数据集(Dataset、DataCatalog、DataDownload)结构化数据
如果您以结构化数据的形式提供数据集的支持信息(如名称、说明、创建者和分发格式),可让用户更轻松地在数据集搜索工具中找到相应数据集。Google 的数据集发现方法利用了 schema.org 和其他元数据标准,这些标准可以添加到描述数据集的页面中。此标记的目的是提高生命科学、社会科学、机器学习、民众和政府数据等领域的数据集的曝光率。
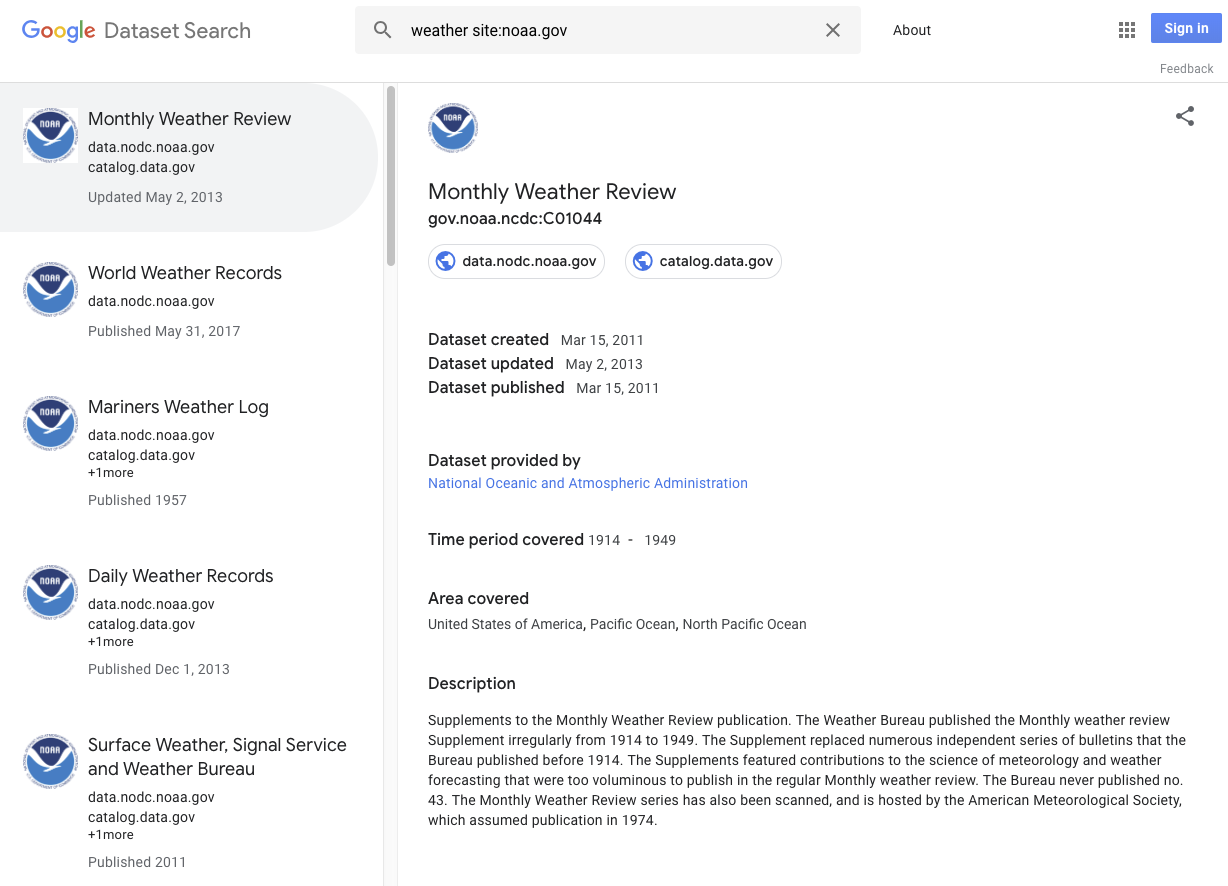
下面列举了一些示例来说明哪些内容能算作数据集:
- 包含某些数据的表格或 CSV 文件
- 组织有序的表格集合
- 采用专有格式的文件,其中包含数据
- 可共同构成某个有意义数据集的一组文件
- 包含其他格式的数据的结构化对象,您可能希望将其加载到特殊工具中进行处理
- 捕获数据的图像
- 与机器学习相关的文件,如经过训练的参数或神经网络结构定义
如何添加结构化数据
结构化数据是一种提供网页相关信息并对网页内容进行分类的标准化格式。如果您不熟悉结构化数据,可以详细了解结构化数据的运作方式。
下面概述了如何构建、测试和发布结构化数据。如需获得向网页添加结构化数据的分步指南,请查看结构化数据 Codelab。
- 添加必要属性。根据您使用的格式,了解在网页上的什么位置插入结构化数据。
- 遵循指南。
- 使用富媒体搜索结果测试验证您的代码,并修复所有严重错误。此外,您还可以考虑修正该工具中可能会标记的任何非严重问题,因为这些这样有助于提升结构化数据的质量(不过,要使内容能够显示为富媒体搜索结果,并非必须这么做)。
- 部署一些包含您的结构化数据的网页,然后使用网址检查工具测试 Google 看到的网页样貌。请确保您的网页可供 Google 访问,不会因 robots.txt 文件、
noindex标记或登录要求而被屏蔽。如果网页看起来没有问题,您可以请求 Google 重新抓取您的网址。 - 为了让 Google 随时了解日后发生的更改,我们建议您提交站点地图。Search Console Sitemap API 可以帮助您自动执行此操作。
从数据集搜索结果中删除数据集
如果您不希望某个数据集显示在数据集搜索结果中,请使用 robots meta 标记控制系统如何将数据集编入索引。请注意,所做的更改可能需要过一段时间(几天或几周,具体取决于抓取时间表)才能体现在数据集搜索结果中。
我们的数据集发现方法
我们可以通过 schema.org Dataset 标记或以 W3C 的数据目录词汇表 (DCAT) 格式所表示的等效结构,理解网页中关于数据集的结构化数据。我们还在探索如何基于 W3C CSVW 针对结构化数据提供实验性支持,并希望随着数据集说明最佳做法的出现,不断改进和调整我们的方法。如需详细了解我们的数据集发现方法,请参阅使数据集更易于发现。
示例
以下是在富媒体搜索结果测试中使用 JSON-LD 和 schema.org 语法(首选)的数据集示例。同样的 schema.org 词汇表也可用于 RDFa 1.1 或微数据语法。 您还可以使用 W3C DCAT 词汇表描述元数据。以下示例基于实际数据集说明。
下面是一个 JSON-LD 格式的数据集示例:
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>下面是一个使用 DCAT 词汇表的 RDFa 格式的数据集示例(富媒体搜索结果测试不支持):
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>指南
网站必须遵循结构化数据指南。除了结构化数据指南之外,我们还建议您遵循下列站点地图以及来源和出处最佳实践。
站点地图最佳实践
您可以使用站点地图文件帮助 Google 找到您的网址。使用站点地图文件和 sameAs 标记有助于记录您的整个网站中数据集说明的发布情况。
如果您有数据集集合,那么很可能至少有两种类型的网页:每个数据集的规范网页(“着陆页”)以及列出多个数据集的网页(例如,搜索结果或数据集的某个子集)。我们建议您将有关数据集的结构化数据添加到规范网页。如果您将结构化数据添加到数据集的多个副本(如搜索结果页中的列表),请使用 sameAs 属性链接到规范网页。
