
概览
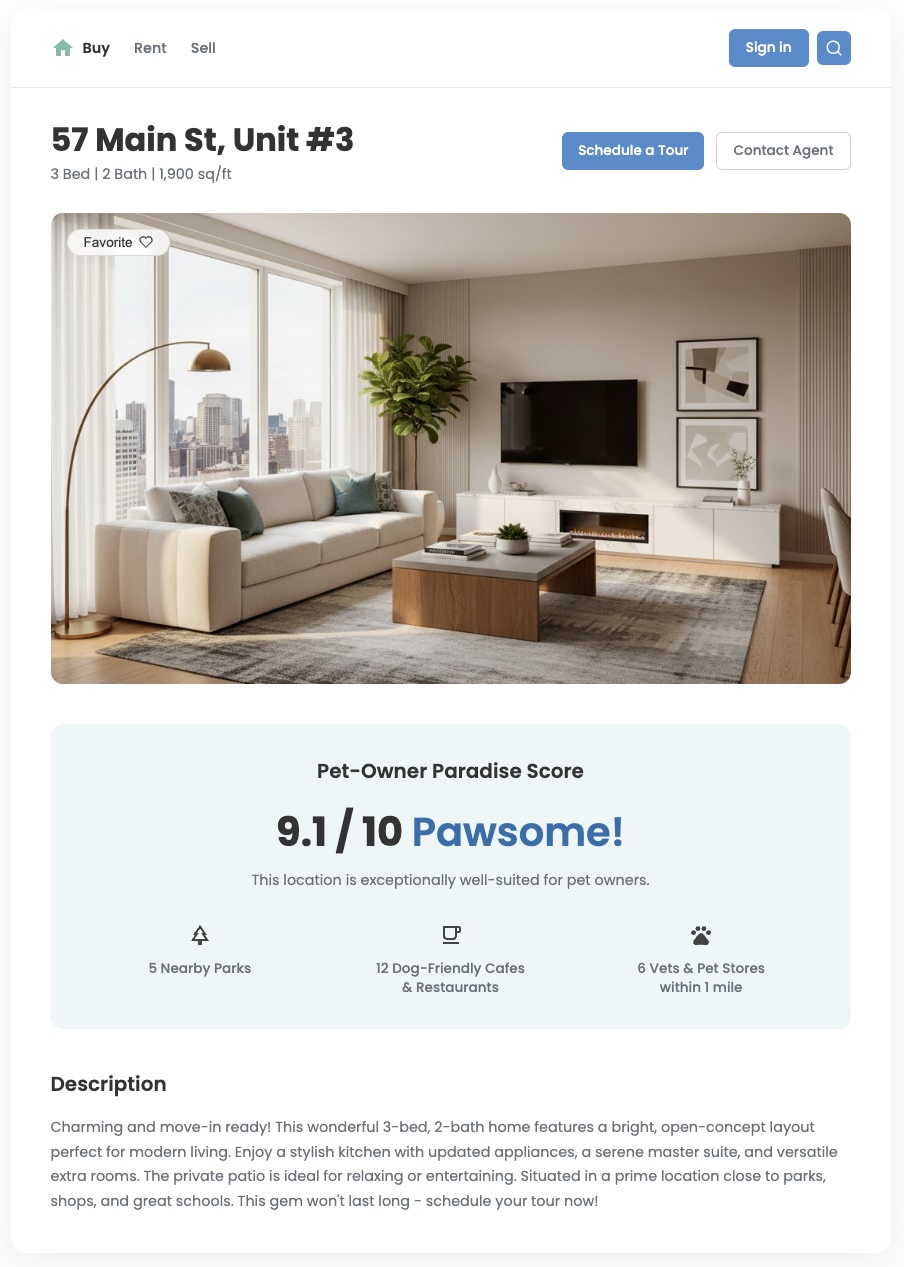
标准位置数据可以告诉您附近有哪些内容,但通常无法 回答更重要的问题:“这个区域对我来说怎么样?”用户的需求各不相同。与养狗的年轻专业人士相比,有年幼子女的家庭有不同的优先事项。为了帮助他们做出自信的决定,您需要提供反映这些特定需求的数据分析。自定义位置得分是一个强大的工具,可提供此价值并打造显著差异化的用户体验。
本文介绍了如何使用 BigQuery 中的 地点数据分析 数据集创建自定义的多方面位置得分。通过将 POI 数据转换为有意义的指标,您可以丰富房地产、零售或旅游应用,并为用户提供他们所需的相关信息。我们还提供了一个选项,让您可以在 BigQuery 中使用生成式 AI ,这是一种计算位置得分的强大方式。
通过定制得分提升业务价值
以下示例说明了如何将原始位置数据转换为以用户为中心的强大指标,以增强您的应用。
- 房地产开发商可以创建“家庭友好度得分”或“通勤者理想得分”,帮助买家和租客选择与他们的生活方式相匹配的完美社区,从而提高用户互动度、提高潜在客户质量并加快转化速度。
- 旅游和酒店工程师可以构建“夜生活得分”或“观光者天堂得分”,帮助旅客选择符合其度假风格的酒店,从而提高预订率和客户满意度
- 零售分析师可以生成“健身与健康得分”,根据附近的互补业务确定新健身房或健康食品店的最佳位置,从而最大限度地提高定位合适用户群体的潜力。
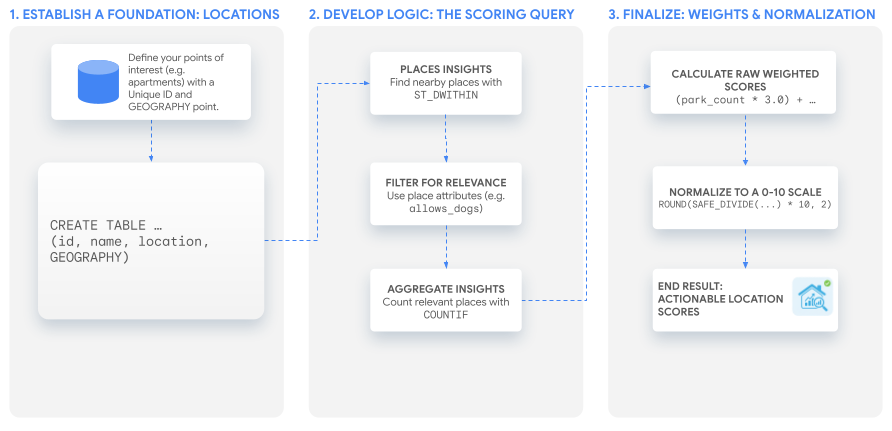
在本指南中,您将学习一种灵活的三部分方法,用于直接在 BigQuery 中使用 Places 数据构建任何类型的自定义位置得分。我们将通过构建两个不同的示例得分来说明此模式:家庭友好度得分 和宠物主人天堂得分 。这种方法让您能够超越地点数量,并利用地点数据分析数据集中丰富而详细的属性。您可以使用营业时间、地点是否适合儿童或是否允许携带狗狗等信息,为用户创建复杂且有意义的指标。
解决方案工作流
本教程使用单个强大的 SQL 查询来构建自定义得分,您可以将其应用于任何用例。我们将通过为一组假设的公寓房源构建两个示例得分来介绍此过程。
如需在互动环境中探索此工作流,请运行以下笔记本。它演示了如何在
BigQuery 中使用
AI.GENERATE 函数创建位置得分。
 在 GitHub 上查看源代码
在 GitHub 上查看源代码
前提条件
在开始之前,请按照以下说明 设置 Places Insights。
1. 打好基础:您感兴趣的位置
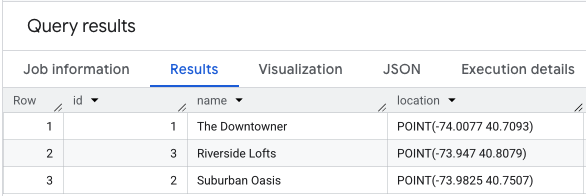
在创建得分之前,您需要一份要分析的位置列表。第一步是确保此数据以表的形式存在于 BigQuery 中。
关键是为每个位置提供一个唯一标识符,以及一个存储其坐标的 GEOGRAPHY 列。
您可以使用如下查询来创建和填充要评分的位置表:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
对位置数据执行 SELECT * 的结果将类似于以下内容。
2. 开发核心逻辑:评分查询
确定位置后,下一步是查找、过滤和统计与自定义得分相关的附近地点。所有这些操作都在单个 SELECT 语句中完成。
使用地理空间搜索查找附近地点
首先,您需要从地点数据分析数据集中找到距离每个位置一定距离内的所有地点。BigQuery 函数 ST_DWITHIN 非常适合此操作。我们将对 apartment_listings 表和 places_insights 表执行 JOIN,以查找半径 800 米内的所有地点。LEFT JOIN 可确保所有原始位置都包含在结果中,即使附近没有找到匹配的地点也是如此。
使用高级属性过滤相关性
在此步骤中,您将得分的抽象概念转换为具体的数据过滤条件。对于我们的两个示例得分,条件有所不同:
- 对于“家庭友好度得分” ,我们关注的是公园、博物馆和明确适合儿童的餐厅。
- 对于“宠物主人天堂得分” ,我们关注的是公园、兽医诊所、宠物店以及任何允许携带狗狗的餐厅或咖啡馆。
您可以直接在查询的 WHERE 子句中过滤这些特定属性。
汇总每个位置的数据分析
最后,您需要统计为每间公寓找到的相关地点数量。GROUP BY 子句会汇总结果,而 COUNTIF 函数会统计符合我们每个得分的特定条件的地点。
以下查询将这三个步骤结合在一起,一次性计算出两个得分的原始计数:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
此查询的结果将类似于以下内容。
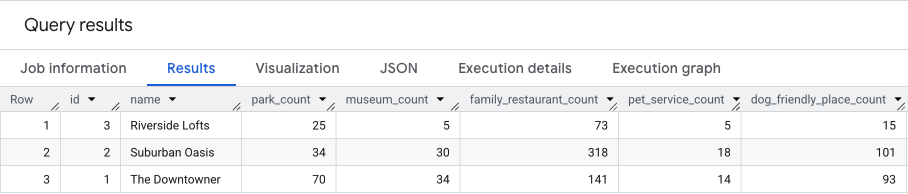
我们将在下一部分中基于这些结果进行构建。
3. 创建得分
现在,您已经获得了每个位置的地点数量以及每种地点类型的权重,可以生成自定义位置得分了。在本部分中,我们将讨论两个 选项:在 BigQuery 中使用您自己的自定义计算,或在 BigQuery 中使用生成式人工智能 (AI) 函数。
选项 1:在 BigQuery 中使用您自己的自定义计算
上一步的原始计数很有参考价值,但我们的目标是获得一个易于使用的得分。最后一步是使用权重组合这些计数,然后将结果归一化为 0-10 的范围。
应用自定义权重 选择权重既是一门艺术,也是一门科学。 它们需要反映您的业务优先级或您认为对用户最重要的内容。对于“家庭友好度”得分,您可能会认为公园的重要性是博物馆的两倍。首先做出最佳假设,然后根据用户反馈进行迭代。
归一化得分 以下查询使用了两个通用表表达式 (CTE):第一个表达式计算原始计数(与之前一样),第二个表达式计算加权得分。然后,最终的 SELECT 语句对加权得分执行最小-最大归一化。输出示例 apartment_listings 表的 location 列,以便在地图上实现数据可视化。
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
查询结果将类似于以下内容。最后两列是归一化得分。

了解归一化得分
了解为什么这个最终归一化步骤如此有价值非常重要。
原始加权得分的范围可能从 0 到一个潜在的非常大的数字,具体取决于您所在位置的城市密度。对于用户来说,没有上下文的 500 分毫无意义。
归一化会将这些抽象数字转换为相对排名。通过将结果缩放为 0 到 10,得分可以清楚地传达每个位置在特定数据集中的比较情况:
- 得分 10 分配给原始得分最高的位置,将其标记为当前集合中的最佳选项。
- 得分 0 分配给原始得分最低的位置,使其成为比较的基准。这并不意味着该位置没有任何便利设施,而是相对于正在评估的其他选项而言,它是最不合适的。
- 所有其他得分 都按比例介于两者之间,让用户能够一目了然地比较他们的选项,清晰直观。
选项 2:使用 AI.GENERATE 函数 (Gemini)
除了使用固定的数学公式外,您还可以使用
BigQuery AI.GENERATE
函数
直接在 SQL 工作流中计算自定义位置得分。
虽然选项 1 非常适合基于便利设施数量进行纯定量评分,但它无法轻松考虑定性数据。借助 AI.GENERATE 函数,您可以将地点数据分析查询中的数字与非结构化数据相结合,例如公寓房源的文本说明(例如“此位置适合家庭,夜间安静”)或特定用户个人资料偏好(例如“此用户为家庭预订,偏好位于市中心的安静区域”)。这样,您就可以生成更细致的得分,检测到严格计数可能会遗漏的细微之处,例如某个位置的便利设施密度很高,但也被描述为“对儿童来说太吵闹”。
构建提示
如需使用此函数,需要将汇总结果(来自第 2 步)格式化为自然语言提示。这可以通过将数据列与模型的说明连接起来,在 SQL 中动态完成。
在以下查询中,insight_counts 与公寓的文本说明相结合,为每一行创建一个提示。此外,还定义了目标用户个人资料,以指导评分。
使用 SQL 生成得分
以下查询在 BigQuery 中执行整个操作。它:
- 汇总 地点数量(如第 2 步中所述)。
- 为每个位置构建 提示。
- 调用
AI.GENERATE函数,使用 Gemini 模型分析提示。 - 将结果解析 为结构化格式,以便在应用中使用。
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
了解配置
- 了解费用: 此函数会将您的输入传递给 Gemini 模型,并且每次调用时都会在 Vertex AI 中产生费用。如果要分析大量位置(例如数千个公寓房源),建议先将数据集过滤为最相关的候选房源。 如需详细了解如何最大限度地降低费用,请参阅最佳 实践。
endpoint:在此示例中,指定了gemini-flash-latest,以优先考虑速度和成本效益。不过,您可以选择最能满足您需求的模型。请参阅 Gemini 模型 文档,尝试使用不同的版本(例如,Gemini Pro 用于更复杂的推理任务),找到最适合您用例的版本。output_schema:系统会强制执行架构(得分使用FLOAT64,推理使用STRING),而不是解析原始文本。这样可确保输出可以直接在应用或可视化工具中使用,而无需进行后处理。
输出示例
查询会返回一个标准 BigQuery 表,其中包含自定义得分和模型的推理。
| id | name | family_friendliness_score | reasoning |
|---|---|---|---|
| 1 | The Downtowner | 5.5 | 便利设施数量出色(公园、餐厅),符合定量指标。不过,定性数据表明周末噪音过大,夜生活氛围浓厚,这与目标用户对安静的需求直接冲突。 |
| 2 | Suburban Oasis | 9.8 | 出色的定量数据与完美符合目标家庭个人资料的说明(“安静的林荫大道”)相结合。较高的正修饰符导致得分接近完美。 |
借助此过程,您可以在单个 SQL 查询中提供高度个性化的得分,让每个用户都觉得得分易于理解且量身定制。
4. 在地图上直观呈现得分
BigQuery Studio includes an integrated map
visualization
for any query result that contains a GEOGRAPHY 列。由于我们的查询会输出 location 列,因此您可以立即直观呈现得分。
点击 Visualization 标签页会显示地图,而 Data Column 下拉菜单用于控制要直观呈现的位置得分。在此示例中,我们直观呈现了
normalized_pet_score选项 1
示例。请注意,在此示例中,我们向 apartment_listings 表中添加了更多位置。
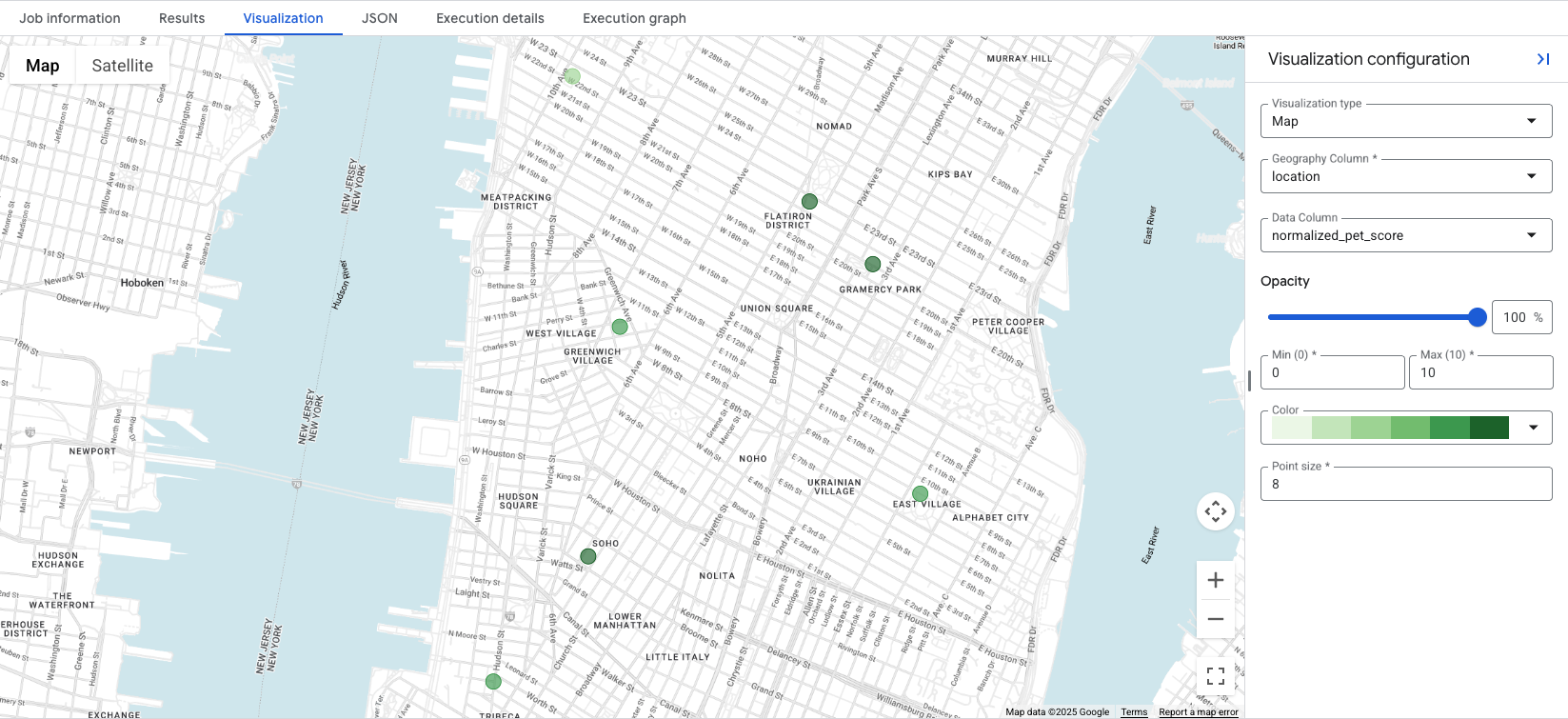
直观呈现数据后,您可以一目了然地了解最适合所创建得分的位置,其中颜色较深的绿色圆圈表示 normalized_pet_score 较高的位置(在本例中)。如需了解更多地点数据分析数据
可视化选项,请参阅直观呈现查询
结果。
总结
现在,您已经掌握了一种强大且可重复的方法来创建细致的位置得分。首先,您在 BigQuery 中构建了一个 SQL 查询,该查询使用 ST_DWITHIN 查找附近地点,使用 good_for_children 和 allows_dogs 等高级属性过滤这些地点,并使用 COUNTIF 汇总结果。通过应用自定义权重并归一化结果,您生成了一个易于使用的得分,可提供深入且可操作的数据分析。您可以直接应用此模式将原始位置数据转化为显著的竞争优势。
后续操作
现在该您亲自试试了。本教程提供了一个模板。您可以使用地点数据分析架构中提供的丰富数据来创建最符合您用例需求的得分。不妨考虑构建以下其他得分:
- “夜生活得分”: 结合使用
primary_type(bar、night_club)、price_level和深夜营业时间的过滤条件,找到天黑后最 热闹的区域。 - “健身与健康得分”: 统计附近的
gyms、parks和health_food_stores,并过滤出serves_vegetarian_food的餐厅,为注重健康的用户对位置进行评分。 - “通勤者理想得分”: 查找附近
transit_station和parking地点密度较高的位置,帮助重视 交通便利性的用户。
贡献者
Henrik Valve | DevX 工程师