Places Insights के डेटा को सीधे तौर पर ऐक्सेस करने के लिए, BigQuery में एसक्यूएल क्वेरी लिखी जाती हैं. इनसे जगहों के बारे में एग्रीगेट की गई अहम जानकारी मिलती है. क्वेरी में दी गई खोज की शर्तों के हिसाब से, डेटासेट से नतीजे दिखाए जाते हैं.
अगर आपको पांच से कम संख्या चाहिए, तो इसके बजाय जगह की संख्या गिनने वाले फ़ंक्शन का इस्तेमाल करें. ये फ़ंक्शन, 0 सहित कोई भी संख्या दिखा सकते हैं. हालांकि, ये 40.0 मीटर x 40.0 मीटर (1600 m2) के कम से कम सर्च एरिया को लागू करते हैं. इस बारे में ज़्यादा जानें कि सीधे तौर पर क्वेरी कब करनी चाहिए और फ़ंक्शन कब इस्तेमाल करने चाहिए.
क्वेरी की बुनियादी बातें
नीचे दी गई इमेज में, क्वेरी का सामान्य फ़ॉर्मैट दिखाया गया है:

क्वेरी के हर हिस्से के बारे में ज़्यादा जानकारी यहां दी गई है.
क्वेरी से जुड़ी ज़रूरी शर्तें
डेटासेट पर सीधे तौर पर की गई एसक्यूएल क्वेरी में, डेटासेट के बारे में जानकारी दी जानी चाहिए. साथ ही, SELECT क्लॉज़ में WITH AGGREGATION_THRESHOLD शामिल होना चाहिए. इसके बिना, क्वेरी पूरी नहीं होगी.
इस उदाहरण में, अमेरिका के डेटासेट के लिए क्वेरी करने के लिए places_insights___us.places को तय किया गया है.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`
प्रोजेक्ट का नाम बताएं (ज़रूरी नहीं)
क्वेरी में अपने प्रोजेक्ट का नाम शामिल करना ज़रूरी नहीं है. अगर आपने प्रोजेक्ट का नाम नहीं दिया है, तो आपकी क्वेरी डिफ़ॉल्ट रूप से चालू प्रोजेक्ट पर लागू होगी.
अगर आपने अलग-अलग प्रोजेक्ट में एक ही नाम वाले डेटासेट लिंक किए हैं या आपको चालू प्रोजेक्ट के बाहर की किसी टेबल पर क्वेरी करनी है, तो आपको अपने प्रोजेक्ट का नाम शामिल करना पड़ सकता है.
उदाहरण के लिए, [project name].[dataset name].places.
एग्रीगेशन फ़ंक्शन तय करना
नीचे दिए गए उदाहरण में, BigQuery के साथ काम करने वाले एग्रीगेशन फ़ंक्शन दिखाए गए हैं. इस क्वेरी में, न्यूयॉर्क शहर में एंपायर स्टेट बिल्डिंग के 1,000 मीटर के दायरे में मौजूद सभी जगहों की रेटिंग को इकट्ठा किया जाता है, ताकि रेटिंग के आंकड़े तैयार किए जा सकें:
SELECT WITH AGGREGATION_THRESHOLD COUNT(id) AS place_count, APPROX_COUNT_DISTINCT(rating) as distinct_ratings, COUNTIF(rating > 4.0) as good_rating_count, LOGICAL_AND(rating <= 5) as all_ratings_equal_or_below_five, LOGICAL_OR(rating = 5) as any_rating_exactly_five, AVG(rating) as avg_rating, SUM(user_rating_count) as rating_count, COVAR_POP(rating, user_rating_count) as rating_covar_pop, COVAR_SAMP(rating, user_rating_count) as rating_covar_samp, STDDEV_POP(rating) as rating_stddev_pop, STDDEV_SAMP(rating) as rating_stddev_samp, VAR_POP(rating) as rating_var_pop, VAR_SAMP(rating) as rating_var_samp, FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL"
जगह के हिसाब से पाबंदी तय करना
अगर आपने जगह के हिसाब से पाबंदी नहीं लगाई है, तो डेटा एग्रीगेशन पूरे डेटासेट पर लागू होता है. आम तौर पर, किसी खास इलाके में खोज करने के लिए, जगह से जुड़ी पाबंदी तय की जाती है. इस उदाहरण क्वेरी में, न्यूयॉर्क शहर में मौजूद एम्पायर स्टेट बिल्डिंग को टारगेट करने की पाबंदी के बारे में बताया गया है. साथ ही, इसमें 1,000 मीटर के दायरे के बारे में भी बताया गया है.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000)
