本页介绍了如何使用设备端个性化提供的联邦学习 API,通过联邦平均学习过程和固定的正态噪声训练模型。
准备工作
在开始之前,请在测试设备上完成以下步骤:
确保已安装 OnDevicePersonalization 模块。该模块已于 2024 年 4 月以自动更新形式推出。
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncode确保以下模块列出了版本代码为 341717000 或更高版本:
package:com.google.android.ondevicepersonalization versionCode:341717000如果该模块未列出,请依次转到设置 > 安全和隐私 > 更新 > Google Play 系统更新,确保您的设备是最新版本。根据需要选择更新。
启用所有与联邦学习相关的新功能。
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
创建联合学习任务

图中的数字编号在以下八个步骤中进行了详细说明。
配置联邦计算服务器
联合学习是一种映射缩减技术,在联合计算服务器(缩减器)和一组客户端(映射器)上运行。联合计算服务器维护每个联合学习任务的运行元数据和模型信息。概括来讲:
- 联邦学习开发者创建新任务,并将任务运行元数据和模型信息上传到服务器。
- 当联邦计算客户端向服务器发起新的任务分配请求时,服务器会检查任务的资格条件,并返回符合条件的任务信息。
- 联邦计算客户端完成本地计算后,会将这些计算结果发送到服务器。然后,服务器对这些计算结果执行聚合和噪声处理,并将结果应用到最终模型。
如需详细了解这些概念,请查看:
ODP 使用增强型版本的联邦学习,也就是先将校准(集中)的噪声应用于汇总,然后再应用到模型。噪声的规模可确保汇总数据能保持差分隐私。
第 1 步:创建联合计算服务器
按照联邦计算项目中的说明设置您自己的联邦计算服务器。
第 2 步:准备已保存的 FunctionalModel
准备已保存的 'FunctionalModel' 文件。您可以使用 'functional_model_from_keras' 将 'Model' 转换为 'FunctionalModel',并使用 'save_functions_model' 将此 'FunctionalModel' 序列化为 'SavedModel'。
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
第 3 步:创建联合计算服务器配置
准备一个 fcp_server_config.json,其中包含政策、联邦学习设置和差分隐私设置。示例:
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
第 4 步:将 ZIP 配置提交到联邦计算服务器。
将 zip 文件和 fcp_server_config.json 提交到联邦计算服务器。
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
联合计算服务器端点是您在第 1 步中设置的服务器。
LiteRT 内置运算符库仅支持少数 TensorFlow 运算符(部分 TensorFlow 运算符)。支持的运算符集可能会因 OnDevicePersonalization 模块的不同版本而异。为了确保兼容性,系统会在任务创建期间在任务构建器中执行操作员验证流程。
任务元数据中将包含支持的最低 OnDevicePersonalization 模块版本。您可以在任务制作工具的信息消息中找到此信息。
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }联邦计算服务器将向所有搭载版本高于 341812000 的 OnDevicePersonalization 模块的设备分配此任务。
如果您的模型包含任何 OnDevicePersonalization 模块不支持的操作,系统会在任务创建期间生成错误消息。
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.您可以在 GitHub 上找到受支持的 flex 运算的详细列表。
创建 Android 联邦计算 APK
如需创建 Android 联邦计算 APK,您需要在 AndroidManifest.xml 中指定联邦计算服务器网址端点,联邦计算客户端会连接到该端点。
第 5 步:指定联邦计算服务器网址端点
在 AndroidManifest.xml 中指定您的联邦计算服务器网址端点(您在第 1 步中设置的),联邦计算客户端将连接到该端点。
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
<property> 标记中指定的 XML 资源文件还必须在 <service> 标记中声明服务类,并指定联邦计算客户端将连接到的联邦计算服务器网址端点:
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
第 6 步:实现 IsolatedWorker#onTrainingExample API
实现设备端个性化公共 API IsolatedWorker#onTrainingExample 以生成训练数据。
在 IsolatedProcess 中运行的代码无法直接访问网络、本地磁盘或设备上运行的其他服务;不过,可以使用以下 API:
- “getRemoteData” - 从开发者运营的远程后端下载的不可变键值对数据(如果适用)。
- 'getLocalData' - 开发者在本地保留的可变键值对数据(如果适用)。
- “UserData” - 平台提供的用户数据。
- 'getLogReader' - 为 REQUESTS 和 EVENTS 表返回 DAO。
示例:
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
第 7 步:安排周期性训练任务。
设备端个性化提供了 FederatedComputeScheduler,供开发者调度或取消联邦计算作业。通过 IsolatedWorker 调用它有多种方式,可以按计划调用,也可以在异步下载完成时调用。下面给出了这两种方法的示例。
基于时间表的选项。致电
FederatedComputeScheduler#schedule(位于IsolatedWorker#onExecute)。@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }下载完成选项。如果调度训练任务依赖于任何异步数据或进程,请在
IsolatedWorker#onDownloadCompleted中调用FederatedComputeScheduler#schedule。
验证
以下步骤介绍了如何验证联邦学习任务是否正常运行。
第 8 步:验证联邦学习任务是否正常运行。
每一轮服务器端汇总时都会生成一个新的模型检查点和一个新的指标文件。
这些指标位于 JSON 格式的键值对文件中。该文件由您在第 3 步中定义的 Metrics 列表生成。下面给出了一个具有代表性的指标 JSON 文件示例:
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
您可以使用类似以下脚本的内容来获取模型指标并监控训练性能:
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()
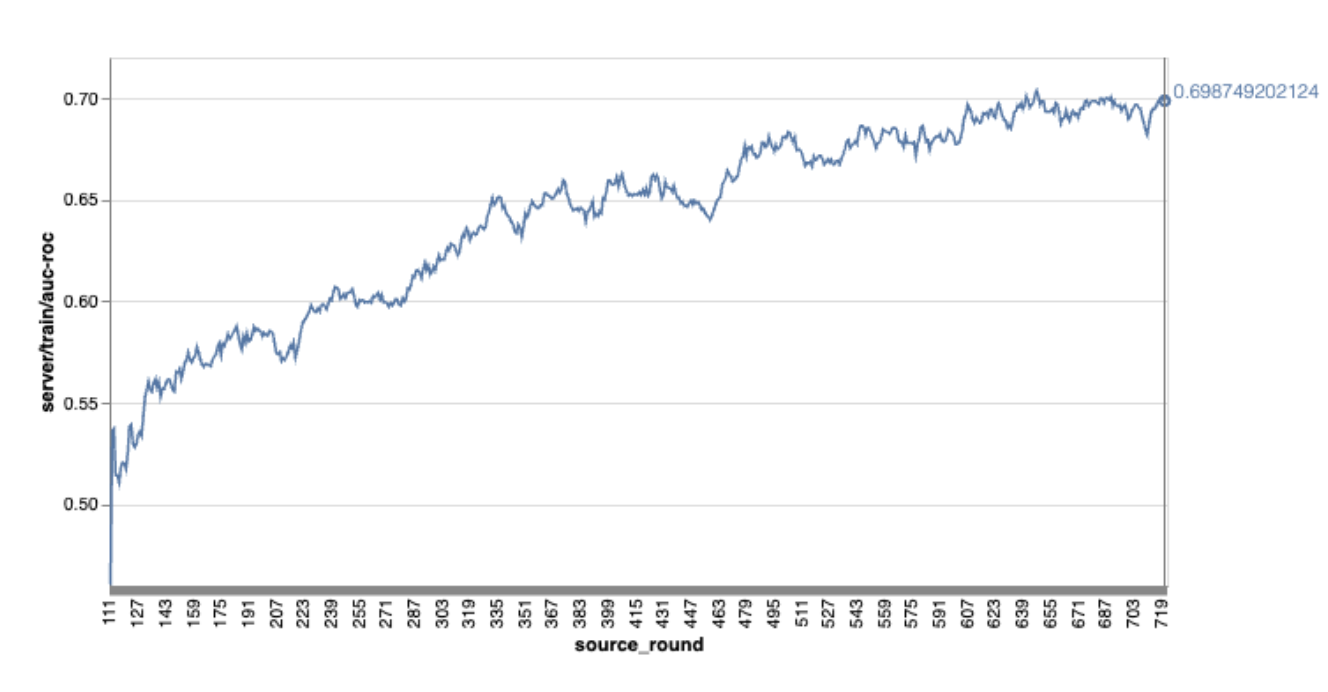
请注意,在上例图表中:
- x 轴表示训练次数。
- y 轴是每轮 auc-roc 的值。
在设备端个性化中训练图片分类模型
在本教程中,EMNIST 数据集用于演示如何在 ODP 上运行联合学习任务。
第 1 步:创建 tff.learning.models.FunctionalModel
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- 您可以在 emnist_models 中找到 emnist keras 模型的详细信息。
- TfLite 尚不能很好地支持 tf.sparse.SparseTensor 或 tf.RaggedTensor。构建模型时,尽可能多地使用 tf.Tensor。
- 在构建学习流程时,ODP Task Builder 会覆盖所有指标,无需指定任何指标。该主题将在第 2 步:创建任务构建器配置。
支持两种类型的模型输入:
类型 1. 元组(特征张量、标签张量)。
- 创建模型时,input_spec 如下所示:
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- 将上述内容与 ODP 公共 API IsolatedWorker#onTrainingExamples 的以下实现配对,以在设备上生成训练数据:
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()类型 2.
