Datos estructurados de conjuntos de datos (Dataset, DataCatalog y DataDownload)
Los conjuntos de datos son más fáciles de encontrar en la herramienta Búsqueda de conjuntos de datos cuando proporcionas información de apoyo (por ejemplo, su nombre, descripción, creador y formatos de distribución) como datos estructurados. El enfoque de Google con respecto al descubrimiento de conjuntos de datos es emplear schema.org y otros estándares de metadatos que se pueden añadir a las páginas que describen conjuntos de datos. El propósito de estas etiquetas es mejorar el descubrimiento de conjuntos de datos de campos como las ciencias biológicas, las ciencias sociales, el aprendizaje automático, los datos de la comunidad y gubernamentales, etc.
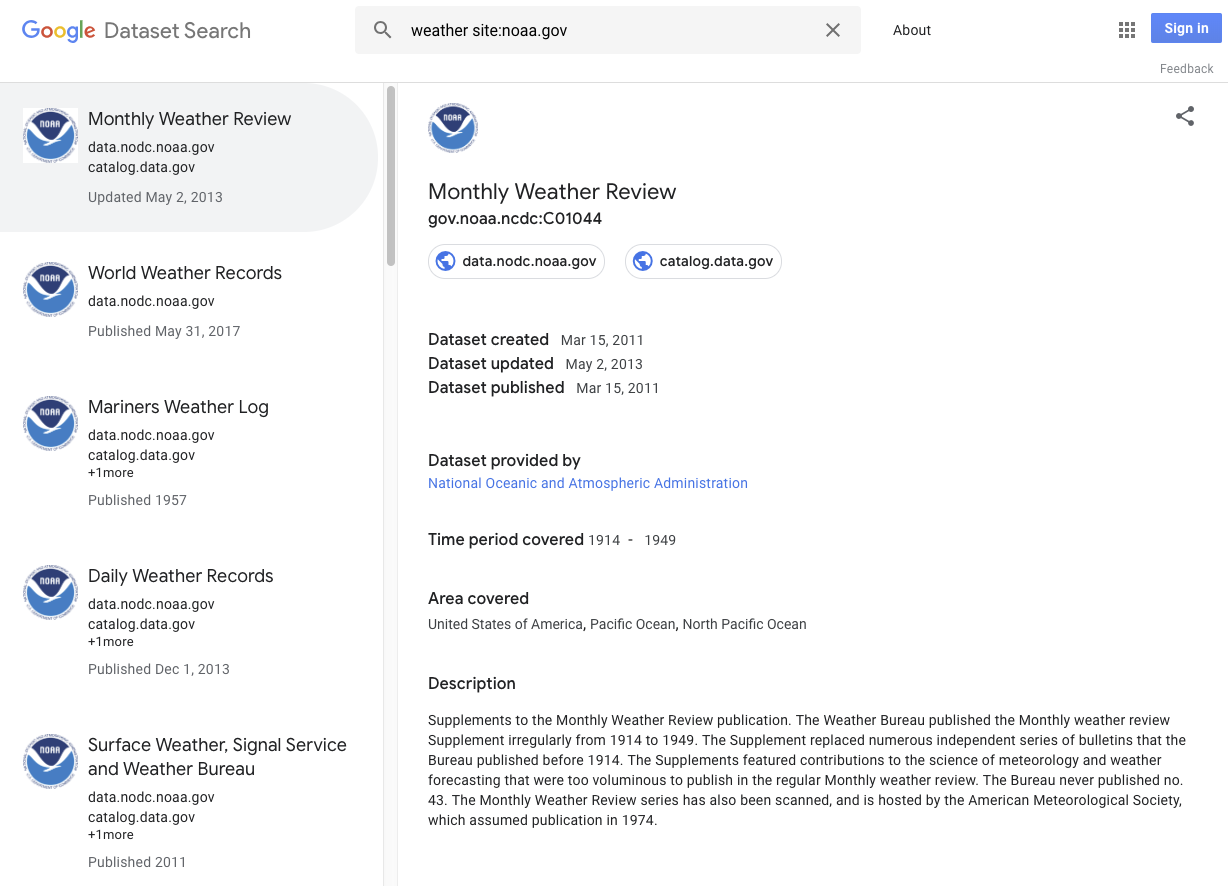
A continuación se muestran algunos ejemplos que pueden considerarse conjuntos de datos:
- Una tabla o un archivo CSV con algunos datos
- Una colección organizada de tablas
- Un archivo en un formato de propiedad que contiene datos
- Una colección de archivos que, juntos, constituyen un conjunto de datos representativo
- Un objeto estructurado con datos en algún otro formato que quizá te interese cargar en una herramienta especial para procesarlo
- Imágenes que capturan datos
- Archivos relacionados con el aprendizaje automático, como parámetros entrenados o definiciones de estructura de red neuronal
Cómo añadir datos estructurados
Los datos estructurados son un formato estandarizado con el que se puede proporcionar información sobre una página y clasificar su contenido. Consulta cómo funcionan los datos estructurados si aún no te has familiarizado con ellos.
