać dostęp do document.tabs[2].childTabs[0].childTabs[1].documentTab.body. W dalszej części znajdziesz przykładowe bloki kodu, które pokazują, jak iterować po wszystkich kartach w dokumencie.
Zmiany metod
Wraz z wprowadzeniem kart w każdej z metod dokumentu wprowadzono kilka zmian, które mogą wymagać aktualizacji kodu.
documents.get
Domyślnie nie są zwracane wszystkie treści kart. Deweloperzy powinni zaktualizować kod, aby uzyskać dostęp do wszystkich kart. Metoda documents.get udostępnia parametr includeTabsContent, który umożliwia skonfigurowanie, czy w odpowiedzi mają być podawane treści ze wszystkich kart.
- Jeśli parametr
includeTabsContentma wartośćtrue, metodadocuments.getzwraca zasóbDocumentz wypełnionym polemdocument.tabs. Wszystkie pola tekstowe bezpośrednio na stroniedocument(np.document.body) pozostaną puste. - Jeśli nie podasz wartości
includeTabsContent, pola tekstowe w zasobieDocument(np.document.body) zostaną wypełnione treścią tylko z pierwszej karty. Poledocument.tabsbędzie puste, a treści z innych kart nie zostaną zwrócone.
documents.create
Metoda documents.create zwraca zasób Document reprezentujący utworzony pusty dokument. Zwrócony zasób Document wypełni puste treści dokumentu zarówno w polach treści tekstowej dokumentu, jak i w document.tabs.
document.batchUpdate
Każda z nichRequest zawiera sposób określania kart, do których ma być zastosowana aktualizacja. Domyślnie, jeśli karta nie jest określona, w większości przypadków Request zostanie zastosowany do pierwszej karty w dokumencie.
ReplaceAllTextRequest, DeleteNamedRangeRequest i ReplaceNamedRangeContentRequest to 3 specjalne żądania, które domyślnie będą stosowane do wszystkich kart.
Szczegółowe informacje znajdziesz w dokumentacji Request.
Zmiany w linkach wewnętrznych
Użytkownicy mogą tworzyć linki wewnętrzne do kart, zakładek i nagłówków w dokumencie.
Wraz z wprowadzeniem funkcji kart pola link.bookmarkId i link.headingId w zasobie Link nie mogą już reprezentować zakładki ani nagłówka na konkretnej karcie w dokumencie.
Deweloperzy powinni zaktualizować kod, aby w operacjach odczytu i zapisu używać link.bookmark i link.heading. Udostępniają one linki wewnętrzne za pomocą obiektów BookmarkLink i HeadingLink, z których każdy zawiera identyfikator zakładki lub nagłówka oraz identyfikator karty, na której się znajduje. Dodatkowo link.tabId udostępnia linki wewnętrzne do kart.
Zawartość linku w odpowiedzi documents.get może się też różnić w zależności od parametru includeTabsContent:
- Jeśli zasada
includeTabsContentma wartośćtrue, wszystkie linki wewnętrzne będą widoczne jakolink.bookmarkilink.heading. Starsze pola nie będą już używane. - Jeśli wartość
includeTabsContentnie zostanie podana, w dokumentach zawierających jedną kartę wszystkie linki wewnętrzne do zakładek lub nagłówków na tej karcie będą nadal widoczne jakolink.bookmarkIdilink.headingId. W dokumentach zawierających wiele kart linki wewnętrzne będą wyświetlane jakolink.bookmarkilink.heading.
W przypadku document.batchUpdate, jeśli link wewnętrzny zostanie utworzony przy użyciu jednego z pól starszego typu, zakładka lub nagłówek będą pochodzić z identyfikatora karty określonego w elemencie Request. Jeśli nie określisz karty, zostanie ona uznana za pochodzącą z pierwszej karty w dokumencie.
Więcej informacji znajdziesz w reprezentacji JSON linku.
Typowe wzorce używania kart
Poniższe przykłady kodu opisują różne sposoby interakcji z kartami.
odczytywać zawartość kart ze wszystkich kart w dokumencie;
Istniejący kod, który robił to przed wprowadzeniem funkcji kart, można przenieść, aby obsługiwał karty, ustawiając parametr includeTabsContent na true, przechodząc przez hierarchię drzewa kart i wywołując metody pobierania z Tab i DocumentTab zamiast Document. Poniższy częściowy przykładowy kod jest oparty na fragmencie z artykułu Wyodrębnianie tekstu z dokumentu. Pokazuje, jak wydrukować całą zawartość tekstową z każdej karty w dokumencie. Ten kod przechodzenia między kartami można dostosować do wielu innych przypadków użycia, w których nie jest istotna rzeczywista struktura kart.
Java
/** Prints all text contents from all tabs in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from each tab in the document. for (Tab tab: allTabs) { // Get the DocumentTab from the generic Tab. DocumentTab documentTab = tab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); } } /** * Returns a flat list of all tabs in the document in the order they would * appear in the UI (top-down ordering). Includes all child tabs. */ private List<Tab> getAllTabs(Document doc) { List<Tab> allTabs = new ArrayList<>(); // Iterate over all tabs and recursively add any child tabs to generate a // flat list of Tabs. for (Tab tab: doc.getTabs()) { addCurrentAndChildTabs(tab, allTabs); } return allTabs; } /** * Adds the provided tab to the list of all tabs, and recurses through and * adds all child tabs. */ private void addCurrentAndChildTabs(Tab tab, List<Tab> allTabs) { allTabs.add(tab); for (Tab tab: tab.getChildTabs()) { addCurrentAndChildTabs(tab, allTabs); } } /** * Recurses through a list of Structural Elements to read a document's text * where text may be in nested elements. * * <p>For a code sample, see * <a href="https://developers.google.com/workspace/docs/api/samples/extract-text">Extract * the text from a document</a>. */ private static String readStructuralElements(List<StructuralElement> elements) { ... }
Odczytywanie zawartości karty Czytaj od pierwszej karty w dokumencie
Działa to podobnie do odczytywania wszystkich kart.
Java
/** Prints all text contents from the first tab in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from the first tab in the document. Tab firstTab = allTabs.get(0); // Get the DocumentTab from the generic Tab. DocumentTab documentTab = firstTab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); }
Prześlij prośbę o zaktualizowanie pierwszej karty
Poniższy fragment przykładowego kodu pokazuje, jak kierować reklamy na konkretną kartę w Request.
Ten kod jest oparty na przykładzie z przewodnika Wstawianie, usuwanie i przenoszenie tekstu.
Java
/** Inserts text into the first tab of the document. */ static void insertTextInFirstTab(Docs service, String documentId) throws IOException { // Get the first tab's ID. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); Tab firstTab = doc.getTabs().get(0); String tabId = firstTab.getTabProperties().getTabId(); List<Request>requests = new ArrayList<>(); requests.add(new Request().setInsertText( new InsertTextRequest().setText(text).setLocation(new Location() // Set the tab ID. .setTabId(tabId) .setIndex(25)))); BatchUpdateDocumentRequest body = new BatchUpdateDocumentRequest().setRequests(requests); BatchUpdateDocumentResponse response = docsService.documents().batchUpdate(<var>DOCUMENT_ID</var>, body).execute(); }