Der Aggregation Service generiert zusammenfassende Berichte mit detaillierten Conversion-Daten und Reichweitenmessungen aus aggregierbaren Rohdatenberichten. Anzeigentechnologie-Anbieter haben clientseitige zentrale Einstiegspunkte, um Berichte an den Aggregationsdienst zu leiten – entweder über die Attribution Reporting API oder die Private Aggregation API.
Implementierungsstatus
- Der Aggregationsdienst ist jetzt allgemein verfügbar.
- Der Aggregationsdienst kann mit der Attribution Reporting API und der Private Aggregation API für die Protected Audience API und die Shared Storage API verwendet werden.
Verfügbarkeit
| Vorschlag | Status |
|---|---|
| Unterstützung des Aggregation Service für Amazon Web Services (AWS) in der Attribution Reporting API und der Private Aggregation API
Erklärung |
Verfügbar |
| Unterstützung des Aggregation Service für Google Cloud in der Attribution Reporting API, Private Aggregation API Erläuterung |
Verfügbar |
| Websiteregistrierung für den Aggregationsdienst und Multi-Origin-Aggregation Die Websiteregistrierung umfasst die Zuordnung einer Website zu Cloud-Konten (AWS oder GCP). Wenn Sie mehrere Ursprünge zusammenfassen möchten, müssen sie von derselben Website stammen.
FAQs auf GitHub Dokumentation zur Site Aggregation API |
Verfügbar |
| Der Epsilon-Wert des Aggregationsdienstes wird bis zu 64 Werte beibehalten, um Tests und Feedback zu verschiedenen Parametern zu erleichtern.
Feedback zu ARA-Epsilon senden. PAA-Epsilon-Feedback geben |
Verfügbar Wir informieren das System im Voraus, bevor die Werte für den Epsilon-Bereich aktualisiert werden. |
| Flexiblere Filterung von Beiträgen für Aggregationsdienstabfragen
Erklärung |
Verfügbar |
| Prozess für Budgetwiederherstellung nach Notfällen (Fehler, Fehlkonfigurationen usw.)
Erklärung |
Verfügbar Mechanismus zur Überprüfung des Prozentsatzes freigegebener IDs, der von einem Anzeigentechnologie-Anbieter über eine Budgetausgleichung wiederhergestellt wurde, und künftige Wiederherstellungen aufgrund übermäßiger Wiederherstellungen aussetzen, die für das 1. Halbjahr 2025 geplant sind |
| Accenture als einer der Koordinatoren bei AWS
Entwicklerblog |
Verfügbar |
| Unabhängige Partei, die als eine der Koordinierungsstellen in Google Cloud tätig ist
Entwicklerblog |
Verfügbar |
| Unterstützung des Aggregation Service für zusammengefasste Fehlerbehebungsberichte in der Attribution Reporting API
Erklärung |
Verfügbar |
Wichtige Begriffe und Konzepte
Wenn Sie den Zusammenfassungsdienst in Ihrem Anzeigentechnologie-Workflow verwenden möchten, sollten die folgenden Begriffe und Konzepte einen besseren Einblick in die Vorteile dieses neuen Aggregationsvorgangs für Ihr Team bieten:
| 术语 | 说明 |
|---|---|
| 汇总服务 | 由广告技术平台运营的服务,用于处理可汇总报告以创建摘要报告。 |
| 可汇总的报告 |
Aggregierbare Berichte sind verschlüsselte Berichte, die von den Geräten einzelner Nutzer gesendet werden. Diese Berichte enthalten Daten über websiteübergreifendes Nutzerverhalten und Conversions. Conversions (manchmal auch als Attributionstrigger-Ereignisse bezeichnet) und zugehörige Messwerte werden vom Werbetreibenden oder der Anzeigentechnologie definiert. Jeder Bericht wird verschlüsselt, damit verschiedene Parteien nicht auf die zugrunde liegenden Daten zugreifen können. 详细了解可汇总的报告。 |
| 可汇总报告的会计核算 | 位于两个协调器中的分布式账本,用于跟踪分配的隐私预算并强制执行“无重复”规则。这是一种隐私保护机制,位于协调者中并在其中运行,可确保通过汇总服务传递的报告不会超出分配的隐私预算。 详细了解批处理策略与可汇总报告的关系。 |
| 可汇总报告的会计核算预算 | 对预算的引用,用于确保报告不会被处理多次。 |
| 可信执行环境 (TEE) |
可信执行环境是计算机硬件和软件的一种特殊配置, 验证计算机上运行的软件的确切版本。TEEs 允许外部各方验证软件是否完全按照 软件制造商声称可以,不多或少。 如需详细了解用于 Privacy Sandbox 提案的 TEE,请参阅 Protected Audience API 服务说明文档 以及汇总服务说明。 |
| 协调员 |