来源和出处最佳实践
开放数据集往往会重新发布、进行汇总并以其他数据集为基础。在某些情况下,一个数据集是另一个数据集的副本或基于另一个数据集。下面给出了一个初步的大纲,大体概括了我们表示这些情况的方法。
- 如果数据集或说明直接使用了别处发布的材料,请使用
sameAs属性指示原始数据集或说明的最规范网址。sameAs的值需要明确指明数据集的身份,换句话说,不要对两个不同的数据集使用相同的sameAs值。 - 如果重新发布的数据集(包括其元数据)发生了显著的变化,请使用
isBasedOn属性。 - 如果某个数据集源自多个原始数据集或是对多个原始数据集的汇总,请使用
isBasedOn属性。 - 使用
identifier属性附加任何相关的数字对象标识符 (DOI) 或紧凑型标识符。如果数据集具有多个标识符,请重复使用identifier属性。如果使用 JSON-LD,则使用 JSON 列表语法进行表示。
我们希望根据反馈改进我们的建议,特别是关于出处、版本控制以及与时间序列出版物关联的日期的说明。欢迎加入社区讨论。
文字属性建议
我们建议所有文字属性的长度均不超过 5000 个字符。Google 数据集搜索仅使用所有文字属性的前 5000 个字符。名称和标题通常是几个单词或一个短句。
已知错误和警告
您可能会在 Google 的富媒体搜索结果测试和其他验证系统中遇到错误或警告。具体来说,验证系统可能会建议组织必须包含联系信息,其中包括 contactType;有用的值包括 customer service、emergency、journalist、newsroom 和 public engagement。如果错误指出 csvw:Table 不是 mainEntity 属性的预期值,您也可以忽略该错误。
结构化数据类型定义
若要使您的内容能够显示为富媒体搜索结果,您必须为其添加必要属性。还有一些建议添加的属性,能帮助您添加更多与您的内容相关的信息,进而提供更好的用户体验。
您可以使用富媒体搜索结果测试来验证标记。
重点是描述有关数据集(其元数据)的信息并表示其内容。例如,数据集元数据可以指明数据集的具体内容、测量的变量、创建者,等等。但它不包含诸如变量的特定值之类的内容。
Dataset
如需了解 Dataset 的完整定义,请访问 schema.org/Dataset。
您可以描述有关数据集发布的其他信息,如许可、发布时间、其 DOI,或指向其他集合中相应数据集规范版本的 sameAs。请为提供出处和许可信息的数据集添加 identifier、license 和 sameAs。
Google 支持的属性如下:
| 必要属性 | |
|---|---|
description
|
Text
描述数据集的简短摘要。 指南
|
name
|
Text
数据集的描述性名称。例如,“北半球积雪深度”。 指南
建议:用 不建议:用 |
| 建议属性 | |
|---|---|
alternateName
|
Text
引用此数据集所用的备用名称,如别名或缩写。示例(采用 JSON-LD 格式): "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person 或 Organization
相应数据集的创建者或作者。如需对个人进行唯一标识,请使用 ORCID ID 作为 "creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text 或 CreativeWork
除数据集本身外,还标识所引用的数据提供商建议的学术文章。将数据集本身的引用信息与其他属性一起提供,如 "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" 其他指南
|
funder
|
Person 或 Organization
对此数据集提供资金支持的个人或组织。如需对个人进行唯一标识,请使用 ORCID ID 作为 "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart 或 isPartOf