Tuple(Dict[feature_name, feature_tensor], label_tensor)- 创建模型时,input_spec 如下所示:
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- 将上述内容与 ODP 公共 API IsolatedWorker#onTrainingExamples 的以下实现配对,以生成训练数据:
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- 别忘了在任务构建器配置中注册 label_name。
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
ODP 在构建学习过程时自动处理 DP。因此,在创建函数式模型时无需添加任何噪声。
此已保存的函数模型的输出应与 GitHub 代码库中的示例类似。
第 2 步:创建任务构建器配置
您可以在我们的 GitHub 代码库中找到任务构建器配置示例。
训练和评估指标
鉴于指标可能会泄露用户数据,任务构建器将列出学习过程可以生成和发布的指标。您可以在我们的 GitHub 代码库中找到完整列表。
以下是创建新的任务构建器配置时的指标列表示例:
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
如果您感兴趣的指标不在当前列表中,请与我们联系。
DP 配置
您需要指定一些与 DP 相关的配置:
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }- 存在
dp_target_epsilon或noise_mulitipiler以通过验证:(noise_to_epsilonepislon_to_noise)。 - 您可以在我们的 GitHub 代码库中找到这些默认设置。
- 存在
第 3 步:将保存的模型和任务构建器配置上传到任何开发者的云端存储空间
上传任务构建器配置时,请务必更新 artifact_building 字段。
第 4 步:(可选)在不创建新任务的情况下构建测试工件
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
示例模型通过 Flex 操作检查和 dp 检查进行验证;您可以添加 skip_flex_ops_check 和 skip_dp_check,以便在验证期间绕过(由于一些缺少的 Flex 操作,此模型无法部署到当前版本的 ODP 客户端)。
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check:TensorFlow Lite 内置运算符库仅支持少数的 TensorFlow 运算符(TensorFlow Lite 与 TensorFlow 运算符的兼容性)。所有不兼容的 TensorFlow 操作都需要使用 flex 委托 (Android.bp) 进行安装。如果模型包含不受支持的运算,请与我们联系以进行注册:
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}调试任务构建器的最佳方法是在本地启动一个任务构建器:
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
您可以在配置中指定的云端存储空间中找到生成的工件。它应该与 GitHub 代码库中的示例类似。
第 5 步:构建工件,并在 FCP 服务器上创建一对新的训练和评估任务。
移除 build_artifact_only 标志,系统会将构建的工件上传到 FCP 服务器。您应检查是否成功创建了一对训练和评估任务
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
第 6 步:准备好 FCP 客户端
- 实现 ODP 公共 API
IsolatedWorker#onTrainingExamples以生成训练数据。 - 调用
FederatedComputeScheduler#schedule。 - 在我们的 Android 源代码库中查找一些示例。
第 7 步:监控
服务器指标
在我们的 GitHub 代码库中查找设置说明。
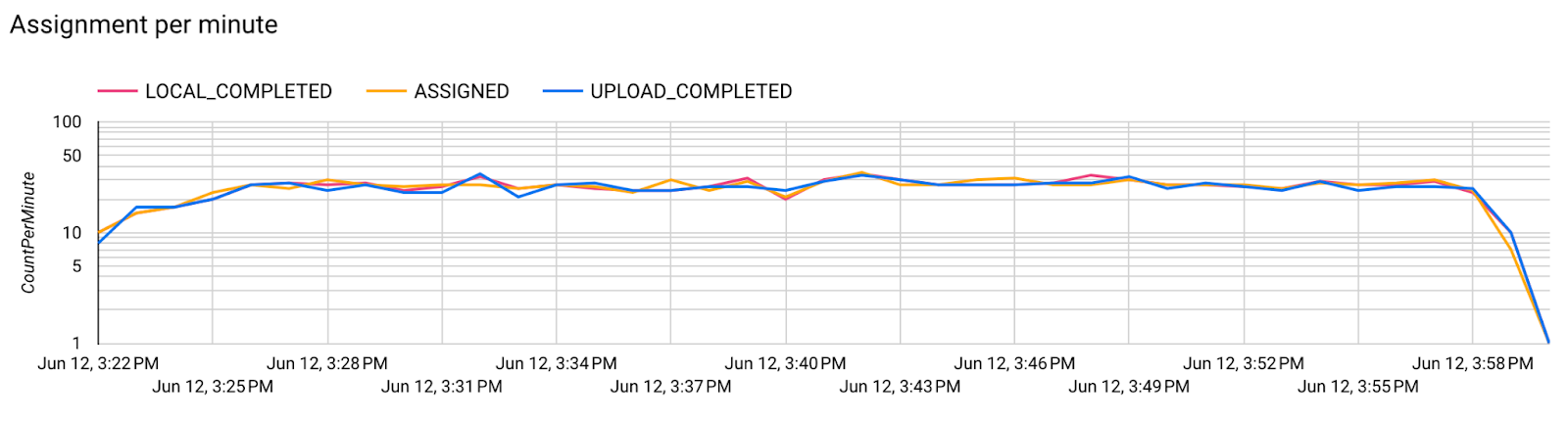
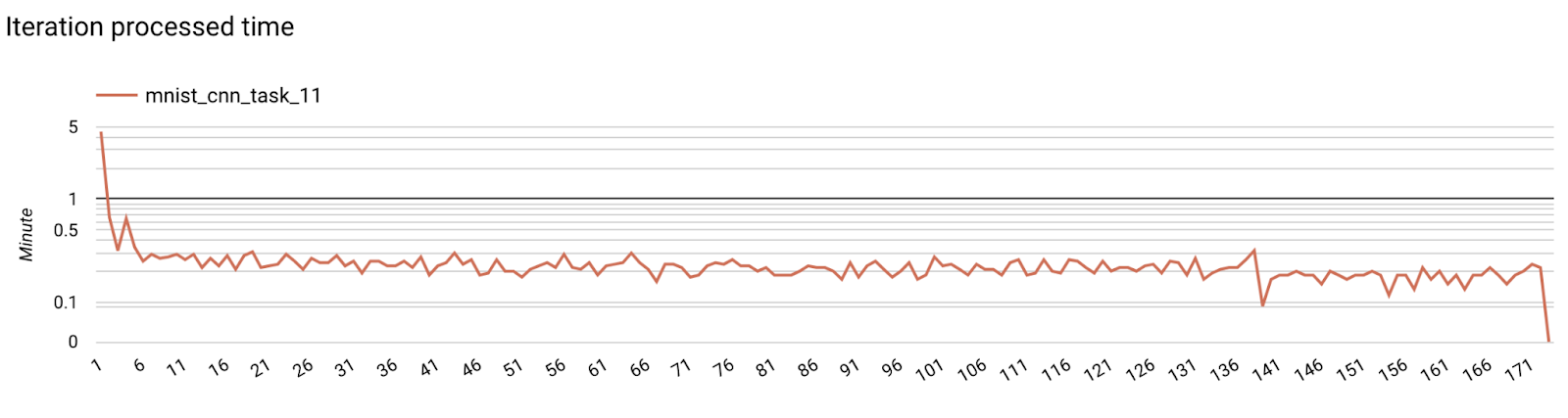
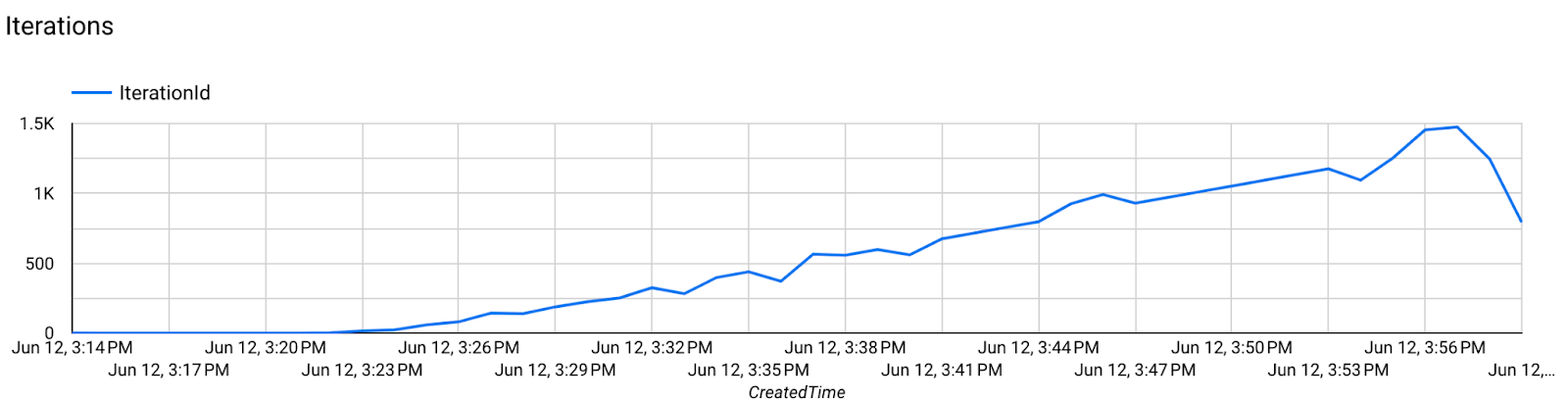
- 模型指标
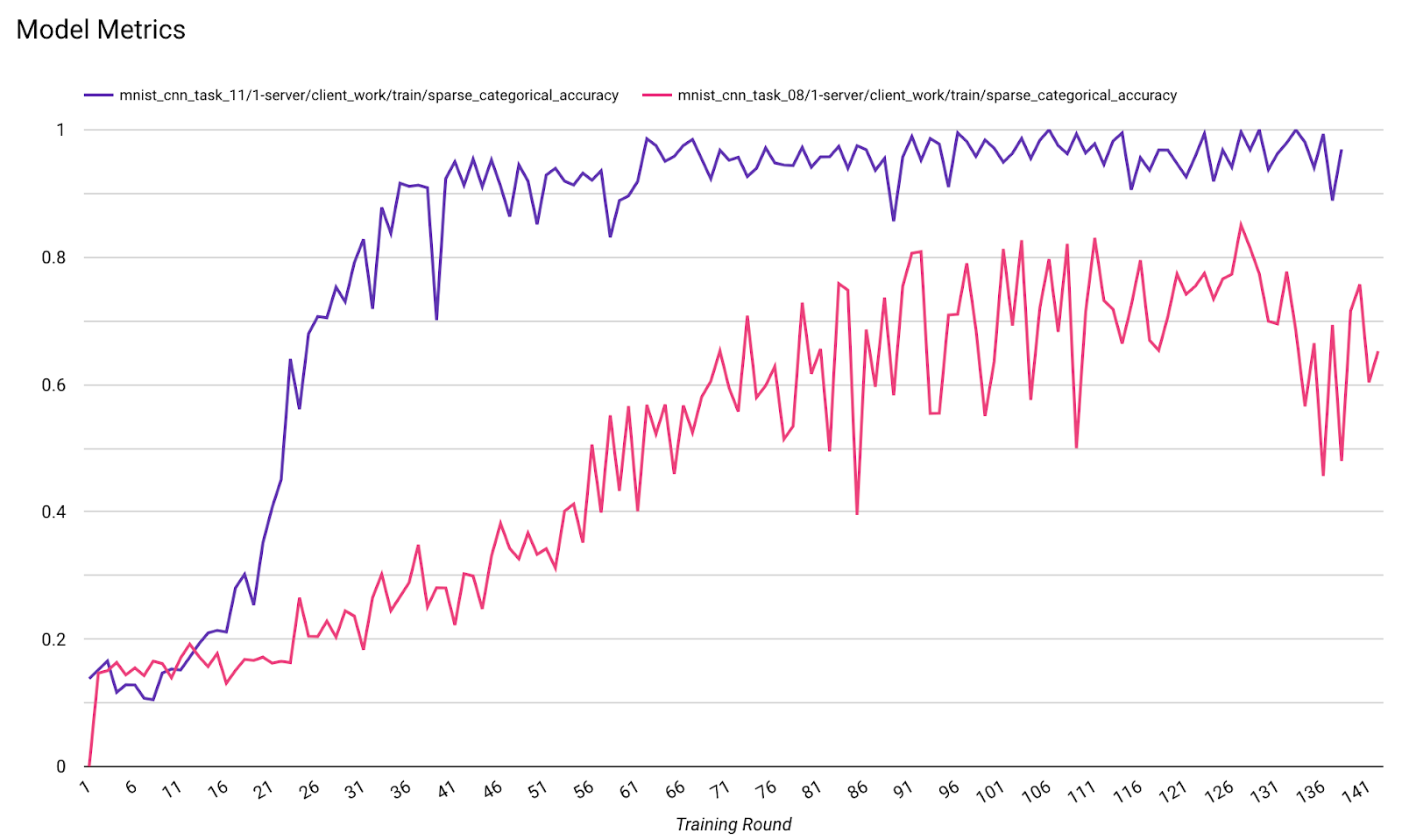
您可以在一个图表中比较不同运行的各项指标。例如:
- 紫色线条的
noise_multiplier为 0.1 - 粉色线条表示
noise_multipiler0.3