A continuación se explica a grandes rasgos cómo crear, probar y publicar datos estructurados.
- Añade las propiedades obligatorias. Consulta más información sobre dónde insertar datos estructurados en una página en función del formato que estés utilizando.
- Sigue las directrices.
- Valida tu código con la prueba de resultados enriquecidos y corrige los errores críticos. Te recomendamos que también corrijas los problemas no críticos que puedan marcarse en la herramienta, ya que pueden ayudar a mejorar la calidad de los datos estructurados (sin embargo, esto no es necesario para que se muestren los resultados enriquecidos).
- Crea varias páginas que incluyan tus datos estructurados y comprueba cómo las ve Google con la herramienta de inspección de URLs. Asegúrate de que Google pueda acceder a tu página y de que no esté bloqueada por un archivo robots.txt, por la etiqueta
noindexni por requisitos de inicio de sesión. Si la página se ve bien, puedes solicitar que Google vuelva a rastrear tus URLs. - Para que Google siempre tenga la versión actualizada de tus páginas, te recomendamos que envíes un sitemap. Puedes automatizar este envío con la API Sitemap de Search Console.
Eliminar un conjunto de datos de los resultados de Búsqueda de Datasets
Si no quieres que se muestre un conjunto de datos en los resultados de Búsqueda de Datasets, puedes controlar cómo se indexa el conjunto de datos mediante la etiqueta meta robots. Ten en cuenta que es posible que los cambios tarden algún tiempo (días o semanas, en función de la programación de rastreo) en reflejarse en los resultados de Búsqueda de Datasets.
Nuestro enfoque con respecto al descubrimiento de conjuntos de datos
Podemos interpretar los datos estructurados que haya en páginas web sobre conjuntos de datos si están marcados con etiquetas Dataset de schema.org o estructuras equivalentes representadas en el formato Data Catalog Vocabulary (DCAT) de W3C. También estamos experimentando con una compatibilidad con datos estructurados basados en W3C CSVW, y esperamos avanzar e ir adaptando nuestro enfoque a medida que surjan prácticas recomendadas para describir conjuntos de datos. Consulta más información sobre cómo hacemos que descubrir conjuntos de datos sea más fácil.
Ejemplos
A continuación se muestra un ejemplo de conjuntos de datos que usan JSON-LD y la sintaxis de schema.org (opción recomendada) en la prueba de resultados enriquecidos. El mismo vocabulario de schema.org se puede usar en las sintaxis de RDFa 1.1 o de microdatos. También puedes describir los metadatos con el vocabulario W3C DCAT. El siguiente ejemplo se basa en una descripción de un conjunto de datos real.
A continuación se muestra un ejemplo de un conjunto de datos en JSON-LD:
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>A continuación se muestra un ejemplo de un conjunto de datos en RDFa que utiliza el vocabulario de DCAT (no admitido en la prueba de resultados enriquecidos):
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>Directrices
Los sitios deben seguir las directrices de datos estructurados, y además recomendamos las siguientes prácticas recomendadas de sitemaps y sobre fuentes y procedencias.
Prácticas recomendadas de sitemaps
Usa un archivo de sitemap para ayudar a Google a encontrar tus URLs. Si usas archivos de sitemap y las etiquetas sameAs, te será más fácil documentar cómo se publican las descripciones del conjunto de datos en todo tu sitio.
Si tienes un repositorio de conjuntos de datos, es probable que tengas al menos dos tipos de páginas: páginas canónicas ("de destino") de cada conjunto de datos, y páginas que enumeran múltiples conjuntos de datos (por ejemplo, resultados de búsqueda o algún subconjunto de conjuntos de datos). Te recomendamos que añadas datos estructurados sobre un conjunto de datos a las páginas canónicas. Usa la propiedad sameAs para incluir enlaces a la página canónica si añades datos estructurados a varias copias del conjunto de datos, como fichas en las páginas de resultados de búsqueda.
Prácticas recomendadas sobre fuentes y procedencias
Es habitual que los conjuntos de datos abiertos se vuelvan a publicar, se acumulen y se basen en otros conjuntos de datos. Este es un esquema inicial de nuestro enfoque para representar situaciones en las que un conjunto de datos es una copia de otro conjunto de datos o se basa en él.
- Usa la propiedad
sameAspara indicar las URLs más canónicas del original en los casos en que el conjunto de datos o la descripción sea solamente una nueva publicación de materiales ya publicados en otro lugar. El valor desameAsdebe indicar de forma inequívoca la identidad del conjunto de datos; es decir, dos conjuntos de datos distintos no pueden tener el mismo valorsameAs. - Usa la propiedad
isBasedOnen los casos en que el conjunto de datos que se ha vuelto a publicar (incluidos sus metadatos) haya cambiado significativamente. - Cuando un conjunto de datos deriva de varios originales o los acumula, usa la propiedad
isBasedOn. - Con la propiedad
identifier, puedes adjuntar cualquier identificador de objeto digital (DOI) o identificador compacto. Si el conjunto de datos tiene más de un identificador, repite la propiedadidentifier. Si usas JSON-LD, esto se representa mediante la sintaxis de lista JSON.
Esperamos mejorar nuestras recomendaciones a partir de los comentarios, en particular en torno a la descripción de procedencia, el control de versiones y las fechas asociadas con la publicación de series temporales. Únete a las conversaciones de la comunidad.
Recomendaciones de propiedad textual
Recomendamos limitar todas las propiedades textuales a un máximo de 5000 caracteres. Google Búsqueda de Datasets solo usa los primeros 5000 caracteres de las propiedades textuales. Los nombres y títulos suelen ser unas pocas palabras o una oración corta.
Advertencias y errores conocidos
Es posible que veas errores o advertencias en la prueba de resultados enriquecidos de Google y en otros sistemas de validación. Concretamente, los sistemas de validación pueden sugerir que las organizaciones deben tener información de contacto, incluido un tipo de contactType. Entre valores útiles se incluyen customer service, emergency, journalist, newsroom y public engagement.
También puedes ignorar los errores que indican que csvw:Table es un valor inesperado en la propiedad mainEntity.
Definiciones de tipos de datos estructurados
Debes incluir las propiedades obligatorias para que tu contenido pueda mostrarse como un resultado enriquecido. Si quieres, puedes especificar también las propiedades recomendadas para proporcionar más información sobre tu contenido y, así, ofrecer una mejor experiencia a los usuarios.
Con la prueba de resultados enriquecidos, puedes validar tus etiquetas.
El objetivo es describir información sobre un conjunto de datos (sus metadatos) y representar su contenido. Por ejemplo, los metadatos del conjunto de datos indican de qué se trata el conjunto de datos, qué variables mide, quién lo ha creado, etc., y no contiene, por poner un caso, valores específicos de las variables.
Dataset
Puedes consultar la definición completa de Dataset en schema.org/Dataset.
Puedes describir información adicional sobre la publicación del conjunto de datos, como la licencia, cuándo se publicó, su DOI o un valor sameAs que dirige a una versión canónica del conjunto de datos en un repositorio diferente. Añade identifier, license y sameAs a los conjuntos de datos que proporcionan información de procedencia y licencia.
Las propiedades que admite Google son las siguientes:
| Propiedades obligatorias | |
|---|---|
description
|
Text
Es un resumen breve que describe un conjunto de datos. Directrices
|
name
|
Text
Es el nombre descriptivo de un conjunto de datos; por ejemplo, "Acumulación de nieve en el hemisferio norte". Directrices
Recomendado: tener dos conjuntos de datos diferentes con los nombres No recomendado: tener dos conjuntos de datos diferentes con los nombres |
| Propiedades recomendadas | |
|---|---|
alternateName
|
Text
Son nombres alternativos que se han utilizado para hacer referencia a este conjunto de datos, como alias o abreviaturas. Ejemplo (en formato JSON-LD): "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person o Organization
Es el creador o autor de este conjunto de datos. Para identificar de forma exclusiva a las personas, usa ORCID ID como el valor de la propiedad "creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text o CreativeWork
Identifica los artículos académicos recomendados por el proveedor de datos que se citan además del conjunto de datos en sí. Proporciona la cita del conjunto de datos con otras propiedades, como "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" Directrices adicionales
|
funder
|
Person o Organization
Persona u organización que proporciona ayuda financiera para este conjunto de datos. Para identificar de forma exclusiva a las personas, usa ORCID ID como el valor de la propiedad "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart o isPartOf
|
URL o
Dataset
Si el conjunto de datos es una colección de conjuntos de datos más pequeños, indica la relación con la propiedad "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL, Text o PropertyValue
Es un identificador, como un DOI, o un identificador compacto. Si el conjunto de datos tiene más de un identificador, repite la propiedad |
isAccessibleForFree
|
Boolean
Indica si se puede acceder al conjunto de datos sin tener que pagar. |
keywords
|
Text
Son palabras clave que resumen el conjunto de datos. |
license
|
URL o CreativeWorkIndica una licencia con la que se distribuye el conjunto de datos. Por ejemplo: "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } Directrices adicionales
|
measurementTechnique
|
Text o URLLa técnica, la tecnología o la metodología con las que se ha recopilado un conjunto de datos; esta propiedad puede corresponderse con las variables descritas en |
sameAs
|
URL
La URL de una página web de referencia donde se identifica de manera inequívoca al conjunto de datos. |
spatialCoverage |
Text o PlacePuedes proporcionar un único punto que describa el aspecto espacial del conjunto de datos. Incluye esta propiedad solo si el conjunto de datos tiene una dimensión espacial. Por ejemplo, un punto único donde se recopilaron todas las mediciones, o las coordenadas de un cuadro delimitador de un área. Puntos "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } Formas Usa "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } } Los puntos dentro de las propiedades Ubicaciones con nombre "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
Los datos en el conjunto de datos cubren un intervalo de tiempo específico. Incluye esta propiedad solo si el conjunto de datos tiene una dimensión temporal. Schema.org utiliza el estándar ISO 8601 para describir intervalos de tiempo y puntos de tiempo. Puedes describir las fechas de manera diferente según el intervalo del conjunto de datos. Indica intervalos abiertos con dos puntos decimales ( Fecha única "temporalCoverage" : "2008" Periodo "temporalCoverage" : "1950-01-01/2013-12-18" Periodo abierto "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text o PropertyValueIndica la variable que mide este conjunto de datos. Por ejemplo, temperatura o presión. |
version
|
Text o NumberEs el número de versión del conjunto de datos. |
url
|
URL
Indica la ubicación de una página que describe el conjunto de datos. |
DataCatalog
Puedes consultar la definición completa de DataCatalog en schema.org/DataCatalog.
Los conjuntos de datos a menudo se publican en repositorios que contienen muchos otros conjuntos de datos. El mismo conjunto de datos se puede incluir en más de uno de estos repositorios. Puedes hacer referencia directa a un catálogo de datos al que pertenece este conjunto de datos mediante las siguientes propiedades:
| Propiedades recomendadas | |
|---|---|
includedInDataCatalog
|
DataCatalog
Es el catálogo al que pertenece el conjunto de datos.
|
DataDownload
Puedes consultar la definición completa de DataDownload en schema.org/DataDownload. Además de las propiedades del conjunto de datos, añade las siguientes propiedades para los conjuntos de datos que proporcionan opciones de descarga.
La propiedad distribution describe cómo obtener el conjunto de datos en sí porque la URL a menudo apunta a la página de destino que describe el conjunto de datos. La propiedad distribution describe dónde obtener los datos y en qué formato. Esta propiedad puede tener varios valores; por ejemplo, una versión CSV tiene una URL y una versión de Excel está disponible en otra.
| Propiedades obligatorias | |
|---|---|
distribution.contentUrl
|
URL
Indica el enlace para realizar la descarga. |
| Propiedades recomendadas | |
|---|---|
distribution
|
DataDownload
Es la descripción de la ubicación donde descargar el conjunto de datos y el formato de archivo en el que se descarga.
|
distribution.encodingFormat
|
Text o URLIndica el formato de archivo de la distribución.
|
Conjuntos de datos tabulares
Un conjunto de datos tabular es un conjunto organizado principalmente a partir de una cuadrícula de filas y columnas. En el caso de las páginas que incorporan conjuntos de datos tabulares, también puedes crear etiquetas más explícitas a partir del enfoque básico. Actualmente comprendemos una variación de CSVW ("CSV en la Web", consulta W3C), que se proporciona en paralelo al contenido tabular orientado al usuario en la página HTML.
A continuación se proporciona un ejemplo que muestra una pequeña tabla codificada en formato CSVW JSON-LD. Hay algunos errores conocidos en la prueba de resultados enriquecidos.
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>Monitorizar resultados enriquecidos con Search Console
Search Console es una herramienta que te ayuda a monitorizar el rendimiento de tus páginas en la Búsqueda de Google. No hace falta que te registres en Search Console para que tu sitio web aparezca en los resultados de la Búsqueda de Google, pero, si lo haces, sabrás cómo lo ve Google y qué puedes hacer para mejorarlo. Te recomendamos que consultes Search Console en los siguientes casos:
- Después de implementar datos estructurados por primera vez
- Después de publicar plantillas nuevas o modificar el código
- Al hacer el análisis periódico del tráfico
Después de implementar datos estructurados por primera vez
Una vez que Google haya indexado tus páginas, puedes comprobar si hay algún problema en el informe de estado de resultados enriquecidos correspondiente. Lo ideal es que haya un aumento en el número de elementos válidos y que no lo haya en el número de elementos no válidos. Si detectas problemas en tus datos estructurados, haz lo siguiente:
- Corrige los elementos no válidos.
- Inspecciona la URL en tiempo real para ver si el problema continúa.
- Solicita que se valide la corrección desde el informe de estado.
Después de publicar plantillas nuevas o modificar el código
Cuando hagas cambios significativos en tu sitio web, observa si se incrementa la cantidad de elementos no válidos de datos estructurados.- Si notas que hay más elementos no válidos, quizá sea porque has implementado una plantilla que no funciona, o puede que tu sitio esté interactuando con la plantilla que utilizas de un modo diferente que no es adecuado.
- Si notas que hay menos elementos válidos, pero no hay un incremento de elementos no válidos, es posible que hayas dejado de insertar datos estructurados en tus páginas. Para saber cuál es la causa del problema, utiliza la herramienta de inspección de URLs.
Al hacer el análisis periódico del tráfico
Consulta el informe de rendimiento para analizar el tráfico de tus páginas en la Búsqueda de Google. En él, verás con qué frecuencia aparece tu página como resultado enriquecido en la Búsqueda, cada cuánto hacen clic en ella los usuarios y cuál es la posición media que ocupa tu sitio web en los resultados de búsqueda. También puedes obtener automáticamente estos resultados con la API de Search Console.Solucionar problemas
Si tienes problemas para implementar o depurar datos estructurados, a continuación se incluyen algunos recursos que pueden serte útiles.
- Si usas un sistema de gestión de contenido (CMS) o alguien se encarga de gestionar tu sitio, pídele ayuda. No olvides reenviarle cualquier mensaje de Search Console que incluya información sobre el problema en cuestión.
- Google no garantiza que las funciones que utilizan datos estructurados aparezcan en los resultados de búsqueda. Para ver una lista con motivos habituales por los que Google no muestra tu contenido en resultados enriquecidos, consulta las directrices generales de datos estructurados.
- Es posible que haya un error en tus datos estructurados. Consulta la lista de errores de datos estructurados y el informe de datos estructurados que no se pueden analizar.
- Si se ha aplicado una acción manual de datos estructurados a tu página, se ignorarán sus datos estructurados, aunque la página puede seguir apareciendo en los resultados de la Búsqueda de Google. Para solucionar problemas de datos estructurados, usa el informe "Acciones manuales".
- Revisa las directrices para comprobar si tu contenido no las cumple. El problema podría deberse a que la página incluye contenido engañoso o etiquetas con contenido fraudulento. No obstante, es posible que el problema no se deba a la sintaxis, por lo que la prueba de resultados enriquecidos no podrá ayudarte a identificarlo.
- Solucionar problemas si faltan resultados enriquecidos o si se ha reducido el número total de resultados enriquecidos.
- Da cierto margen a Google para que vuelva a rastrear e indexar tu página. Recuerda que Google puede tardar varios días en encontrar y rastrear una página después de publicarse. Consulta las preguntas frecuentes sobre el rastreo y la indexación de la Búsqueda de Google.
- Publica una pregunta en el foro del Centro de la Búsqueda de Google.
Un conjunto de datos concreto no aparece en los resultados de Búsqueda de Datasets
error Causa del problema: tu sitio web no contiene datos estructurados en los que se describan los conjuntos de datos o la página aún no se ha rastreado.
done Corrige el problema
- Copia el enlace de la página que esperas que aparezca en los resultados de Búsqueda de Datasets y pégalo en la prueba de resultados enriquecidos. Si aparece un mensaje que indica que la página no es apta para este tipo de resultados o que no todas las etiquetas son aptas para generar resultados enriquecidos, significa que no hay etiquetas de conjunto de datos en la página o que no son correctas. Para solucionar el problema, consulta la sección Cómo añadir datos estructurados.
- Si la página tiene etiquetas, es posible que no se haya rastreado todavía. Puedes comprobar el estado del rastreo con Search Console.
Falta el logotipo de la empresa o no aparece correctamente en los resultados
error Causa del problema: quizá tu página no incluye las etiquetas de schema.org para logotipos de organizaciones o no has dado información sobre tu empresa a Google.
done Corrige el problema
- Añade datos estructurados de logotipo en tu página.
- Proporciona información sobre tu empresa a Google.