Usługa agregacji generuje raporty podsumowujące szczegółowe dane o konwersjach i danych dotyczących zasięgu na podstawie nieprzetworzonych raportów podlegających agregacji. Jako dostawca technologii reklamowej możesz używać interfejsów Attribution Reporting API i Private Aggregation API, które są 2 głównymi punktami wejścia po stronie klienta, aby przekazywać raporty do usługi agregacji i otrzymywać w odpowiedzi raporty podsumowujące.
Na tej stronie zakładamy, że jesteś doświadczonym specjalistą ds. technologii reklamowych. Tutaj znajdziesz informacje o:
- Stan implementacji
- Kluczowe terminy i pojęcia
- Przypadki użycia agregacji
- Cały proces
- Przesyłanie zbiorcze raportów możliwych do zsumowania
- Elementy w chmurze
Stan wdrożenia
- Usługa agregacji jest teraz ogólnie dostępna.
- Usługa agregacji może być używana z interfejsem Attribution Reporting API i interfejsem Private Aggregation API w przypadku interfejsu Protected Audience API i interfejsu Shared Storage API.
Dostępność
| 提案 | 状态 |
|---|---|
| 跨云隐私预算服务
说明 |
可用 |
| 针对 Attribution Reporting API、Private Aggregation API 中的 Amazon Web Services (AWS) 提供汇总服务支持
说明 |
可用 |
| 针对 Attribution Reporting API、Private Aggregation API 的 Google Cloud 汇总服务支持 说明 |
可用 |
| 汇总服务网站注册和多源汇总。网站注册包括将网站映射到云账号(AWS 或 GCP)。如需汇总多个来源,这些来源必须属于同一网站。
GitHub 上的常见问题解答 Site aggregation API 文档 |
可用 |
| 汇总服务的 epsilon 值将保持在 64 以内的范围内,以便对不同的参数进行实验和反馈。
提交 ARA 小数值反馈。 提交 PAA 小样本误差反馈。 |
可用。在更新 epsilon 范围值之前,我们会提前通知生态系统。 |
| 为汇总服务查询提供了更灵活的贡献过滤功能
解说 |
可用 |
| 灾难发生后(错误、配置错误等)预算恢复流程
说明 |
可用 机制,用于查看广告技术平台使用预算恢复功能恢复的共享 ID 的百分比,并暂停计划在 2025 年上半年过度恢复的未来恢复 |
| Accenture 是 AWS 协调者之一
开发者博客 |
可用 |
| 作为 Google Cloud 协调者之一的独立方
开发者博客 |
可用 |
| 汇总服务对 Attribution Reporting API 上的汇总调试报告的支持
说明 |
可用 |
Kluczowe terminy i pojęcia
Jeśli rozważasz użycie usługi agregacji w swoim procesie, poniższe terminy i pojęcia mogą pomóc Ci zrozumieć, co nowy proces agregacji może dać Twojemu zespołowi.
Słowniczek terminów
- Raporty zbiorcze
-
可汇总的报告是从单个用户设备发送的经过加密的报告。这些报告包含有关跨网站用户行为和转化的数据。转化(有时称为归因触发器事件)和相关指标由广告客户或广告技术平台定义。每个报告均已加密,以防止各方访问底层数据。
- Uwzględnianie raportów zbiorczych
-
分布式账本,位于两个协调者中,用于跟踪分配的隐私预算并强制执行“无重复”规则。这是位于协调器中并在其中运行的隐私保护机制,可确保没有任何报告在通过汇总服务时超出分配的隐私预算。
- Budżet rozliczeniowy raportu zbiorczego
-
对预算的引用,用于确保不会对单个报告进行多次处理。
- Usługa do agregacji
-
由广告技术平台运营的服务,用于处理可汇总报告以创建摘要报告。
- Potwierdzenie
-
一种用于对软件身份进行身份验证的机制,通常使用加密哈希或签名。对于汇总服务提案,认证会将广告技术平台运营的汇总服务中运行的代码与开源代码进行匹配。
- Contribution Bonding
- Koordynator
-
负责密钥管理和汇总报告会计核算的实体。协调者会维护已获批准的汇总服务配置的哈希列表,并配置对解密密钥的访问权限。
- Szum i skalowanie
-
Statistical noise that is added to summary reports during the aggregation process to preserve privacy and ensure the final reports provide anonymized measurement information.
Read more about additive noise mechanism, which is drawn from Laplace distribution.
- Źródło raportu
-
接收可汇总报告的实体,也就是您或调用了 Attribution Reporting API 的广告技术平台。可汇总的报告会从用户设备发送到与报告来源关联的知名网址。报告来源是在注册期间指定的。
- Shared ID
-
计算值,由
shared_info、reporting_origin、destination_site(仅限 Attribution Reporting API)、source_registration-time(仅限 Attribution Reporting API)、scheduled_report_time和版本组成。如果多个报告在
shared_info字段中具有相同的属性,则应具有相同的共享 ID。共享 ID 在可汇总报告的会计核算中发挥着重要作用。 - Raport zbiorczy
-
Typ raportu interfejsów Attribution Reporting API i Private Aggregation API. Raport podsumowania zawiera zagregowane dane o użytkownikach i może zawierać szczegółowe dane o konwersjach z dodanym szumem. Raporty podsumowujące składają się z raportów zbiorczych. Zapewniają one większą elastyczność i bogatszy model danych niż raportowanie na poziomie zdarzenia, co jest szczególnie przydatne w przypadku niektórych zastosowań, np. wartości konwersji.
- Zaufane środowisko wykonawcze (TEE)
-
计算机硬件和软件的安全配置,可让外部方验证机器上运行的软件的确切版本,而无需担心信息泄露。通过 TEE,外部方可以确认软件的行为和功能与其制造商声称的完全一致,不多不少。
如需详细了解用于 Privacy Sandbox 方案的 TEE,请参阅 Protected Audience API 服务说明文档和汇总服务说明文档。
Przypadki użycia agregacji
Zapoznaj się z tymi ścieżkami dla programistów dotyczącymi pomiaru reklam i odpowiednimi bibliotekami klienta pomiarów.
| Przypadek użycia | Punkt wejścia | Opis |
|---|---|---|
| Optymalizacja stawek | Attribution Reporting API (Chrome i Android) | Korzystaj z raportów zbiorczych, aby pozyskiwać sygnały konwersji na potrzeby optymalizacji stawek. |
| Pomiar na różnych platformach | Attribution Reporting API (Chrome i Android) | Korzystaj z możliwości pomiaru skuteczności w internecie i aplikacjach, aby mieć wgląd w wyniki w Chrome i na Androidzie. |
| Raporty o konwersjach | Attribution Reporting API (Chrome i Android) | tworzenie raportów o konwersjach zbiorczych dostosowanych do potrzeb kampanii klientów (w tym CTC i VTC); |
| Pomiar zasięgu kampanii | Shared Storage API i Private Aggregation API (Chrome) | Używaj zmiennych widoku reklamy w wielu witrynach do pomiaru zasięgu kampanii. |
| Raportowanie danych demograficznych | Shared Storage API i Private Aggregation API (Chrome) | Używaj danych o wyświetleniach reklam w wielu witrynach i danych demograficznych do pomiaru zasięgu według danych demograficznych. |
| Analiza ścieżki konwersji | Shared Storage API i Private Aggregation API (Chrome) | Przechowuj zmienne widoku reklamy w wielu witrynach i konwersji, aby przeprowadzać zbiorczą analizę ścieżki konwersji. |
| Wyniki marki i zwiększenie liczby konwersji | Shared Storage API i Private Aggregation API (Chrome) | Raportowanie dotyczące grup testowych i kontrolnych oraz informacji o głosowaniu na potrzeby pomiaru wzrostu skuteczności marki i przyrostu wartości. |
| Debugowanie aukcji | Protected Audience API & Private Aggregation API (Chrome) | Korzystaj z raportów zbiorczych na potrzeby debugowania. |
| Rozkład stawek | Protected Audience API & Private Aggregation API (Chrome) | Korzystaj z raportów zbiorczych, aby rejestrować rozkład wartości stawek w aukcjach. |
Cały proces
Poniższy diagram pokazuje działanie usługi agregacji. Skupimy się na pełnym procesie, od momentu otrzymania raportów z internetu i urządzeń mobilnych do momentu utworzenia raportu podsumowania w usłudze agregacji.
