Aby uzyskać bezpośredni dostęp do danych Statystyk miejsc, napisz w BigQuery zapytania SQL, które zwracają zagregowane statystyki dotyczące miejsc. Wyniki są zwracane ze zbioru danych na podstawie kryteriów wyszukiwania określonych w zapytaniu.
Jeśli potrzebujesz uzyskać liczby mniejsze niż 5, rozważ użycie funkcji Places Count zamiast. Funkcje te mogą zwracać dowolne liczby, w tym 0, ale wymagają minimalnego obszaru wyszukiwania o wymiarach 40 × 40 m (1600 m²). Dowiedz się więcej o tym, kiedy wysyłać zapytania bezpośrednio, a kiedy używać funkcji.
Podstawowe informacje na temat zapytań
Na ilustracji poniżej przedstawiono podstawowy format zapytania:

Każda część zapytania jest opisana bardziej szczegółowo poniżej.
Wymagania dotyczące zapytań
Zapytania SQL kierowane bezpośrednio do zbioru danych muszą określać zbiór danych i zawierać klauzulę WITH AGGREGATION_THRESHOLD w klauzuli SELECT. W przeciwnym razie zapytanie się nie powiedzie.
Ten przykład określa places_insights___us.places, aby wysłać zapytanie do zbioru danych w Stanach Zjednoczonych.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`
Określanie nazwy projektu (opcjonalnie)
W zapytaniu możesz opcjonalnie uwzględnić nazwę projektu. Jeśli nie określisz nazwy projektu, zapytanie domyślnie będzie dotyczyć aktywnego projektu.
Nazwę projektu warto uwzględnić, jeśli masz połączone zbiory danych o tej samej nazwie w różnych projektach lub jeśli wysyłasz zapytanie do tabeli spoza aktywnego projektu.
Na przykład [project name].[dataset name].places.
Określanie funkcji agregacji
Poniższy przykład pokazuje obsługiwane funkcje agregacji BigQuery. To zapytanie agreguje oceny wszystkich miejsc znajdujących się w promieniu 1000 metrów od Empire State Building w Nowym Jorku, aby uzyskać statystyki ocen:
SELECT WITH AGGREGATION_THRESHOLD COUNT(id) AS place_count, APPROX_COUNT_DISTINCT(rating) as distinct_ratings, COUNTIF(rating > 4.0) as good_rating_count, LOGICAL_AND(rating <= 5) as all_ratings_equal_or_below_five, LOGICAL_OR(rating = 5) as any_rating_exactly_five, AVG(rating) as avg_rating, SUM(user_rating_count) as rating_count, COVAR_POP(rating, user_rating_count) as rating_covar_pop, COVAR_SAMP(rating, user_rating_count) as rating_covar_samp, STDDEV_POP(rating) as rating_stddev_pop, STDDEV_SAMP(rating) as rating_stddev_samp, VAR_POP(rating) as rating_var_pop, VAR_SAMP(rating) as rating_var_samp, FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL"
Określanie ograniczenia lokalizacji
Jeśli nie określisz ograniczenia lokalizacji, agregacja danych zostanie zastosowana do całego zbioru danych. Zazwyczaj określasz ograniczenie lokalizacji, aby wyszukać określony obszar. Ten przykładowy zbiór danych określa ograniczenie docelowe wyśrodkowane na Empire State Building w Nowym Jorku o promieniu 1000 metrów.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000)
Obszar wyszukiwania możesz określić za pomocą wielokąta. W przypadku wielokąta jego punkty muszą tworzyć zamkniętą pętlę, w której pierwszy punkt jest taki sam jak ostatni:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_CONTAINS(ST_GEOGFROMTEXT("""POLYGON((-73.985708 40.75773,-73.993324 40.750298, -73.9857 40.7484,-73.9785 40.7575, -73.985708 40.75773))"""), point)
W następnym przykładzie obszar wyszukiwania jest definiowany za pomocą linii połączonych punktów, a promień wyszukiwania jest ustawiony na 100 metrów od linii. Linia jest podobna do trasy podróży obliczonej przez interfejs Routes API. Trasa może być przeznaczona dla pojazdu, roweru lub pieszego:
DECLARE route GEOGRAPHY; SET route = ST_GEOGFROMTEXT("""LINESTRING(-73.98903537033028 40.73655649223003, -73.93580216278471 40.80955538843361)"""); SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(route, point, 100)
Filtrowanie według pól zbioru danych o miejscach
Zawęź wyszukiwanie na podstawie pól zdefiniowanych przez schemat
zbioru danych. Filtruj wyniki na podstawie pól zbioru danych, takich jak regular_opening_hours, price_level i rating.
Odwołuj się do dowolnych pól w zbiorze danych zdefiniowanych przez schemat zbioru danych dla interesującego Cię kraju. Schemat zbioru danych dla każdego kraju składa się z 2 części:
- Schemat podstawowy, który jest wspólny dla zbiorów danych we wszystkich krajach.
- Schemat specyficzny dla danego kraju, który określa komponenty schematu charakterystyczne dla tego kraju.
Zapytanie może np. zawierać klauzulę WHERE, która określa kryteria filtrowania zapytania.
W tym przykładzie zwracasz dane agregacji dla miejsc typu tourist_attraction o stanie business_status równym OPERATIONAL, które mają rating większy lub równy 4,0 oraz allows_dogs ustawione na true:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND 'tourist_attraction' IN UNNEST(types) AND business_status = "OPERATIONAL" AND rating >= 4.0 AND allows_dogs = true
Następne zapytanie zwraca wyniki dla miejsc, które mają co najmniej 8 stacji ładowania EV:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
Filtrowanie według podstawowego typu miejsca i typu miejsca
Każde miejsce w zbiorze danych może mieć:
Jeden podstawowy typ powiązany z typami zdefiniowanymi przez typy miejsc. Podstawowy typ może być np.
mexican_restaurantlubsteak_house. Użyjprimary_typew zapytaniu, aby filtrować wyniki według podstawowego typu miejsca.Wiele wartości typu powiązanych z typami zdefiniowanymi przez typy miejsc. Restauracja może mieć np. te typy:
seafood_restaurant,restaurant,food,point_of_interest,establishment. Użyjtypesw zapytaniu, aby filtrować wyniki według listy typów powiązanych z miejscem.
To zapytanie zwraca wyniki dla wszystkich miejsc o podstawowym typie skin_care_clinic, które działają też jako spa:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE 'spa' IN UNNEST(types) AND 'skin_care_clinic' = primary_type
Filtrowanie według identyfikatora miejsca
Poniższy przykład oblicza średnią ocenę 5 miejsc. Miejsca są identyfikowane za pomocą place_id.
DECLARE place_ids ARRAY<STRING>; SET place_ids = ['ChIJPQOh8YVZwokRE2WsbZI4tOk', 'ChIJibtT3ohZwokR7tX0gp0nG8U', 'ChIJdfD8moVZwokRO6vxjXAtoWs', 'ChIJsdNONuFbwokRLM-yuifjb8k', 'ChIJp0gKoClawokR0txqrcaEkFc']; SELECT WITH AGGREGATION_THRESHOLD AVG(rating) as avg_rating, FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(place_ids) place_id WHERE id = place_id;
Odfiltrowywanie określonych identyfikatorów miejsc
Możesz też wykluczyć z zapytania tablicę identyfikatorów miejsc.
Identyfikatory miejsc, których szukasz, możesz znaleźć za pomocą narzędzia do wyszukiwania identyfikatorów miejsc lub programowo za pomocą interfejsu Places API, wysyłając żądanie wyszukiwania tekstowego (nowe).
W poniższym przykładzie zapytanie znajduje liczbę kawiarni w kodzie pocztowym 2000
w Sydney w Australii, które nie znajdują się w tablicy excluded_cafes. Takie zapytanie może być przydatne dla właściciela firmy, który chce wykluczyć własne firmy z liczby.
WITH excluded_cafes AS ( -- List the specific place IDs to exclude from the final count SELECT * FROM UNNEST([ 'ChIJLTcYGz-uEmsRmazk9oMnP5w', 'ChIJeWDDDNOvEmsRF8SMPUwPbhw', 'ChIJKdaKHbmvEmsRSdxq_1O05bU' ]) AS place_id ) SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `places_insights___au.places` AS places -- Perform a LEFT JOIN to identify which places are in the exclusion list LEFT JOIN excluded_cafes ON places.id = excluded_cafes.place_id WHERE -- Filter for specific place type and postal code places.primary_type = 'cafe' AND '2000' IN UNNEST(places.postal_code_names) -- Keep only the rows where the join failed (meaning the ID was NOT in the list) AND excluded_cafes.place_id IS NULL;
Filtrowanie według wstępnie zdefiniowanych wartości danych
Wiele pól zbioru danych ma wstępnie zdefiniowane wartości. Na przykład:
Pole
price_levelobsługuje te wstępnie zdefiniowane wartości:PRICE_LEVEL_FREEPRICE_LEVEL_INEXPENSIVEPRICE_LEVEL_MODERATEPRICE_LEVEL_EXPENSIVEPRICE_LEVEL_VERY_EXPENSIVE
Pole
business_statusobsługuje te wstępnie zdefiniowane wartości:OPERATIONALCLOSED_TEMPORARILYCLOSED_PERMANENTLYFUTURE_OPENING
W tym przykładzie zapytanie zwraca liczbę wszystkich kwiaciarni o stanie business_status równym OPERATIONAL w promieniu 1000 metrów od Empire State Building w Nowym Jorku:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL" AND 'florist' IN UNNEST(types)
Filtrowanie według godzin otwarcia
W tym przykładzie zwracasz liczbę wszystkich miejsc na obszarze geograficznym, w których w piątki obowiązują happy hours:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(regular_opening_hours_happy_hour.friday) AS friday_hours WHERE '17:00:00' BETWEEN friday_hours.start_time AND friday_hours.end_time AND ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000);
Filtrowanie według regionu (komponenty adresu)
Nasz zbiór danych o miejscach zawiera też zestaw komponentów adresu, które są przydatne do filtrowania wyników na podstawie granic politycznych. Każdy komponent adresu jest identyfikowany za pomocą nazwy kodu tekstowego (10002 w przypadku kodu pocztowego w Nowym Jorku) lub identyfikatora miejsca (ChIJm5NfgIBZwokR6jLqucW0ipg) dla równoważnego identyfikatora kodu pocztowego.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE '10002' IN UNNEST(postal_code_names) --- 'ChIJm5NfgIBZwokR6jLqucW0ipg' IN UNNEST(postal_code_ids) -- same filter as above using postal code ID
Filtrowanie według stacji ładowania EV
Ten przykład podaje liczbę miejsc z co najmniej 8 ładowarkami EV:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
Ten przykład zlicza liczbę miejsc, które mają co najmniej 10 ładowarek Tesla obsługujących szybkie ładowanie:
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(ev_charge_options.connector_aggregation) as connectors WHERE connectors.type ='EV_CONNECTOR_TYPE_TESLA' AND connectors.max_charge_rate_kw >= 50 AND connectors.count >= 10
Zwracanie grup wyników
Pokazane dotychczas zapytania zwracają w wyniku jeden wiersz zawierający liczbę agregacji dla zapytania. Możesz też użyć operatora GROUP BY, aby zwracać w odpowiedzi wiele wierszy na podstawie kryteriów grupowania.
Na przykład to zapytanie zwraca wyniki pogrupowane według podstawowego typu każdego miejsca w obszarze wyszukiwania:
SELECT WITH AGGREGATION_THRESHOLD primary_type, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.99992071622756, 40.71818785986936), point, 1000) GROUP BY primary_type
Ta ilustracja przedstawia przykładowe dane wyjściowe tego zapytania:

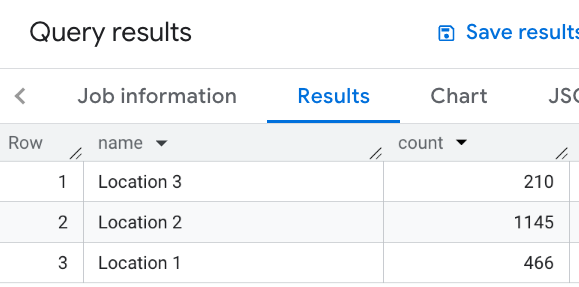
W tym przykładzie definiujesz tabelę lokalizacji. Następnie dla każdej lokalizacji obliczasz liczbę pobliskich restauracji, czyli tych, które znajdują się w promieniu 1000 metrów:
WITH my_locations AS ( SELECT 'Location 1' AS name, ST_GEOGPOINT(-74.00776440888504, 40.70932825380786) AS location UNION ALL SELECT 'Location 2' AS name, ST_GEOGPOINT(-73.98257192833559, 40.750738934863215) AS location UNION ALL SELECT 'Location 3' AS name, ST_GEOGPOINT(-73.94701794263223, 40.80792954838445) AS location ) SELECT WITH AGGREGATION_THRESHOLD l.name, COUNT(*) as count FROM `PROJECT_NAME.places_insights___us.places` JOIN my_locations l ON ST_DWITHIN(l.location, p.point, 1000) WHERE primary_type = "restaurant" AND business_status = "OPERATIONAL" GROUP BY l.name
Ta ilustracja przedstawia przykładowe dane wyjściowe tego zapytania: