Pour accéder directement aux données Places Insights, vous devez écrire des requêtes SQL dans BigQuery qui renvoient des insights agrégés sur les lieux. Les résultats sont renvoyés à partir de l'ensemble de données pour les critères de recherche spécifiés dans la requête.
Si vous avez besoin d'obtenir des décomptes inférieurs à 5, envisagez plutôt d'utiliser les fonctions de décompte des lieux. Ces fonctions peuvent renvoyer n'importe quel nombre, y compris 0, mais imposent une zone de recherche minimale de 40 mètres sur 40 mètres (1 600 m2). Découvrez quand interroger directement et quand utiliser des fonctions.
Principes de base des requêtes
L'image suivante montre le format de base d'une requête :

Chaque partie de la requête est décrite plus en détail ci-dessous.
Exigences concernant les requêtes
Les requêtes SQL effectuées directement sur l'ensemble de données doivent spécifier l'ensemble de données et inclure WITH AGGREGATION_THRESHOLD dans la clause SELECT. Sinon, la requête échouera.
Cet exemple spécifie places_insights___us.places pour interroger l'ensemble de données pour les États-Unis.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`
Spécifier un nom de projet (facultatif)
Vous pouvez éventuellement inclure le nom de votre projet dans la requête. Si vous ne spécifiez pas de nom de projet, votre requête sera exécutée par défaut dans le projet actif.
Vous pouvez inclure le nom de votre projet si vous avez associé des ensembles de données portant le même nom dans différents projets ou si vous interrogez une table en dehors du projet actif.
Par exemple : [project name].[dataset name].places.
Spécifier une fonction d'agrégation
L'exemple ci-dessous montre les fonctions d'agrégation BigQuery compatibles. Cette requête agrège les notes de tous les lieux situés dans un rayon de 1 000 mètres autour de l'Empire State Building à New York pour générer des statistiques sur les notes :
SELECT WITH AGGREGATION_THRESHOLD COUNT(id) AS place_count, APPROX_COUNT_DISTINCT(rating) as distinct_ratings, COUNTIF(rating > 4.0) as good_rating_count, LOGICAL_AND(rating <= 5) as all_ratings_equal_or_below_five, LOGICAL_OR(rating = 5) as any_rating_exactly_five, AVG(rating) as avg_rating, SUM(user_rating_count) as rating_count, COVAR_POP(rating, user_rating_count) as rating_covar_pop, COVAR_SAMP(rating, user_rating_count) as rating_covar_samp, STDDEV_POP(rating) as rating_stddev_pop, STDDEV_SAMP(rating) as rating_stddev_samp, VAR_POP(rating) as rating_var_pop, VAR_SAMP(rating) as rating_var_samp, FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL"
Spécifier une restriction en fonction de l'emplacement
Si vous ne spécifiez pas de restriction géographique, l'agrégation des données s'applique à l'ensemble des données. En règle générale, vous spécifiez une restriction géographique pour rechercher une zone spécifique. Cet exemple de requête spécifie une restriction de ciblage centrée sur l'Empire State Building à New York, avec un rayon de 1 000 mètres.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000)
Vous pouvez utiliser un polygone pour spécifier la zone de recherche. Lorsque vous utilisez un polygone, ses points doivent définir une boucle fermée, où le premier point du polygone est identique au dernier :
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_CONTAINS(ST_GEOGFROMTEXT("""POLYGON((-73.985708 40.75773,-73.993324 40.750298, -73.9857 40.7484,-73.9785 40.7575, -73.985708 40.75773))"""), point)
Dans l'exemple suivant, vous définissez la zone de recherche à l'aide d'une ligne de points connectés et définissez le rayon de recherche sur 100 mètres autour de la ligne. La ligne est semblable à un itinéraire calculé par l'API Routes. L'itinéraire peut être destiné à un véhicule, à un vélo ou à un piéton :
DECLARE route GEOGRAPHY; SET route = ST_GEOGFROMTEXT("""LINESTRING(-73.98903537033028 40.73655649223003, -73.93580216278471 40.80955538843361)"""); SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(route, point, 100)
Filtrer par champs de l'ensemble de données sur les lieux
Affinez votre recherche en fonction des champs définis par le schéma de l'ensemble de données. Filtrez les résultats en fonction des champs du jeu de données, tels que le lieu regular_opening_hours, price_level et le client rating.
Référencez tous les champs de l'ensemble de données définis par le schéma de l'ensemble de données pour le pays qui vous intéresse. Le schéma de l'ensemble de données pour chaque pays se compose de deux parties :
- Le schéma principal commun aux ensembles de données de tous les pays.
