汇总服务会根据原始可汇总报告生成摘要报告,其中包含详细的转化数据和覆盖面衡量结果。为了确保用户数据的隐私性和安全性,汇总服务使用支持差分隐私 (DP) 的框架来量化和限制这些报告中显示的有关个别用户的信息量。
本指南介绍了用于创建可汇总报告的工具和策略,这些报告有助于保护与具体用户相关的数据:
- 创建添加了噪声的摘要报告
- 设置贡献预算
- 报告批处理策略
- 使用预声明的汇总键
添加了噪声的摘要报告
当您批量处理可汇总的报告时,汇总服务会创建摘要报告。此摘要报告汇总了所有预定义网域键的所有贡献,并添加了统计噪声。
报告中添加的噪声不取决于汇总的报告数量、单个报告值或汇总报告值。噪声是从离散版 Laplace 分布中提取的,并会根据相应的衡量 API 和隐私参数 epsilon 缩放到客户端强制执行的贡献预算 (L1 敏感度)。
如需详细了解噪声及其对报告数据的影响,请参阅了解摘要报告中的噪声。
贡献预算
为了控制摘要报告的敏感性,调用中传递的贡献数量与特定的贡献边界限制(也称为贡献预算)相关联。贡献预算因您使用的是 Attribution Reporting API 还是 Private Aggregation API 而异。
如需详细了解如何为每个 API 设置贡献预算,请参阅以下 API 文档部分:
报告批处理策略
批量处理可汇总的报告时,请务必优化批处理策略,以免超出隐私权限制。正确批量处理报告时,需要了解两个重要概念,即“无重复”规则和不相交批次。
“禁止重复”规则
汇总服务会强制执行“禁止重复”规则。此规则规定,可汇总的报告(通过 report_id 进行唯一标识)在单个批次中只能出现一次。如果可汇总的报告在每个批次中出现多次,则第一个报告会包含在汇总中,随后具有相同 report_id 的报告会被舍弃,并且批处理会成功完成。
该规则还规定,同一共享 ID 不能出现在多批中。如果某个共享 ID 已包含在之前成功的批次中,则后续批次中也包含该共享 ID 时,该批次将会失败。
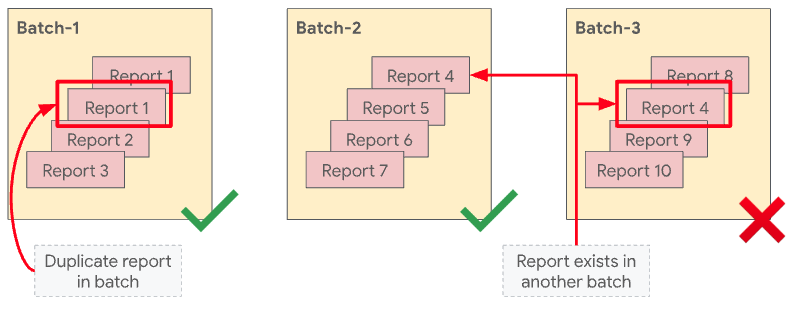
如果不使用“无重复”规则,攻击者可以通过在一个或多个批次中添加报告的副本来操纵批次内容,从而深入了解特定批次的内容。
如需详细了解如何在一批报告中或跨多批报告强制执行“无重复”规则,请参阅批量报告中的重复报告。
不相交的批次
为避免批次之间出现重叠的情况,汇总服务会强制执行不重叠的批次。也就是说,两个或更多批次中不能包含共用相同共享 ID 的报告。共享 ID 是从可汇总报告的 shared_info 字段收集的数据以及作业请求中的过滤 ID 的组合。如果未指定过滤 ID,则使用默认值 0。
在以下 shared_info 字段示例中,您可以看到 API、attribution_destination(适用于归因报告)、reporting_origin、scheduled_report_time、source_registration_time(适用于归因报告)和 version。这些字段(report_id 除外)以及作业请求中的过滤 ID 都会贡献到共享 ID。
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://privacy-sandbox-demos-shop.dev",
"report_id": "5b052748-f5fb-4f14-b291-de03484ed59e",
"reporting_origin": "https://privacy-sandbox-demos-dsp.dev",