Ein Koordinator ist eine Entität, die für die Schlüsselverwaltung und die Buchhaltung für aggregierte Berichte verantwortlich ist. Der Koordinator verwaltet eine Liste der Hashes genehmigter Aggregationsdienstkonfigurationen und konfiguriert den Zugriff auf Entschlüsselungsschlüssel. |
| 共享 ID |
计算值,由以下各项组成:shared_info、reporting_origin、destination_site(仅适用于 Attribution Reporting API)、source_registration-time(仅适用于 Attribution Reporting API)、scheduled_report_time、version。
这意味着,如果多个报告具有相同的 shared_info 字段属性,则它们属于同一共享 ID。这在可汇总报告会计中起着重要作用。
详细了解可信服务器。
|
| 汇总报告 |
摘要报告是一种 Attribution Reporting API 和 Private Aggregation API 报告类型。摘要报告包含汇总的用户数据,并且可能包含添加了噪声的详细转化数据。摘要报告由汇总报告组成。与事件级报告相比,摘要报告具有更大的灵活性和数据模型,尤其是对于某些应用场景(例如转化价值)。 |
| 举报来源 |
Der Ursprung der Berichterstellung ist die Entität, die aggregierte Berichte erhält, d. h. die Anzeigentechnologie. die Attribution Reporting API. Aggregierte Berichte werden gesendet von Nutzergeräte an eine bekannte URL, die der Berichterstellung zugeordnet ist Ursprung. Dieser Berichtsorigin sollte bei der Registrierung angegeben werden. |
| 贡献债券 | 可汇总的报告可以包含任意数量的计数器增量。例如,报告中可能包含用户在广告客户网站上查看过的商品数量。与单个来源事件相关的所有可汇总报告中的增量之和不得超过给定限制“L1=2^16”。 如需了解详情,请参阅可汇总报告说明。 |
| 噪声和缩放 | 在汇总过程中,系统会向摘要报告添加一定量的统计噪声,这也有助于保护隐私并确保最终报告提供匿名化效果衡量信息。详细了解加法噪声机制,该机制是从拉普拉斯分布中提取的。 |
| 证明 |
认证是一种用于对软件身份进行身份验证的机制,通常使用加密哈希或签名。对于汇总服务方案,证明会将广告技术平台运营的汇总服务中运行的代码与开放源代码进行匹配。 详细了解证明。 |
Weitere Informationen zur Entstehungsgeschichte des Aggregationsdiensts finden Sie in unserem Erläuterungsartikel und in der vollständigen Liste der Begriffe.
Anwendungsfälle für Aggregation
Im Folgenden finden Sie Beispiele für die Entwicklung von Anzeigenmessungen und die zugehörigen Clientbibliotheken.
| Anwendungsfall | Einstiegspunkt | Beschreibung |
|---|---|---|
| Gebotsoptimierung | Attribution Reporting API (Chrome und Android) | Verwenden Sie zusammengefasste Berichte, um Conversion-Signale zur Gebotsoptimierung zu verarbeiten. |
| Plattformübergreifende Analyse | Attribution Reporting API (Chrome und Android) | Mit den web- und appübergreifenden Analysefunktionen können Sie die Leistung in Chrome und Android im Blick behalten. |
| Conversion-Berichte | Attribution Reporting API (Chrome und Android) | Erstellen Sie zusammengefasste Conversion-Berichte, die auf die Kampagnenanforderungen der Kunden zugeschnitten sind (einschließlich CTCs und VTCs). |
| Messung der Kampagnenreichweite | Shared Storage API und Private Aggregation API (Chrome) | Verwenden Sie websiteübergreifende Variablen für Anzeigenaufrufe, um die Kampagnenreichweite zu messen. |
| Berichte zu demografischen Merkmalen | Shared Storage API und Private Aggregation API (Chrome) | Verwenden Sie standortübergreifende Anzeigenaufrufe und demografische Informationen, um die Reichweite nach demografischen Merkmalen zu messen. |
| Conversion-Pfad-Analyse | Shared Storage API und Private Aggregation API (Chrome) | Speichern Sie websiteübergreifende Anzeigenaufruf- und Conversion-Variablen, um aggregierte Conversion-Pfadanalysen durchzuführen. |
| Anzeigenwirkung auf die Markenbekanntheit und Conversion-Steigerung | Shared Storage API und Private Aggregation API (Chrome) | Berichte zu Test-/Kontrollgruppen und Umfragedaten, um die Anzeigenwirkung auf die Markenbekanntheit und die Steigerung der Conversions zu messen. |
| Fehlerbehebung für Auktionen | Protected Audience API und Private Aggregation API (Chrome) | Verwenden Sie zusammengefasste Berichte zur Fehlerbehebung. |
| Verteilung der Gebote | Protected Audience API und Private Aggregation API (Chrome) | Zusammengefasste Berichte verwenden, um die Verteilung der Gebotswerte für Auktionen zu erfassen |
End-to-End-Ablauf
Das folgende Diagramm zeigt den Aggregationsdienst in Aktion. Wir konzentrieren uns auf den End-to-End-Vorgang vom Empfang der Berichte aus dem Web und von Mobilgeräten bis zum Erstellen der Zusammenfassungsberichte im Aggregationsdienst.
