成功部署汇总服务后,您可以使用 createJob 和 getJob 端点与该服务交互。下图直观呈现了这两个端点的部署架构:
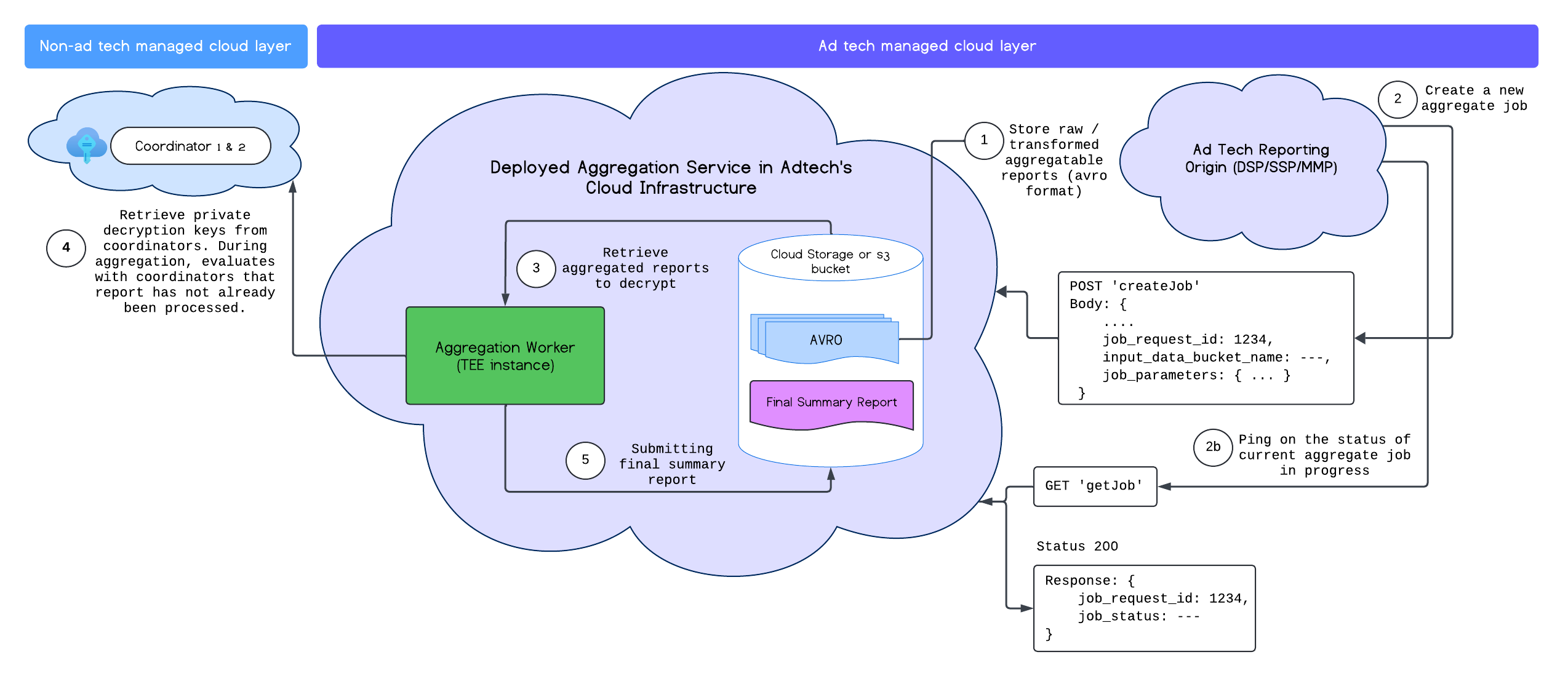
如需详细了解 createJob 和 getJob 端点,请参阅汇总服务 API 文档。
创建作业
如需创建作业,请向 createJob 端点发送 POST 请求。bash
POST https://<api-gateway>/stage/v1alpha/createJob
-+
createJob 请求正文示例:
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
成功创建作业会导致 HTTP 状态代码为 202。
请注意,reporting_site 和 attribution_report_to 是互斥的,只需使用其中一个即可。
您还可以通过将 debug_run 添加到 job_parameters 中来请求调试作业。如需详细了解调试模式,请参阅我们的汇总调试运行文档。
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
请求字段
| 参数 | 类型 | 说明 |
|---|---|---|
job_request_id |
字符串 |
这是广告技术平台生成的唯一标识符,应采用 ASCII 字母,且不得超过 128 个字符。这会标识批量作业请求,并从托管在广告技术平台的云端存储空间上 `input_data_bucket_name` 中指定的输入存储分区中提取 `input_data_blob_prefix` 中指定的所有可汇总的 AVRO 报告。
字符数: `a-z, A-Z, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~
|
input_data_blob_prefix |
字符串 |
这是存储分区路径。对于单个文件,您可以使用路径。对于多个文件,您可以在路径中使用前缀。
示例:文件夹/文件会收集 folder/file1.avro、folder/file/file1.avro 和 folder/file1/test/file2.avro 中的所有报告。 |
input_data_bucket_name |
字符串 | 这是输入数据或可汇总报告的存储分区。此数据位于广告技术平台的云端存储空间中。 |
output_data_blob_prefix |
字符串 | 这是存储分区中的输出路径。支持单个输出文件。 |
output_data_bucket_name |
字符串 |
这是发送 output_data 的存储分区。此数据存储在广告技术平台的云端存储空间中。
|
job_parameters |
字典 |
必填字段。此字段包含不同的字段,例如:
|
job_parameters.output_domain_blob_prefix |
字符串 |
与 input_data_blob_prefix 类似,这是 output_domain_bucket_name 中输出域名 AVRO 所在的路径。对于多个文件,您可以在路径中使用前缀。汇总服务完成批处理后,系统会创建摘要报告并将其放入名称为 output_data_blob_prefix 的输出存储分区 output_data_bucket_name 中。
|
job_parameters.output_domain_bucket_name |
字符串 | 这是输出网域 AVRO 文件的存储分区。此数据位于广告技术平台的云端存储空间中。 |
job_parameters.attribution_report_to |
字符串 | 此值与 `reporting_site` 互斥。这是收到报告的报告网址或报告来源。网站来源是在汇总服务初始配置中注册的。 |
job_parameters.reporting_site |