"scheduled_report_time": "1707786751",
"source_registration_time": "0",
"version": "0.1"
}
由于 source_registration_time 按天截断,而 scheduled_report_time 按小时截断,因此有些报告具有相同的共享 ID。在此示例中,Report1 和 Report2 具有共享的信息字段。这两份报告具有相同的 API 版本 attribution_destination、reporting_origin 和 source_registration_time。由于 report_id 不是共享 ID 的一部分,因此您可以忽略此差异。
在以下示例中,Report1 和 Report2 的 scheduled_report_time 值相同。
Report1 分享的信息:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Report2 共享的信息:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Report1 的定期生成时间为“2024 年 2 月 19 日晚上 9:08:10”,Report2 的定期生成时间为“2024 年 2 月 19 日晚上 9:55:10”。由于 scheduled_report_time 字段的值会截断到小时级别,因此这两份报告的 scheduled_report_time 字段值均为 1708376890(“2024 年 2 月 19 日晚上 9 点”的编码值)。
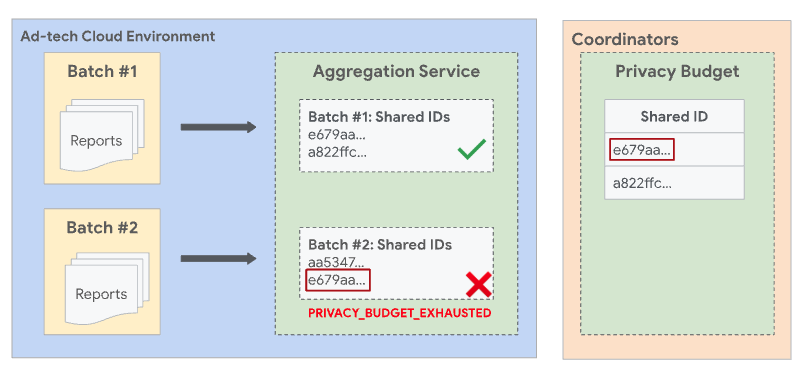
由于所有其他字段和过滤 ID 都相同,因此这两份报告具有相同的共享 ID。由于这两份报告具有相同的共享 ID,因此必须包含在同一批次中。
如果 Report1 在之前成功的批次中进行批处理,而 Report2 在后续批次中进行处理,则包含 Report2 的批次会失败并返回 PRIVACY_BUDGET_EXHAUSTED 错误。如果出现这种情况,请移除之前已成功批量处理且具有共享 ID 的报告,然后重试。如需详细了解此错误,请参阅汇总服务的错误代码和缓解措施。
预声明的汇总键
向汇总服务提交批量时,该批量必须同时包含从报告来源收到的可汇总报告和输出网域文件。输出网域包含从可汇总报告中检索到的键(即存储分区)。
从隐私保护的角度来看,系统会向输出网域中预声明的所有键添加噪声,即使没有真实报告与特定键匹配也是如此。指定输出网域可防范以下攻击:输出中存在键会泄露单个用户或事件的相关信息。例如,如果您只向一位用户展示了广告系列,那么在输出中收到键即表示该用户日后完成了转化,即使添加了噪声也是如此。通过先指定此网域,您可以确保该网域不会泄露任何与用户贡献相关的信息。
您可以在 Attribution Reporting API 或 Private Aggregation API 中声明这些 128 位键,并使用它们对要跟踪的维度进行编码。
系统仅会考虑预声明的键进行汇总,并将其纳入摘要报告中。摘要报告中分桶的汇总值会添加统计噪声,这会反映在创建的摘要报告中。
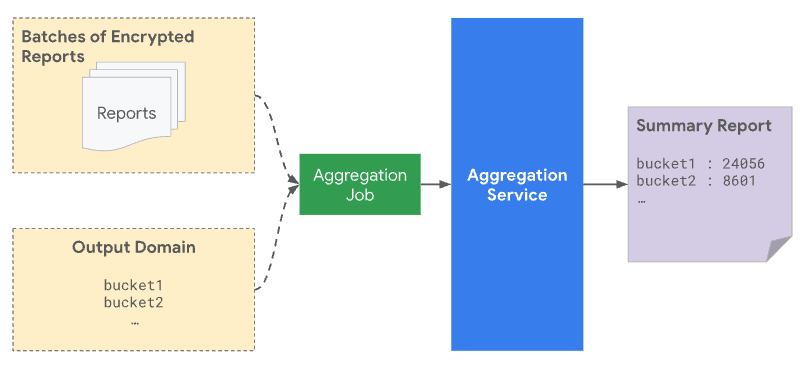
如果输出网域文件中包含汇总键,但该键不在批量报告中,那么即使汇总值为零,最终摘要报告也可能不为零,因为系统会添加噪声来保护隐私。