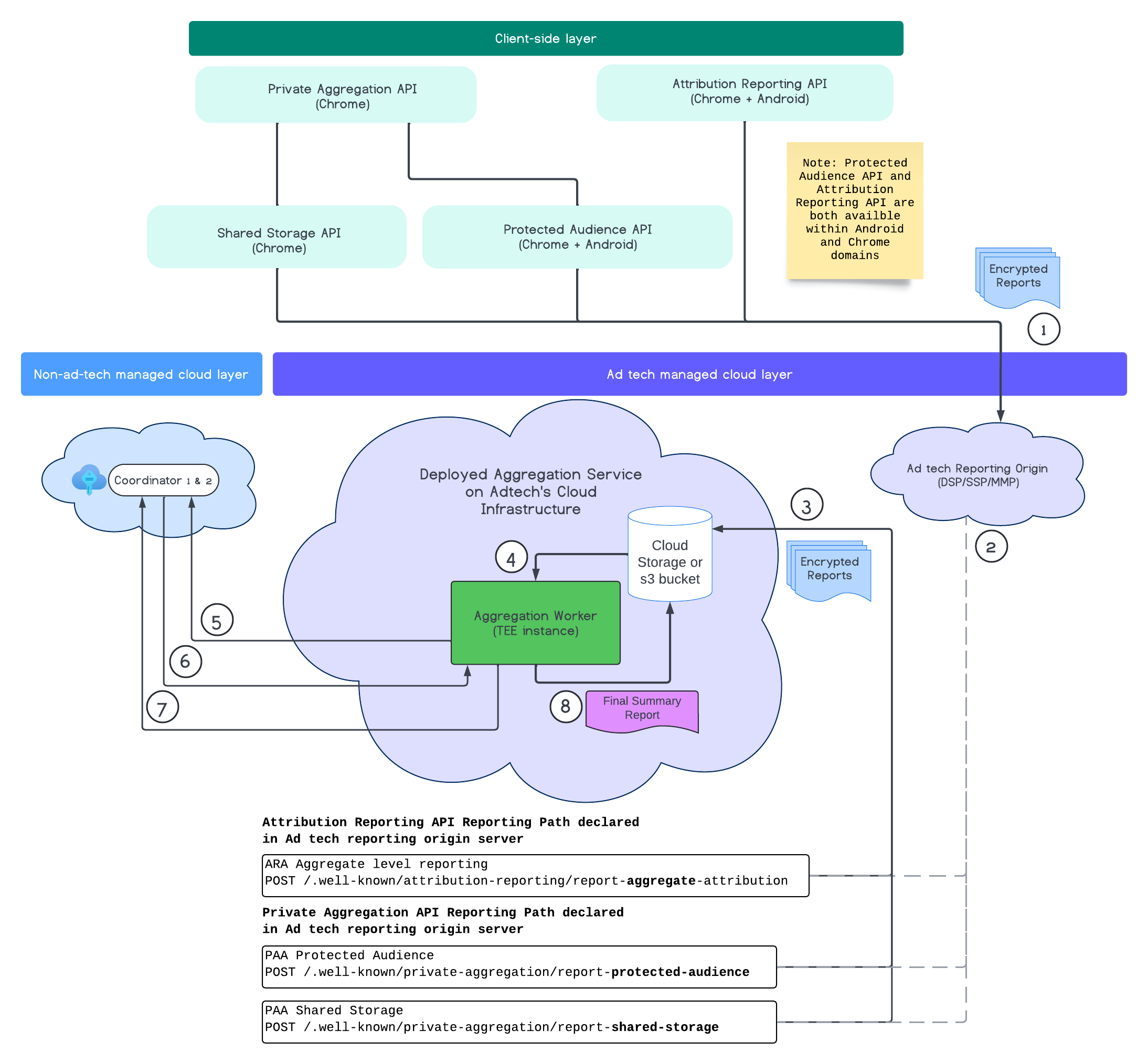
- Rufen Sie den öffentlichen Schlüssel ab, um verschlüsselte Berichte zu generieren.