खोज के लिए, पॉलीगॉन का इस्तेमाल करके क्षेत्र तय किया जा सकता है. पॉलीगॉन का इस्तेमाल करते समय, पॉलीगॉन के पॉइंट एक क्लोज़्ड लूप तय करने चाहिए. साथ ही, पॉलीगॉन का पहला पॉइंट, आखिरी पॉइंट के जैसा होना चाहिए:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_CONTAINS(ST_GEOGFROMTEXT("""POLYGON((-73.985708 40.75773,-73.993324 40.750298, -73.9857 40.7484,-73.9785 40.7575, -73.985708 40.75773))"""), point)
यहां दिए गए उदाहरण में, कनेक्ट किए गए पॉइंट की लाइन का इस्तेमाल करके खोज का दायरा तय किया गया है. साथ ही, लाइन के चारों ओर खोज का दायरा 100 मीटर पर सेट किया गया है. यह लाइन, Routes API से कैलकुलेट किए गए यात्रा के रास्ते की तरह होती है. यह रूट किसी वाहन, साइकल या पैदल चलने वाले व्यक्ति के लिए हो सकता है:
DECLARE route GEOGRAPHY; SET route = ST_GEOGFROMTEXT("""LINESTRING(-73.98903537033028 40.73655649223003, -73.93580216278471 40.80955538843361)"""); SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(route, point, 100)
जगह के डेटासेट फ़ील्ड के हिसाब से फ़िल्टर करना
डेटासेट स्कीमा में तय किए गए फ़ील्ड के आधार पर, खोज के नतीजों को बेहतर बनाएं. डेटासेट फ़ील्ड के आधार पर नतीजों को फ़िल्टर करें. जैसे, जगह regular_opening_hours, price_level, और ग्राहक rating.
अपने देश के हिसाब से, डेटासेट के स्कीमा में तय किए गए किसी भी फ़ील्ड का रेफ़रंस दें. हर देश के लिए डेटासेट स्कीमा में दो हिस्से होते हैं:
- कोर स्कीमा, जो सभी देशों के डेटासेट के लिए सामान्य है.
- देश के हिसाब से स्कीमा जो उस देश के हिसाब से स्कीमा कॉम्पोनेंट तय करता है.
उदाहरण के लिए, आपकी क्वेरी में WHERE क्लॉज़ शामिल हो सकता है. यह क्लॉज़, क्वेरी के लिए फ़िल्टर करने की शर्तों को तय करता है.
यहां दिए गए उदाहरण में, true पर सेट किए गए tourist_attraction टाइप की जगहों के लिए एग्रीगेशन डेटा दिखाया गया है. इन जगहों का business_status OPERATIONAL है और rating 4.0 से ज़्यादा या इसके बराबर है:allows_dogs
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND 'tourist_attraction' IN UNNEST(types) AND business_status = "OPERATIONAL" AND rating >= 4.0 AND allows_dogs = true
अगली क्वेरी में, उन जगहों के नतीजे दिखाए गए हैं जहां कम से कम आठ ईवी चार्जिंग स्टेशन हैं:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
जगह के मुख्य टाइप और जगह के टाइप के हिसाब से फ़िल्टर करना
डेटासेट में मौजूद हर जगह के लिए, ये चीज़ें हो सकती हैं:
एक प्राइमरी टाइप, जो जगह के टाइप के हिसाब से तय किए गए टाइप में से किसी एक से जुड़ा हो. उदाहरण के लिए, प्राइमरी टाइप
mexican_restaurantयाsteak_houseहो सकता है. किसी जगह के मुख्य टाइप के हिसाब से नतीजों को फ़िल्टर करने के लिए, क्वेरी मेंprimary_typeका इस्तेमाल करें.कई तरह की वैल्यू, जो जगह के टाइप के हिसाब से तय किए गए टाइप से जुड़ी होती हैं. उदाहरण के लिए, किसी रेस्टोरेंट के ये टाइप हो सकते हैं:
seafood_restaurant,restaurant,food,point_of_interest,establishment. किसी जगह से जुड़े टाइप की सूची में मौजूद नतीजों को फ़िल्टर करने के लिए, क्वेरी मेंtypesका इस्तेमाल करें.
नीचे दी गई क्वेरी से, उन सभी जगहों के नतीजे मिलते हैं जिनका प्राइमरी टाइप skin_care_clinic है और जो spa के तौर पर भी काम करती हैं:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE 'spa' IN UNNEST(types) AND 'skin_care_clinic' = primary_type
जगह के आईडी के हिसाब से फ़िल्टर करना
नीचे दिए गए उदाहरण में, पांच जगहों की औसत रेटिंग का हिसाब लगाया गया है. जगहों की पहचान उनके place_id से की जाती है.
DECLARE place_ids ARRAY<STRING>; SET place_ids = ['ChIJPQOh8YVZwokRE2WsbZI4tOk', 'ChIJibtT3ohZwokR7tX0gp0nG8U', 'ChIJdfD8moVZwokRO6vxjXAtoWs', 'ChIJsdNONuFbwokRLM-yuifjb8k', 'ChIJp0gKoClawokR0txqrcaEkFc']; SELECT WITH AGGREGATION_THRESHOLD AVG(rating) as avg_rating, FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(place_ids) place_id WHERE id = place_id;
कुछ जगहों के आईडी को फ़िल्टर करना
क्वेरी से जगह के आईडी की एक रेंज को भी हटाया जा सकता है.
आपको जिन जगहों के आईडी चाहिए उन्हें ढूंढने के लिए, जगह के आईडी ढूंढने वाले टूल का इस्तेमाल करें. इसके अलावा, Places API का इस्तेमाल करके, टेक्स्ट सर्च (नई) का अनुरोध करके प्रोग्राम के हिसाब से भी ऐसा किया जा सकता है.
यहां दिए गए उदाहरण में, क्वेरी से यह पता चलता है कि सिडनी, ऑस्ट्रेलिया के 2000 पिन कोड में मौजूद ऐसे कैफ़े की संख्या कितनी है जो excluded_cafes ऐरे में नहीं दिखते. इस तरह की क्वेरी, कारोबार के मालिक के लिए मददगार हो सकती है. ऐसा तब होता है, जब वह अपने कारोबारों को गिनती में शामिल नहीं करना चाहता.
WITH excluded_cafes AS ( -- List the specific place IDs to exclude from the final count SELECT * FROM UNNEST([ 'ChIJLTcYGz-uEmsRmazk9oMnP5w', 'ChIJeWDDDNOvEmsRF8SMPUwPbhw', 'ChIJKdaKHbmvEmsRSdxq_1O05bU' ]) AS place_id ) SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `places_insights___au.places` AS places -- Perform a LEFT JOIN to identify which places are in the exclusion list LEFT JOIN excluded_cafes ON places.id = excluded_cafes.place_id WHERE -- Filter for specific place type and postal code places.primary_type = 'cafe' AND '2000' IN UNNEST(places.postal_code_names) -- Keep only the rows where the join failed (meaning the ID was NOT in the list) AND excluded_cafes.place_id IS NULL;
पहले से तय की गई डेटा वैल्यू के आधार पर फ़िल्टर करना
डेटासेट के कई फ़ील्ड के लिए, पहले से तय की गई वैल्यू होती हैं. उदाहरण के लिए
price_levelफ़ील्ड में, पहले से तय की गई ये वैल्यू इस्तेमाल की जा सकती हैं:PRICE_LEVEL_FREEPRICE_LEVEL_INEXPENSIVEPRICE_LEVEL_MODERATEPRICE_LEVEL_EXPENSIVEPRICE_LEVEL_VERY_EXPENSIVE
business_statusफ़ील्ड में, पहले से तय की गई ये वैल्यू इस्तेमाल की जा सकती हैं:OPERATIONALCLOSED_TEMPORARILYCLOSED_PERMANENTLY
इस उदाहरण में, क्वेरी से उन सभी फ़्लोरिस्ट की संख्या मिलती है जिनके पास न्यूयॉर्क शहर में एंपायर स्टेट बिल्डिंग के 1,000 मीटर के दायरे में OPERATIONAL का business_status है:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL" AND 'florist' IN UNNEST(types)
कामकाज के घंटों के हिसाब से फ़िल्टर करना