- Un schéma spécifique à un pays qui définit les composants du schéma propres à ce pays.
Par exemple, votre requête peut inclure une clause WHERE qui définit les critères de filtrage de la requête.
Dans l'exemple suivant, vous renvoyez des données d'agrégation pour les lieux de type tourist_attraction avec un business_status de OPERATIONAL, qui ont un rating supérieur ou égal à 4, 0 et avec allows_dogs défini sur true :
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND 'tourist_attraction' IN UNNEST(types) AND business_status = "OPERATIONAL" AND rating >= 4.0 AND allows_dogs = true
La requête suivante renvoie les résultats pour les lieux qui disposent d'au moins huit bornes de recharge pour véhicules électriques :
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
Filtrer par type principal de lieu et type de lieu
Chaque lieu de l'ensemble de données peut comporter :
Un seul type principal lui est associé parmi les types définis par Types de lieux. Par exemple, le type principal peut être
mexican_restaurantousteak_house. Utilisezprimary_typedans une requête pour filtrer les résultats en fonction du type principal d'un lieu.Plusieurs valeurs de type lui sont associées à partir des types définis par Types de lieux. Par exemple, un restaurant peut avoir les types suivants :
seafood_restaurant,restaurant,food,point_of_interest,establishment. Utiliseztypesdans une requête pour filtrer les résultats sur la liste des types associés au lieu.
La requête suivante renvoie les résultats pour tous les lieux dont le type principal est skin_care_clinic et qui fonctionnent également comme spa :
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE 'spa' IN UNNEST(types) AND 'skin_care_clinic' = primary_type
Filtrer par ID de lieu
L'exemple ci-dessous calcule la note moyenne de cinq lieux. Les lieux sont identifiés par leur place_id.
DECLARE place_ids ARRAY<STRING>; SET place_ids = ['ChIJPQOh8YVZwokRE2WsbZI4tOk', 'ChIJibtT3ohZwokR7tX0gp0nG8U', 'ChIJdfD8moVZwokRO6vxjXAtoWs', 'ChIJsdNONuFbwokRLM-yuifjb8k', 'ChIJp0gKoClawokR0txqrcaEkFc']; SELECT WITH AGGREGATION_THRESHOLD AVG(rating) as avg_rating, FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(place_ids) place_id WHERE id = place_id;
Filtrer certains ID de lieu
Vous pouvez également exclure un tableau d'ID de lieux d'une requête.
Vous pouvez trouver les ID de lieu que vous recherchez à l'aide de l'outil de recherche d'ID de lieu ou de manière programmatique en utilisant l'API Places pour effectuer une requête Text Search (nouvelle version).
Dans l'exemple ci-dessous, la requête trouve le nombre de cafés du code postal 2000 de Sydney, en Australie, qui n'apparaissent pas dans le tableau excluded_cafes. Une telle requête peut être utile pour un propriétaire d'entreprise qui souhaite exclure ses propres établissements d'un décompte.
WITH excluded_cafes AS ( -- List the specific place IDs to exclude from the final count SELECT * FROM UNNEST([ 'ChIJLTcYGz-uEmsRmazk9oMnP5w', 'ChIJeWDDDNOvEmsRF8SMPUwPbhw', 'ChIJKdaKHbmvEmsRSdxq_1O05bU' ]) AS place_id ) SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `places_insights___au.places` AS places -- Perform a LEFT JOIN to identify which places are in the exclusion list LEFT JOIN excluded_cafes ON places.id = excluded_cafes.place_id WHERE -- Filter for specific place type and postal code places.primary_type = 'cafe' AND '2000' IN UNNEST(places.postal_code_names) -- Keep only the rows where the join failed (meaning the ID was NOT in the list) AND excluded_cafes.place_id IS NULL;
Filtrer sur des valeurs de données prédéfinies
De nombreux champs de l'ensemble de données ont des valeurs prédéfinies. Exemple
Le champ