- Verschlüsselte, aggregierte Berichte, die zur Erfassung, Transformation und Batchverarbeitung an AdTech-Server gesendet werden.
- Der Ad Tech-Server fasst Berichte im Avro-Format zusammen und sendet sie an den bereitgestellten Aggregationsdienst. (muss von der Anzeigentechnologie ausgefüllt werden).
- Aggregierte Berichte abrufen, die entschlüsselt werden sollen.
- Entschlüsselungsschlüssel von Koordinatoren abrufen
- Der Aggregation Service entschlüsselt Berichte für Aggregation und Rauschen.
- Der Dienst zur Abrechnung von aggregierten Berichten prüft, ob noch ein Datenschutzbudget vorhanden ist, um einen zusammengefassten Bericht für die angegebenen aggregierten Berichte zu erstellen.
- Reichen Sie den abschließenden zusammenfassenden Bericht ein.
Im Diagramm sehen Sie die Gesamtbeziehung zwischen dem Aggregationsdienst und den wichtigsten APIs für die Kundenmessung: Attribution Reporting API, Private Aggregation API und Koordinatoren.
Der Ablauf beginnt mit verschiedenen Measurement APIs wie der Attribution Reporting API oder der Private Aggregation API, die Berichte aus mehreren Browserinstanzen generieren. Chrome verwendet den öffentlichen Schlüssel aus dem Schlüssel-Hosting-Dienst im Koordinator, um die Berichte zu verschlüsseln, bevor sie an den Berichtsorigin der Anzeigentechnologie gesendet werden. Öffentliche Schlüssel werden alle sieben Tage rotiert.
Sobald die Berichtsquelle der Anzeigentechnologie diese Berichte erhält, sollte sie so konfiguriert werden, dass sie diese Berichte erfasst, in das Avro-Format konvertiert und an die bereitgestellte Instanz des Aggregationsdienstes sendet. Weitere Informationen zu Batching-Strategien
Sobald die Anzeigentechnologie für die Batchverarbeitung bereit ist, erstellt sie eine Batchanfrage an den Aggregationsdienst. Dort werden die Berichte entschlüsselt, indem die Entschlüsselungsschlüssel aus dem Schlüssel-Hostingdienst abgerufen werden. Anschließend werden sie aggregiert und mit Rauschen versehen, um einen Zusammenfassungsbericht zu erstellen. Dies hängt davon ab, ob das Datenschutzbudget ausreichend ist, um die endgültigen zusammenfassenden Berichte zu erstellen.
Der Endpunkt für die AdTech-Berichterstellung, an dem die Berichte erfasst werden, wird von der Anzeigentechnologie gehostet und der Zusammenfassungsdienst wird in der Cloud der Anzeigentechnologie bereitgestellt.
Batchverarbeitung von aggregierten Berichten
Der Berichtsablauf wäre ohne den dafür vorgesehenen Ursprungsserver für Berichte nicht vollständig. Dies ist der Ursprung, den ein Anzeigentechnologie-Anbieter bei der Registrierung angegeben hätte. Die Hauptaktionen, für die die Berichtsquelle verantwortlich ist, sind das Erfassen, Transformieren und Batchen der empfangenen aggregierbaren Berichte und die Vorbereitung für den Versand an den bereitgestellten Aggregationsdienst der Anzeigentechnologie in Google Cloud oder Amazon Web Services. Weitere Informationen zum Erstellen von aggregierten Berichten
Nachdem Sie nun das allgemeine Konzept kennen, sollten Sie sich die Komponenten genauer ansehen, die im Aggregationsdienst bereitgestellt werden.
