
API Google Docs позволяет получать доступ к содержимому из любой вкладки документа.
Что такое вкладки?
В Google Docs есть организационный слой, называемый вкладками . Docs позволяет пользователям создавать одну или несколько вкладок в одном документе, аналогично тому, как сейчас работают вкладки в Google Sheets. Каждая вкладка имеет свой заголовок и идентификатор (добавляется в URL-адрес). Вкладка также может иметь дочерние вкладки , которые вложены под другую вкладку.
Внесены структурные изменения в способ представления содержимого документа в ресурсе документа.
Раньше в документах не существовало понятия вкладок, поэтому ресурс Document содержал всё текстовое содержимое напрямую через следующие поля:
-
document.body -
document.headers -
document.footers -
document.footnotes -
document.documentStyle -
document.suggestedDocumentStyleChanges -
document.namedStyles -
document.suggestedNamedStylesChanges -
document.lists -
document.namedRanges -
document.inlineObjects -
document.positionedObjects
Благодаря дополнительной структурной иерархии вкладок, эти поля больше не представляют собой семантическое текстовое содержимое всех вкладок в документе. Текстовое содержимое теперь представлено на другом уровне. Свойства и содержимое вкладок в Google Docs доступны с помощью document.tabs , который представляет собой список объектов Tab , каждый из которых содержит все вышеупомянутые текстовые поля. В последующих разделах дается краткий обзор; более подробная информация также представлена в формате JSON для представления вкладок .
Свойства вкладки «Доступ»
Доступ к свойствам вкладки осуществляется с помощью tab.tabProperties , который содержит такую информацию, как идентификатор, заголовок и положение вкладки.
Доступ к текстовому содержимому внутри вкладки
Фактическое содержимое документа внутри вкладки отображается как tab.documentTab . Все упомянутые выше текстовые поля доступны через tab.documentTab . Например, вместо document.body следует использовать document.tabs[indexOfTab].documentTab.body .
Иерархия вкладок
Дочерние вкладки представлены в API в виде поля tab.childTabs объекта Tab . Для доступа ко всем вкладкам в документе необходимо пройтись по «дереву» дочерних вкладок. Например, рассмотрим документ, содержащий следующую иерархию вкладок:
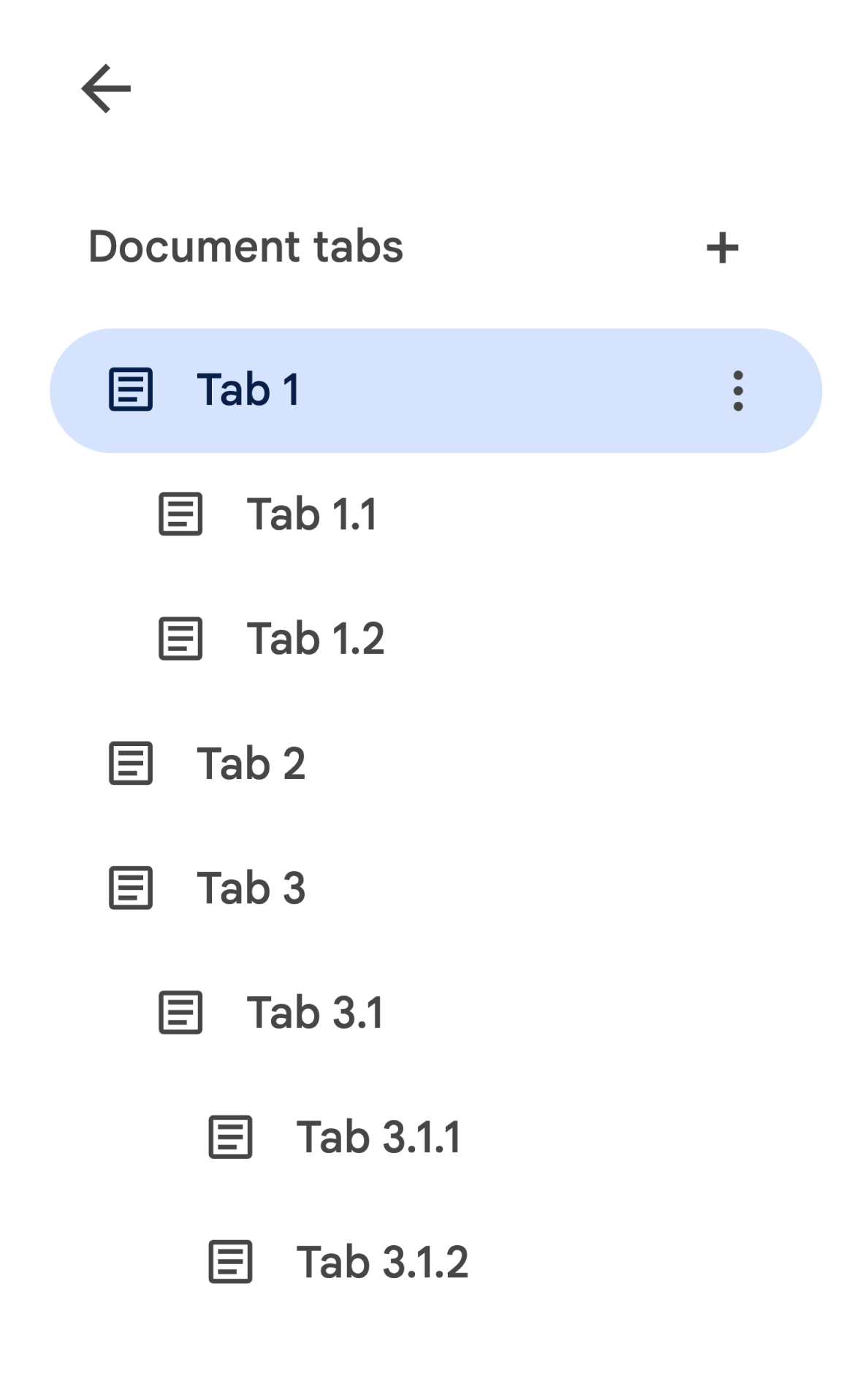
Чтобы получить Body вкладки 3.1.2 , вам нужно обратиться к document.tabs[2].childTabs[0].childTabs[1].documentTab.body . См. примеры кода в следующем разделе, где приведен пример кода для перебора всех вкладок в документе.
Изменения в методах
С появлением вкладок в каждом из методов работы с документами произошли некоторые изменения, которые могут потребовать обновления вашего кода.
документы.get
По умолчанию возвращается не всё содержимое вкладок. Разработчикам следует обновить свой код, чтобы обеспечить доступ ко всем вкладкам. Метод documents.get предоставляет параметр includeTabsContent , который позволяет настроить, будет ли в ответе предоставляться содержимое всех вкладок.
- Если
includeTabsContentустановлен вtrue, методdocuments.getвернет ресурсDocument, в котором полеdocument.tabsбудет заполнено. Все текстовые поля непосредственно вdocument(например,document.body) останутся пустыми. - Если
includeTabsContentне указан, текстовые поля в ресурсеDocument(например,document.body) будут заполнены содержимым только первой вкладки. Полеdocument.tabsбудет пустым, и содержимое других вкладок не будет возвращено.
документы.создать
Метод documents.create возвращает объект Document Resource, представляющий собой пустой созданный документ. Возвращенный объект Document Resource заполнит содержимое пустого документа как в текстовых полях, так и во document.tabs .
document.batchUpdate
Каждый Request включает в себя способ указания вкладок, к которым следует применить обновление. По умолчанию, если вкладка не указана, Request в большинстве случаев будет применен к первой вкладке документа. ReplaceAllTextRequest , DeleteNamedRangeRequest и ReplaceNamedRangeContentRequest — это три специальных запроса, которые по умолчанию будут применяться ко всем вкладкам.
Для получения более подробной информации обратитесь к документации по Request .
Изменения во внутренних ссылках
Пользователи могут создавать внутренние ссылки на вкладки, закладки и заголовки в документе. С появлением функции вкладок поля link.bookmarkId и link.headingId в ресурсе Link больше не могут представлять закладку или заголовок на конкретной вкладке в документе.
Разработчикам следует обновить свой код, чтобы использовать link.bookmark и link.heading в операциях чтения и записи. Они предоставляют доступ к внутренним ссылкам с помощью объектов BookmarkLink и HeadingLink , каждый из которых содержит идентификатор закладки или заголовка и идентификатор вкладки, в которой он находится. Кроме того, link.tabId предоставляет доступ к внутренним ссылкам на вкладки.
Содержимое ссылок в ответе от documents.get также может различаться в зависимости от параметра includeTabsContent :
- Если
includeTabsContentустановлен вtrue, все внутренние ссылки будут отображаться какlink.bookmarkиlink.heading. Устаревшие поля больше использоваться не будут. - Если
includeTabsContentне указан, то в документах, содержащих одну вкладку, любые внутренние ссылки на закладки или заголовки внутри этой единственной вкладки будут по-прежнему отображаться какlink.bookmarkIdиlink.headingId. В документах, содержащих несколько вкладок, внутренние ссылки будут отображаться какlink.bookmarkиlink.heading.
В document.batchUpdate , если внутренняя ссылка создается с использованием одного из устаревших полей, закладка или заголовок будут считаться принадлежащими к вкладке с идентификатором, указанным в Request . Если вкладка не указана, будет считаться, что ссылка ведет к первой вкладке документа.
JSON-представление ссылки предоставляет более подробную информацию.
Типичные модели использования вкладок
Приведенные ниже примеры кода описывают различные способы взаимодействия с вкладками.
Прочитать содержимое всех вкладок документа.
Существующий код, выполнявший эту функцию до появления вкладок, можно адаптировать для поддержки вкладок, установив параметр includeTabsContent в значение true , пройдясь по иерархии дерева вкладок и вызывая методы-геттеры из Tab и DocumentTab вместо Document . Следующий фрагмент кода основан на фрагменте, приведенном в статье «Извлечение текста из документа» . Он показывает, как распечатать все текстовые данные из каждой вкладки в документе. Этот код для обхода вкладок можно адаптировать для многих других случаев использования, которым не важна фактическая структура вкладок.
Java
/** Prints all text contents from all tabs in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from each tab in the document. for (Tab tab: allTabs) { // Get the DocumentTab from the generic Tab. DocumentTab documentTab = tab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); } } /** * Returns a flat list of all tabs in the document in the order they would * appear in the UI (top-down ordering). Includes all child tabs. */ private List<Tab> getAllTabs(Document doc) { List<Tab> allTabs = new ArrayList<>(); // Iterate over all tabs and recursively add any child tabs to generate a // flat list of Tabs. for (Tab tab: doc.getTabs()) { addCurrentAndChildTabs(tab, allTabs); } return allTabs; } /** * Adds the provided tab to the list of all tabs, and recurses through and * adds all child tabs. */ private void addCurrentAndChildTabs(Tab tab, List<Tab> allTabs) { allTabs.add(tab); for (Tab tab: tab.getChildTabs()) { addCurrentAndChildTabs(tab, allTabs); } } /** * Recurses through a list of Structural Elements to read a document's text * where text may be in nested elements. * * <p>For a code sample, see * <a href="https://developers.google.com/workspace/docs/api/samples/extract-text">Extract * the text from a document</a>. */ private static String readStructuralElements(List<StructuralElement> elements) { ... }
Прочитайте содержимое первой вкладки документа.
Это похоже на чтение всех вкладок.
Java
/** Prints all text contents from the first tab in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from the first tab in the document. Tab firstTab = allTabs.get(0); // Get the DocumentTab from the generic Tab. DocumentTab documentTab = firstTab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); }
Отправьте запрос на обновление первой вкладки.
Приведенный ниже фрагмент кода демонстрирует, как обратиться к определенной вкладке в Request . Этот код основан на примере из руководства по вставке, удалению и перемещению текста .
Java
/** Inserts text into the first tab of the document. */ static void insertTextInFirstTab(Docs service, String documentId) throws IOException { // Get the first tab's ID. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); Tab firstTab = doc.getTabs().get(0); String tabId = firstTab.getTabProperties().getTabId(); List<Request>requests = new ArrayList<>(); requests.add(new Request().setInsertText( new InsertTextRequest().setText(text).setLocation(new Location() // Set the tab ID. .setTabId(tabId) .setIndex(25)))); BatchUpdateDocumentRequest body = new BatchUpdateDocumentRequest().setRequests(requests); BatchUpdateDocumentResponse response = docsService.documents().batchUpdate(<var>DOCUMENT_ID</var>, body).execute(); }