price_levelaccepte les valeurs prédéfinies suivantes :PRICE_LEVEL_FREEPRICE_LEVEL_INEXPENSIVEPRICE_LEVEL_MODERATEPRICE_LEVEL_EXPENSIVEPRICE_LEVEL_VERY_EXPENSIVE
Le champ
business_statusaccepte les valeurs prédéfinies suivantes :OPERATIONALCLOSED_TEMPORARILYCLOSED_PERMANENTLY
Dans cet exemple, la requête renvoie le nombre de fleuristes dont le business_status est OPERATIONAL dans un rayon de 1 000 mètres autour de l'Empire State Building à New York :
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL" AND 'florist' IN UNNEST(types)
Filtrer par horaires d'ouverture
Dans cet exemple, renvoyez le nombre de lieux dans une zone géographique proposant des happy hours le vendredi :
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(regular_opening_hours_happy_hour.friday) AS friday_hours WHERE '17:00:00' BETWEEN friday_hours.start_time AND friday_hours.end_time AND ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000);
Filtrer par région (composants d'adresse)
Notre ensemble de données sur les lieux contient également un ensemble de composants d'adresse utiles pour filtrer les résultats en fonction des limites politiques. Chaque composant d'adresse est identifié par son nom de code textuel (10002 pour le code postal à New York) ou par son ID de lieu (ChIJm5NfgIBZwokR6jLqucW0ipg) pour le code postal équivalent.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE '10002' IN UNNEST(postal_code_names) --- 'ChIJm5NfgIBZwokR6jLqucW0ipg' IN UNNEST(postal_code_ids) -- same filter as above using postal code ID
Filtrer par recharge de VE
Cet exemple fournit le nombre de lieux disposant d'au moins huit bornes de recharge pour véhicules électriques :
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
Cet exemple compte le nombre de lieux disposant d'au moins 10 bornes de recharge Tesla compatibles avec la recharge rapide :
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(ev_charge_options.connector_aggregation) as connectors WHERE connectors.type ='EV_CONNECTOR_TYPE_TESLA' AND connectors.max_charge_rate_kw >= 50 AND connectors.count >= 10
Renvoyer des groupes de résultats
Les requêtes affichées jusqu'à présent renvoient une seule ligne dans le résultat, qui contient le nombre d'agrégations pour la requête. Vous pouvez également utiliser l'opérateur GROUP BY pour renvoyer plusieurs lignes dans la réponse en fonction des critères de regroupement.
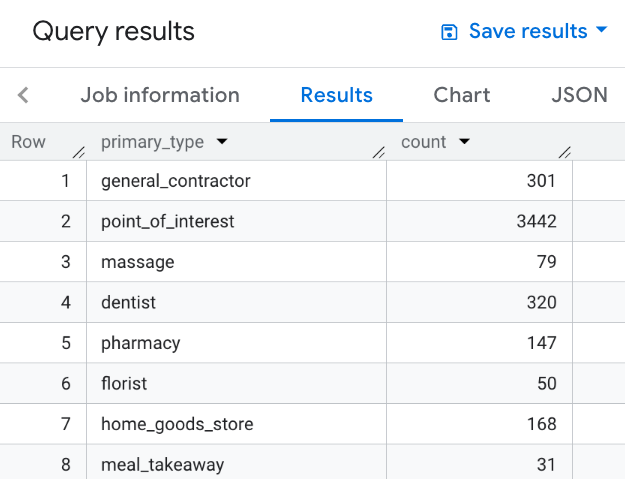
Par exemple, la requête suivante renvoie les résultats regroupés par type principal de chaque lieu dans la zone de recherche :
SELECT WITH AGGREGATION_THRESHOLD primary_type, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.99992071622756, 40.71818785986936), point, 1000) GROUP BY primary_type
Cette image montre un exemple de résultat pour cette requête :
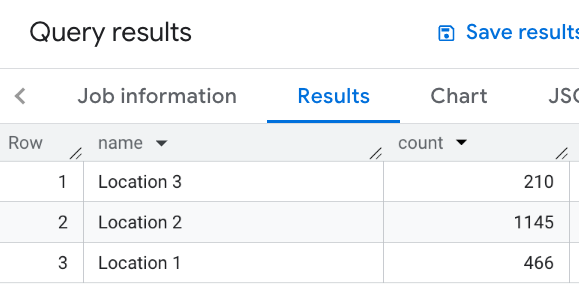
Dans cet exemple, vous définissez une table d'emplacements. Pour chaque emplacement, vous calculez ensuite le nombre de restaurants à proximité, c'est-à-dire ceux situés à moins de 1 000 mètres :
WITH my_locations AS ( SELECT 'Location 1' AS name, ST_GEOGPOINT(-74.00776440888504, 40.70932825380786) AS location UNION ALL SELECT 'Location 2' AS name, ST_GEOGPOINT(-73.98257192833559, 40.750738934863215) AS location UNION ALL SELECT 'Location 3' AS name, ST_GEOGPOINT(-73.94701794263223, 40.80792954838445) AS location ) SELECT WITH AGGREGATION_THRESHOLD l.name, COUNT(*) as count FROM `PROJECT_NAME.places_insights___us.places` JOIN my_locations l ON ST_DWITHIN(l.location, p.point, 1000) WHERE primary_type = "restaurant" AND business_status = "OPERATIONAL" GROUP BY l.name
Cette image montre un exemple de résultat pour cette requête :