Cloud-Komponenten
Der Aggregationsdienst besteht aus verschiedenen Cloud-Dienstkomponenten. Die bereitgestellten Terraform-Scripts stellen alle erforderlichen Cloud-Dienstkomponenten bereit und konfigurieren sie.
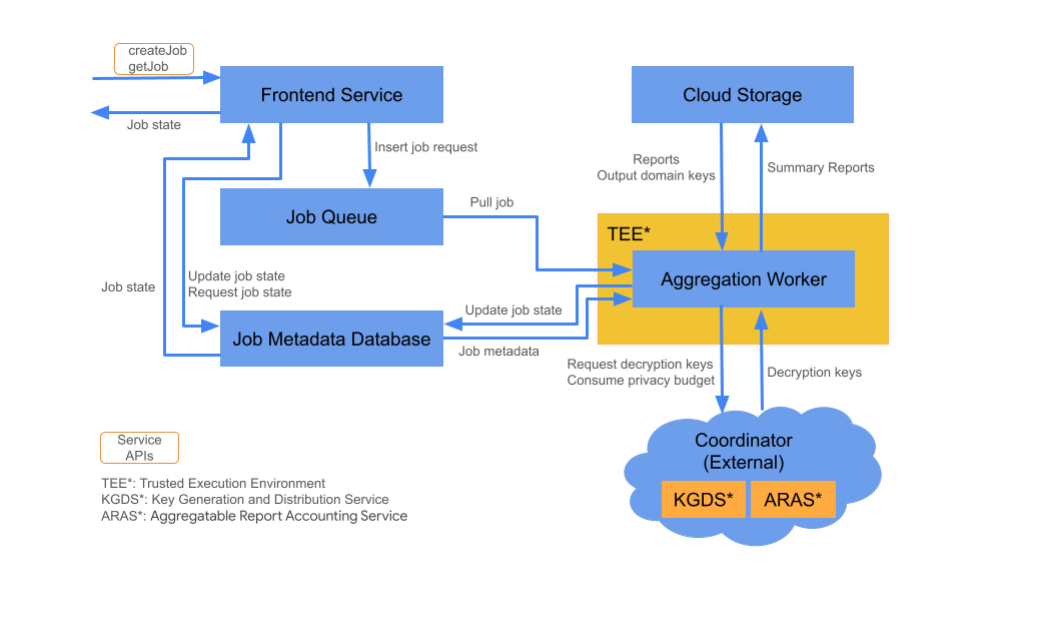
Frontend-Dienst
Verwalteter Cloud-Dienst: Cloud Function (Google Cloud) / API Gateway (Amazon Web Services)
Der Front-End-Dienst ist ein serverloses Gateway, das als Einstiegspunkt für Aggregation API-Aufrufe zum Erstellen und Abrufen des Jobstatus dient. Er ist für den Empfang von Anfragen von Nutzern des Aggregationsdiensts, die Validierung von Eingabeparametern und die Initiierung des Aggregationsjobs verantwortlich.
Im Front-End-Dienst sind zwei APIs verfügbar:
| Endpunkt | Beschreibung |
|---|---|
createJob |
Diese API löst einen Job des Aggregationsdiensts aus. Er benötigt Informationen zum Auslösen eines Jobs, z. B. Job-ID, Details zum Eingabespeicher, Details zum Ausgabespeicher, Berichtsquelle usw. |
getJob |
Diese API gibt den Status eines Jobs für eine angegebene Job-ID zurück. Sie enthält Informationen zum Status des Auftrags, z. B. "Empfangen", "In Bearbeitung" oder "Abgeschlossen". Wenn der Job abgeschlossen ist, wird außerdem das Jobergebnis angezeigt, einschließlich aller Fehlermeldungen, die während der Jobausführung aufgetreten sind. |
Weitere Informationen finden Sie in der Aggregation Service API-Dokumentation.
Jobwarteschlange
Verwalteter Cloud-Dienst: Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
Die Jobwarteschlange ist eine Nachrichtenwarteschlange, in der Jobanfragen für den Aggregationsdienst gespeichert werden. Der Frontend-Dienst fügt Jobanfragenachrichten in die Warteschlange ein, die dann vom Aggregation Worker zur Verarbeitung der Jobanfrage verwendet werden.
Cloud-Speicher
Managed Cloud-Dienst: Google Cloud Storage (Google Cloud) und Amazon S3 (Amazon Web Services). Cloud Storage wird zum Speichern von Ein- und Ausgabedateien verwendet, die vom Aggregationsdienst verwendet werden (z. B. verschlüsselte Berichtsdateien oder Zusammenfassungsberichte für die Ausgabe).
Datenbank mit Job-Metadaten
Managed Cloud-Dienst:Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
In der Job-Metadatendatenbank wird der Status von Aggregationsjobs gespeichert und verfolgt. Die Datenbank zeichnet Metadaten wie die Erstellungszeit, die angeforderte Zeit, die aktualisierte Zeit und den Status auf (z. B. „Empfangen“, „In Bearbeitung“, „Abgeschlossen“). Der Aggregations-Worker aktualisiert die Job-Metadatendatenbank während des Jobs.
Aggregations-Worker
Verwalteter Cloud-Dienst: Compute Engine mit vertraulichem Bereich (Google Cloud) / Amazon Web Services EC2 mit Nitro Enclave (Amazon Web Services)
Der Aggregation Worker verarbeitet Jobanfragen, die durch eine Jobanfrage in der Jobwarteschlange initiiert wurden. Dabei werden die verschlüsselten Eingaben mit Schlüsseln entschlüsselt, die von den Koordinatoren aus dem Key Generation and Distribution Service (KGDS) abgerufen werden. Um die Latenz bei der Jobverarbeitung zu minimieren, werden Entschlüsselungsschlüssel für einen Zeitraum von 8 Stunden im Aggregation Worker im Cache gespeichert und können für alle Jobs verwendet werden, die von dieser Worker-Instanz verarbeitet werden.
Der Worker wird in einer Trusted Execution Environment (TEE)-Instanz ausgeführt. Jeder Worker bearbeitet jeweils nur einen Auftrag. AdTech kann mehrere Worker so konfigurieren, dass sie Jobs parallel verarbeiten, indem die Autoscaling-Konfiguration festgelegt wird. Durch das Autoscaling wird die Anzahl der Worker dynamisch an die Anzahl der verbleibenden Nachrichten in der Jobwarteschlange angepasst. Die Mindest- und Höchstanzahl der Worker für das Autoscaling kann über die Terraform-Umgebungsdatei konfiguriert werden. Weitere Informationen zum Autoscaling finden Sie in den folgenden Terraform-Skripts. [Amazon Web Services / Google Cloud]
Der Aggregations-Worker ruft den Aggregierbaren Report Accounting-Dienst für die Aggregierungsberichten auf. Der Abrechnungsdienst für aggregierte Berichte stellt sicher, dass Jobs nur so lange ausgeführt werden, wie das Datenschutzbudgetlimit noch nicht überschritten wurde. (Siehe Regel „Keine Duplikate“.) Wenn das Budget verfügbar ist, wird ein Zusammenfassungsbericht mit den fehlerhaften Aggregaten erstellt. Weitere Informationen zu aggregierbaren Berichten
Der Aggregation Worker aktualisiert die Jobmetadaten in der Job-Metadatendatenbank, einschließlich der entsprechenden Job-Rückgabecodes und Berichtsfehlerzähler bei teilweisen Berichtsfehlern. Nutzer können den Status mithilfe der Jobstatus-Abruf-API (getJob) abrufen.
Eine ausführlichere Beschreibung des Zusammenfassungsdienstes finden Sie in der Erläuterung.
Nächste Schritte
Nachdem Sie nun die Highlights des Aggregationsdienstes kennengelernt haben, können Sie Ihre eigene Instanz des Aggregationsdienstes über Google Cloud oder Amazon Web Services bereitstellen. Weitere Informationen finden Sie im Abschnitt „Erste Schritte“. Wenn Sie weitere Informationen zum Betrieb eines bereitgestellten Aggregationsdienstes benötigen, folgen Sie diesem Link, um mehr über den Betrieb des Aggregationsdienstes zu erfahren.
Fehlerbehebung
Im Dokument Häufige Fehlercodes und Abhilfemaßnahmen finden Sie detailliertere Beschreibungen von Fehlermeldungen, mögliche Ursachen für den Fehler und die nächsten Schritte zur Abhilfe.
Support anfordern und Feedback geben
- Bei technischen Problemen, Produktfragen, Feedback und Funktionsanfragen können Sie Probleme in unserem GitHub-Repository erstellen.
- Wenn Sie für die Fehlerbehebung vertrauliche oder proprietäre Informationen angeben müssen, wenden Sie sich an aggregation-service-support@google.com.
- Prüfen Sie das öffentliche Status-Dashboard auf bekannte Probleme.