इस उदाहरण में, किसी भौगोलिक क्षेत्र में मौजूद उन सभी जगहों की संख्या दिखाएं जहां शुक्रवार को हैप्पी आवर होते हैं:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(regular_opening_hours_happy_hour.friday) AS friday_hours WHERE '17:00:00' BETWEEN friday_hours.start_time AND friday_hours.end_time AND ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000);
क्षेत्र (पते के कॉम्पोनेंट) के हिसाब से फ़िल्टर करना
हमारे जगहों के डेटासेट में, पते के कॉम्पोनेंट का एक सेट भी होता है. यह राजनीतिक सीमाओं के आधार पर नतीजों को फ़िल्टर करने के लिए काम आता है. पते के हर कॉम्पोनेंट की पहचान, उसके टेक्स्ट कोड के नाम (न्यूयॉर्क शहर के पिन कोड के लिए 10002) या जगह के आईडी (उसी पिन कोड के आईडी के लिए ChIJm5NfgIBZwokR6jLqucW0ipg) से की जाती है.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE '10002' IN UNNEST(postal_code_names) --- 'ChIJm5NfgIBZwokR6jLqucW0ipg' IN UNNEST(postal_code_ids) -- same filter as above using postal code ID
ईवी चार्जिंग स्टेशन के हिसाब से फ़िल्टर करना
इस उदाहरण में, उन जगहों की संख्या बताई गई है जहां कम से कम आठ ईवी चार्जर हैं:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
इस उदाहरण में, उन जगहों की संख्या का पता लगाया गया है जहां कम से कम 10 Tesla चार्जर हैं. ये चार्जर, फ़ास्ट चार्जिंग की सुविधा के साथ काम करते हैं:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(ev_charge_options.connector_aggregation) as connectors WHERE connectors.type ='EV_CONNECTOR_TYPE_TESLA' AND connectors.max_charge_rate_kw >= 50 AND connectors.count >= 10
नतीजे के ग्रुप दिखाएं
अब तक दिखाई गई क्वेरी के नतीजे में एक ही लाइन दिखती है. इसमें क्वेरी के लिए एग्रीगेशन की संख्या होती है. ग्रुपिंग के मानदंड के आधार पर, जवाब में एक से ज़्यादा पंक्तियां दिखाने के लिए, GROUP BY ऑपरेटर का भी इस्तेमाल किया जा सकता है.
उदाहरण के लिए, यहां दी गई क्वेरी से, खोज के दायरे में मौजूद हर जगह के मुख्य टाइप के हिसाब से ग्रुप किए गए नतीजे मिलते हैं:
SELECT WITH AGGREGATION_THRESHOLD primary_type, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.99992071622756, 40.71818785986936), point, 1000) GROUP BY primary_type
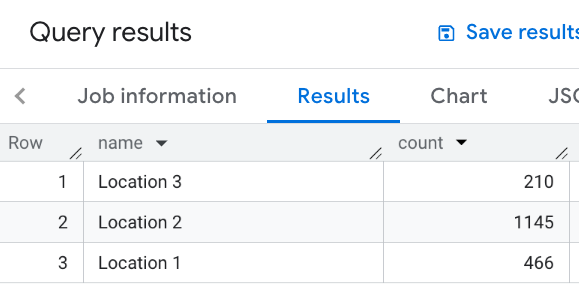
इस इमेज में, इस क्वेरी के आउटपुट का उदाहरण दिखाया गया है:

इस उदाहरण में, जगहों की एक टेबल तय की गई है. इसके बाद, हर जगह के लिए आस-पास मौजूद रेस्टोरेंट की संख्या का हिसाब लगाया जाता है. इसका मतलब है कि 1,000 मीटर के दायरे में मौजूद रेस्टोरेंट की संख्या:
WITH my_locations AS ( SELECT 'Location 1' AS name, ST_GEOGPOINT(-74.00776440888504, 40.70932825380786) AS location UNION ALL SELECT 'Location 2' AS name, ST_GEOGPOINT(-73.98257192833559, 40.750738934863215) AS location UNION ALL SELECT 'Location 3' AS name, ST_GEOGPOINT(-73.94701794263223, 40.80792954838445) AS location ) SELECT WITH AGGREGATION_THRESHOLD l.name, COUNT(*) as count FROM `PROJECT_NAME.places_insights___us.places` JOIN my_locations l ON ST_DWITHIN(l.location, p.point, 1000) WHERE primary_type = "restaurant" AND business_status = "OPERATIONAL" GROUP BY l.name
इस इमेज में, इस क्वेरी का उदाहरण आउटपुट दिखाया गया है: