'जगहों के बारे में अहम जानकारी' सुविधा, कई कैटगरी की जगहों के लिए ब्रैंड की जानकारी देती है. उदाहरण के लिए:
- "एटीएम, बैंक, और क्रेडिट यूनियन" कैटगरी के लिए, ब्रैंड के डेटा में PNC, UBS, और Chase बैंकों के हर ब्रैंड के लिए एक एंट्री मौजूद है.
- "ऑटोमोटिव रेंटल" कैटगरी के लिए, डेटा में Budget, Hertz, और Thrifty, हर ब्रैंड के लिए एक एंट्री शामिल है.
ब्रैंड के डेटासेट के लिए क्वेरी करने का एक सामान्य इस्तेमाल यह है कि इसे जगह की जानकारी के डेटा पर की गई क्वेरी के साथ जोड़ा जाए. इससे इस तरह के सवालों के जवाब दिए जा सकते हैं:
- किसी इलाके में, ब्रैंड के हिसाब से सभी स्टोर की संख्या कितनी है?
- मेरे इलाके में, मेरे तीन प्रतिस्पर्धी ब्रैंड की संख्या कितनी है?
- इस इलाके में "फ़िटनेस" या "पेट्रोल पंप" जैसी किसी खास कैटगरी के कितने ब्रैंड मौजूद हैं?
ब्रैंड के डेटासेट के बारे में जानकारी
अमेरिका के लिए ब्रैंड के डेटासेट का नाम places_insights___us.brands है.
ब्रैंड के डेटासेट का स्कीमा
ब्रैंड के डेटासेट के स्कीमा में तीन फ़ील्ड तय किए गए हैं:
id: ब्रैंड आईडी.name: ब्रैंड का नाम, जैसे कि "Hertz" या "Chase".category: ब्रैंड का टाइप, जैसे कि "पेट्रोल पंप", "खाना और पेय पदार्थ" या "आवास". संभावित वैल्यू की सूची के लिए, कैटेगरी की वैल्यू देखें.
क्वेरी में ब्रैंड के डेटासेट का इस्तेमाल करना
जगहों के डेटासेट स्कीमा, brand_ids फ़ील्ड के बारे में बताता है. अगर जगहों के डेटासेट में मौजूद कोई जगह किसी ब्रैंड से जुड़ी है, तो उस जगह के लिए brand_ids फ़ील्ड में, ब्रैंड का आईडी मौजूद होता है.
ब्रैंड के डेटासेट का रेफ़रंस देने वाली सामान्य क्वेरी, brand_ids फ़ील्ड के आधार पर जगहों के डेटासेट के साथ JOIN करती है.
उदाहरण के लिए, न्यूयॉर्क शहर में एम्पायर स्टेट बिल्डिंग से 2,000 मीटर के दायरे में मौजूद McDonald's रेस्टोरेंट की संख्या जानने के लिए:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) FROM PROJECT_NAME.places_insights___us.places places, UNNEST(brand_ids) AS brand_id LEFT JOIN PROJECT_NAME.places_insights___us.brands ON brand_id = brands.id WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 2000) AND brands.name = "McDonald's" AND business_status = "OPERATIONAL"
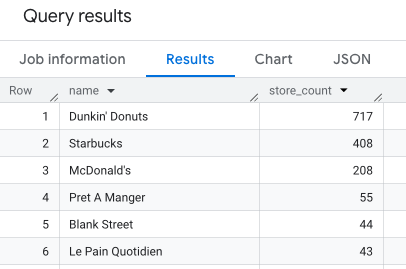
नीचे दी गई क्वेरी से, न्यूयॉर्क शहर में मौजूद उन बैंकों की संख्या मिलती है जो किसी ब्रैंड के हैं. इन्हें ब्रैंड के नाम के हिसाब से ग्रुप किया गया है:
SELECT WITH AGGREGATION_THRESHOLD brands.name, COUNT(*) AS store_count FROM PROJECT_NAME.places_insights___us.places places, UNNEST(brand_ids) AS brand_id LEFT JOIN PROJECT_NAME.places_insights___us.brands ON brand_id = brands.id WHERE brands.category = "ATMs, Banks and Credit Unions" AND "bank" IN UNNEST(places.types) AND business_status = "OPERATIONAL" GROUP BY brands.name ORDER BY store_count DESC;
इस इमेज में, ब्रैंड के हिसाब से संख्याएं दिखाई गई हैं:
कैटगरी की वैल्यू
किसी ब्रैंड के लिए category फ़ील्ड में ये वैल्यू हो सकती हैं:
| कैटगरी टाइप की वैल्यू |
|---|
ATMs, Banks and Credit Unions |
Automotive and Parts Dealers |
Automotive Rentals |
Automotive Services |
Dental |
Electric Vehicle Charging Stations |
Electronics Retailers |
Fitness |
Food and Drink |
Gas Station |
Grocery and Liquor |
Health and Personal Care Retailers |
Hospital |
Lodging |
Merchandise Retail |
Movie Theater |
Parking |
Telecommunications |