|
URL 或 Dataset
如果数据集是较小数据集的集合,请使用 "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL、Text 或 PropertyValue
一个标识符,例如 DOI 或紧凑型标识符。如果数据集具有多个标识符,请重复使用 |
isAccessibleForFree
|
Boolean
数据集是否可免费访问。 |
keywords
|
Text
总结数据集的关键字。 |
license
|
URL 或 CreativeWork
分发数据集所依据的许可。例如: "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } 其他指南
|
measurementTechnique
|
Text 或 URL
数据集采用的分析法、技术或方法,可与 |
sameAs
|
URL
明确指明了数据集身份的参考网页对应的网址。 |
spatialCoverage |
Text 或 Place
您可以提供单个坐标点,从空间方面对数据集进行描述。仅当数据集具有空间维度时,才应添加此属性。例如,收集所有测量值时所在的单个坐标点,或某个区域的边界框的坐标。 坐标点 "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } 形状 使用 "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } }
带名称的地点 "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
数据集中的数据涵盖特定的时间间隔。仅当数据集具有时间维度时,才应添加此属性。Schema.org 使用 ISO 8601 标准来描述时间间隔和时间点。您可以采用不同的方式来描述日期,具体取决于数据集的时间间隔。用两个小数点 ( 单个日期 "temporalCoverage" : "2008" 时间段 "temporalCoverage" : "1950-01-01/2013-12-18" 开放式时间段 "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text 或 PropertyValue
相应数据集测量的变量。例如,温度或压力。 |
version
|
Text 或 Number
数据集的版本号。 |
url
|
URL
描述数据集的网页位置。 |
DataCatalog
如需了解 DataCatalog 的完整定义,请访问 schema.org/DataCatalog。
发布某些数据集的集合往往包含许多其他数据集。同一数据集可以包含在多个这样的仓库中。您可以使用以下属性,通过直接引用该数据集来引用它所属的数据目录:
| 建议属性 | |
|---|---|
includedInDataCatalog
|
DataCatalog
数据集所属的目录。
|
DataDownload
如需了解 DataDownload 的完整定义,请访问 schema.org/DataDownload。除了数据集属性之外,您还可以为提供下载选项的数据集添加以下属性。
distribution 属性用来描述如何获取数据集本身,因为网址通常指向描述数据集的着陆页。此外,distribution 属性还可描述获取数据的位置和格式。此属性可以有多个值:例如,使用一个网址分发 CSV 版本,而使用另一个网址分发 Excel 版本。
| 必要属性 | |
|---|---|
distribution.contentUrl
|
URL
下载链接。 |
| 建议属性 | |
|---|---|
distribution
|
DataDownload
数据集的下载位置和下载文件格式的说明。
|
distribution.encodingFormat
|
Text 或 URL
分发的文件格式。
|
表格数据集
表格数据集是一种主要以网格(由行和列组成)的形式组织而成的数据集。对于嵌入表格数据集的网页,您还可以基于基本方法创建更明确的标记。目前,我们能理解 CSVW(“网络上的 CSV”,请参阅 W3C)的一种变体,它与 HTML 网页上面向用户的表格内容并行提供。
下面是一个以 CSVW JSON-LD 格式编码的小型表格示例。富媒体搜索结果测试中存在一些已知错误。
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>使用 Search Console 监控富媒体搜索结果
Search Console 是一款工具,可帮助您监控网页在 Google 搜索结果中的显示效果。即使没有注册 Search Console,您的网页也可能会显示在 Google 搜索结果中,但注册 Search Console 能够帮助您了解 Google 如何查看您的网站并做出相应的改进。建议您在以下情况下查看 Search Console:
首次部署结构化数据后
等 Google 将网页编入索引后,请在相关的富媒体搜索结果状态报告中查看是否存在问题。 理想情况下,有效项目数量会增加,而无效项目数量不会增加。如果您发现结构化数据存在问题,请执行以下操作:
发布新模板或更新代码后
如果对网站进行重大更改,请监控结构化数据无效项目的增幅。- 如果您发现无效项目增多了,可能是因为您推出的某个新模板无法正常工作,或者您的网站以一种新的错误方式与现有模板交互。
- 如果您发现有效项目减少了(但无效项目的增加情况并不对应),可能是因为您的网页中未再嵌入结构化数据。请通过网址检查工具了解导致此问题的原因。
定期分析流量时
请使用效果报告分析您的 Google 搜索流量。数据将显示您的网页在 Google 搜索结果中显示为富媒体搜索结果的频率、用户点击该网页的频率以及网页在搜索结果中的平均排名。您还可以使用 Search Console API 自动提取这些结果。问题排查
如果您在实施或调试结构化数据时遇到问题,请查看下面列出的一些实用资源。
- 如果您使用了内容管理系统 (CMS) 或其他人负责管理您的网站,请向其寻求帮助。请务必向其转发列明问题细节的任何 Search Console 消息。
- Google 不能保证使用结构化数据的功能一定会显示在搜索结果中。如需查看导致 Google 无法将您的内容显示为富媒体搜索结果的各种常见原因,请参阅结构化数据常规指南。
- 您的结构化数据可能存在错误。请参阅结构化数据错误列表。
- 如果您的网页受到结构化数据手动操作的影响,其中的结构化数据将会被忽略(但该网页仍可能会出现在 Google 搜索结果中)。如需修正结构化数据问题,请使用“人工处置措施”报告。
- 再次查看相关指南,确认您的内容是否未遵循指南。问题可能是因为出现垃圾内容或使用垃圾标记导致的。不过,问题可能不是语法问题,因此富媒体搜索结果测试无法识别这些问题。
- 针对富媒体搜索结果缺失/富媒体搜索结果总数下降进行问题排查。
- 请等待一段时间,以便 Google 重新抓取您的网页并重新将其编入索引。请注意,网页发布后,Google 可能需要几天时间才会找到和抓取该网页。有关抓取和索引编制的常见问题,请参阅 Google 搜索抓取和索引编制常见问题解答。
- 在 Google 搜索中心论坛中发帖提问。
特定数据集未显示在数据集搜索结果中
error 导致问题的原因:您的网站在描述数据集的网页中没有结构化数据,或相应网页尚未被抓取。
done 解决问题
- 复制您希望在数据集搜索结果中看到的网页对应的链接,然后将该链接复制到富媒体搜索结果测试中。如果系统显示“网页无法显示此测试已知的富媒体搜索结果”或“部分标记无法显示富媒体搜索结果”消息,则表示该网页上没有数据集标记,或者该标记不正确。您可以参阅如何添加结构化数据部分,了解如何解决此问题。
- 如果网页上存在标记,该网页可能尚未被抓取。您可以使用 Search Console 检查抓取状态。
公司徽标缺失或徽标搜索结果显示不正确
error 导致问题的原因:您的网页可能缺少组织徽标的 schema.org 标记,或者您没有在 Google 上建立商家详情。
done 解决问题
- 为您的网页添加徽标结构化数据。
- 在 Google 上建立商家详情。