La bibliothèque de sources de données de visualisation Google permet de créer facilement une source de données de visualisation. La bibliothèque met en œuvre le protocole de communication et le langage de requête de l'API Google Visualization. Vous n'écrivez que le code nécessaire pour rendre vos données disponibles dans la bibliothèque sous la forme d'une table de données. Une table de données est une table à valeurs bidimensionnelles dont chaque colonne est d'un seul type. L'écriture du code dont vous avez besoin est facilitée par la mise à disposition de classes abstraites et de fonctions d'assistance.
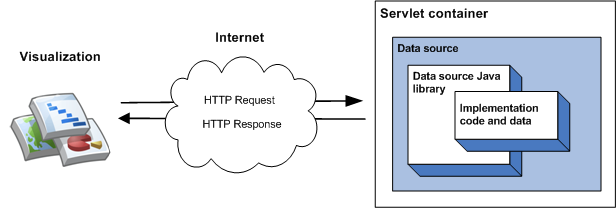
L'implémentation la plus simple de la bibliothèque consiste à hériter d'une classe unique, à mettre en œuvre une fonction de membre et à exécuter la source de données en tant que webhook dans un conteneur de partitionnement. Dans l'implémentation la plus simple, la séquence d'événements suivante se produit lorsqu'une visualisation interroge la source de données:
- Le conteneur de webhook gère la requête et la transmet à la bibliothèque Java de la source de données.
- La bibliothèque analyse la requête.
- Le code de mise en œuvre (le code que vous écrivez) renvoie une table de données à la bibliothèque.
- La bibliothèque exécute la requête sur la table de données.
- La bibliothèque affiche la table de données dans la réponse attendue par la visualisation.
- Le conteneur de webhook renvoie la réponse à la visualisation.
Cela est illustré dans le schéma suivant:
La section Premiers pas avec les sources de données explique comment mettre en œuvre ce type de source de données.
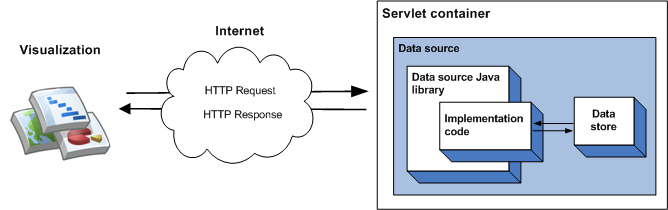
Les données diffusées par une source de données peuvent être spécifiées dans votre code de mise en œuvre, ce qui convient pour de petites quantités de données statiques. Pour les ensembles de données plus volumineux, il est plus probable que vous ayez besoin d'un datastore externe tel qu'un fichier ou une base de données externe. Si une source de données utilise un datastore externe, la séquence d'événements suivante se produit lorsqu'une visualisation interroge la source de données:
- Le conteneur de webhook gère la requête et la transmet à la bibliothèque Java de la source de données.
- La bibliothèque analyse la requête.
- Le code de mise en œuvre (le code que vous écrivez) lit les données conservées dans le datastore et renvoie une table de données à la bibliothèque. Si l'ensemble de données est volumineux et que le magasin de données dispose de fonctionnalités de requête, vous pouvez éventuellement utiliser ces fonctionnalités pour améliorer l'efficacité de votre source de données.
- La bibliothèque exécute la requête sur la table de données.
- La bibliothèque affiche la table de données dans la réponse attendue par la visualisation.
- Le conteneur de webhook renvoie la réponse à la visualisation.
Cela est illustré dans le schéma suivant:
La section Utiliser un datastore externe explique comment mettre en œuvre ce type de source de données.