字符串 |
与 attribution_report_to 相互排斥。这是收到报告的报告网址或报告来源的主机名。网站来源是在汇总服务初始配置中注册的。
注意:您可以在单个请求中提交多个具有不同来源的报告,前提是所有来源都属于此参数中指定的同一报告网站。
|
job_parameters.debug_privacy_epsilon |
浮点数,双精度 | 可选字段。如果未传递任何值,则默认值为 10。可以使用 0 到 64 之间的值。 |
job_parameters.report_error_threshold_percentage |
双精度 | 可选字段。这是在作业失败之前允许的失败报告百分比上限。如果留空,则默认值为 10%。 |
job_parameters.input_report_count |
长值 |
可选字段。作为作业输入数据提供的报告总数。将此值与 report_error_threshold_percentage 结合使用可在报告因错误而被排除时提前让作业失败。
|
job_parameters.filtering_ids |
字符串 |
可选字段。以英文逗号分隔的无符号过滤 ID 列表。除匹配的过滤 ID 之外,所有其他贡献都会被滤除。(例如 "filtering_ids": "12345,34455,12")。默认值为 0。
|
job_parameters.debug_run |
布尔值 |
可选字段。执行调试运行时,系统会添加带噪声和不带噪声的调试摘要报告和注释,以指明网域输入和/或报告中存在哪些键。此外,系统也不会强制执行批处理中的重复项。请注意,调试运行仅会考虑具有标志 "debug_mode": "enabled" 的报告。从 v2.10.0 开始,调试运行不会消耗隐私预算。
|
获取作业
当广告技术平台想要了解所请求批次的状态时,可以调用 getJob 端点。使用 HTTPS GET 请求和 job_request_id 参数调用 getJob 端点。
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
您应该会收到一个响应,其中会返回作业状态以及所有错误消息:
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
响应字段
| 参数 | 类型 | 说明 |
|---|---|---|
job_request_id |
字符串 |
这是 createJob 请求中指定的唯一作业/批处理 ID。
|
job_status |
字符串 | 这是作业请求的状态。 |
request_received_at |
字符串 | 收到请求的时间。 |
request_updated_at |
字符串 | 作业上次更新的时间。 |
input_data_blob_prefix |
字符串 |
这是在 createJob 中设置的输入数据前缀。
|
input_data_bucket_name |
字符串 |
这是广告技术平台的输入数据存储分区,用于存储可汇总报告。此字段设置为 createJob。
|
output_data_blob_prefix |
字符串 |
这是在 createJob 中设置的输出数据前缀。
|
output_data_bucket_name |
字符串 |
这是广告技术平台的输出数据存储分区,用于存储生成的摘要报告。此字段设置为 createJob。
|
request_processing_started_at |
字符串 |
最新一次处理尝试的开始时间。不包括在作业队列中等待的时间。
(总处理时间 = request_updated_at - request_processing_started_at)
|
result_info |
字典 |
这是 createJob 请求的结果,包含所有可用信息。
这会显示 return_code、return_message、finished_at 和 error_summary 值。
|
result_info.return_code |
字符串 | 作业结果返回代码。如果汇总服务出现问题,我们需要这些信息来排查问题。 |
result_info.return_message |
字符串 | 作业执行结果返回的成功或失败消息。如需排查汇总服务问题,您也需要提供这些信息。 |
result_info.error_summary |
字典 | 从作业返回的错误。其中包含报告数量以及遇到的错误类型。 |
result_info.finished_at |
时间戳 | 指示作业完成时间戳。 |
result_info.error_summary.error_counts |
列表 |
这会返回错误消息列表,以及出现相同错误消息的失败报告数量。每个错误计数都包含一个类别、error_count 和 description。
|
result_info.error_summary.error_messages |
列表 | 这会返回报告处理失败时出现的错误消息列表。 |
job_parameters |
字典 |
其中包含 createJob 请求中提供的作业参数。相关属性,例如 `output_domain_blob_prefix` 和 `output_domain_bucket_name`。
|
job_parameters.attribution_report_to |
字符串 |
与 reporting_site 相互排斥。这是报告网址或收到报告的来源。来源是指在汇总服务初始配置中注册的网站的一部分。这在 createJob 请求中指定。
|
job_parameters.reporting_site |
字符串 |
与 attribution_report_to 相互排斥。这是报告网址的主机名,或收到报告的来源。来源是指在汇总服务初始配置中注册的网站的一部分。请注意,您可以在同一请求中提交包含多个报告来源的报告,前提是所有报告来源都属于此参数中提及的同一网站。这在 createJob 请求中指定。此外,请确保该存储分区在作业创建时仅包含您要汇总的报告。系统会处理添加到输入数据存储分区中的所有报告,前提是报告来源与作业参数中指定的报告网站相匹配。
汇总服务仅会考虑与作业的已注册报告来源匹配的数据分桶中的报告。例如,如果注册的来源是 https://exampleabc.com,则仅包含来自 https://exampleabc.com 的报告,即使存储分区包含来自子网域 (https://1.exampleabc.com 等) 或完全不同网域 (https://3.examplexyz.com) 的报告也是如此。
|
job_parameters.debug_privacy_epsilon |
浮点数,双精度 |
可选字段。如果未传递任何值,则使用默认值 10。值介于 0 到 64 之间。此值在 createJob 请求中指定。
|
job_parameters.report_error_threshold_percentage |
双精度 |
可选字段。这是在作业失败之前可以失败的报告的阈值百分比。如果未指定任何值,则使用默认值 10%。这在 createJob 请求中指定。
|
job_parameters.input_report_count |
长值 | 可选字段。作为此作业的输入数据提供的报告的总数。如果由于错误而排除了大量报告,则 `report_error_threshold_percentage` 与此值结合使用会触发作业提前失败。此设置在 `createJob` 请求中指定。 |
job_parameters.filtering_ids |
字符串 |
可选字段。以英文逗号分隔的未签名过滤 ID 列表。除匹配的过滤 ID 之外,所有其他贡献都会被滤除。这在 createJob 请求中指定。
(例如 "filtering_ids":"12345,34455,12"。默认值为“0”。)
|