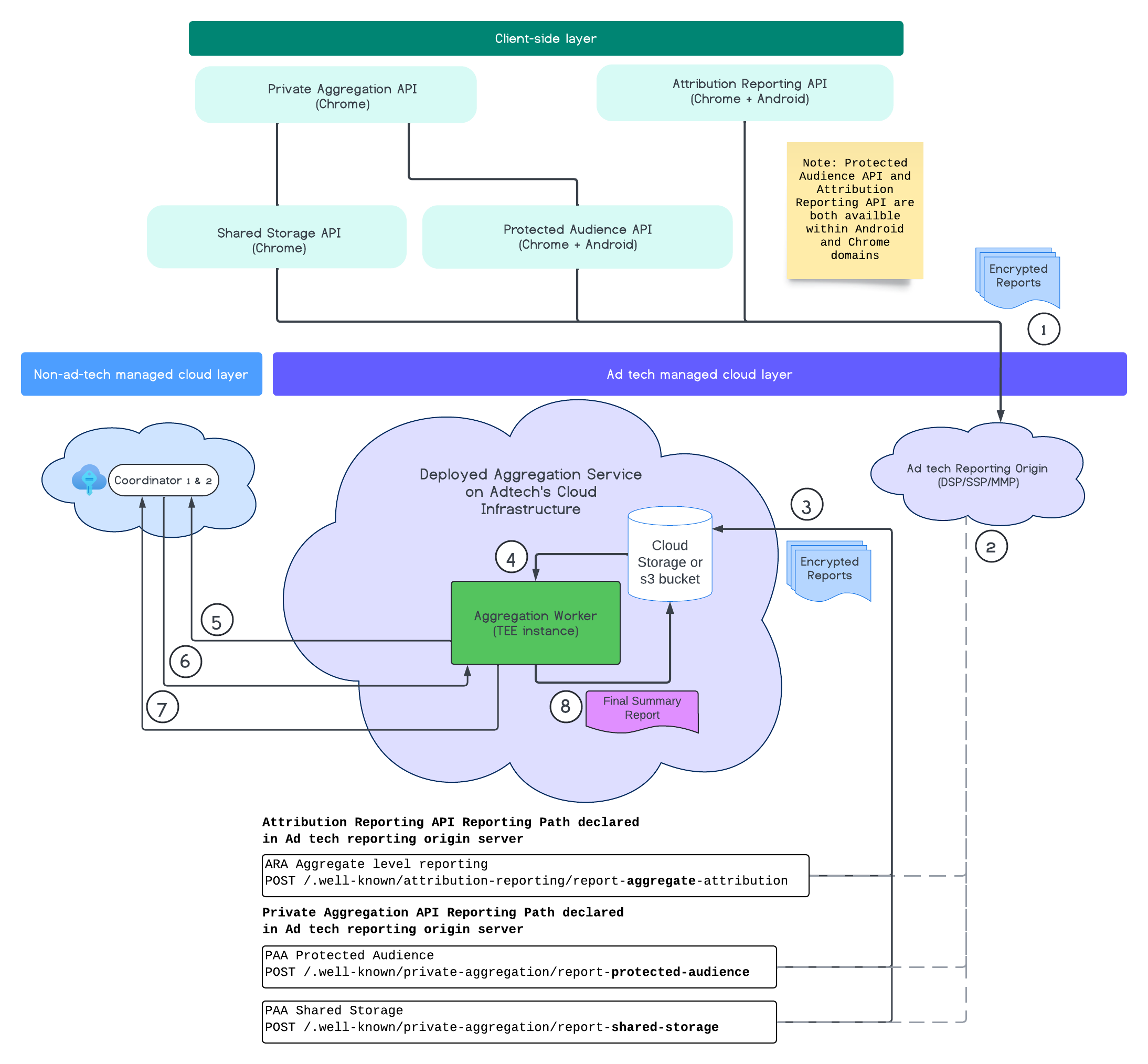
- Pobierz klucz publiczny, aby generować zaszyfrowane raporty.
- Zaszyfrowane raporty podlegające agregacji są wysyłane na serwery technologii reklamowych w celu zebrania, przekształcenia i zbiorowego przetwarzania.
- Serwer adtech grupowo wysyła raporty (w formacie avro) do usługi agregacji. (musisz to zrobić).
- Pracownik agregacji pobiera zagregowane raporty do odszyfrowania.
- Pracownik agregacji pobiera klucze odszyfrowywania od koordynatora.
- Proces agregacji odszyfrowuje raporty na potrzeby agregacji i dodawania szumu.
- Usługa księgowania raportów podlegających agregacji sprawdza, czy jest wystarczający budżet na ochronę prywatności, aby wygenerować raport podsumowania dla podanych raportów podlegających agregacji.
- Prześlij końcowy raport podsumowujący.
Diagram pokazuje ogólne relacje usługi agregacji z głównymi interfejsami API pomiaru klienta: Attribution Reporting API, Private Aggregation API i koordynatorami.
Proces rozpoczyna się od interfejsów API służących do pomiarów, takich jak Attribution Reporting API czy Private Aggregation API, które generują raporty z wielu instancji przeglądarki. Chrome pobiera klucz publiczny z usługi hostingu kluczy w koordynatorze, aby szyfrować raporty przed ich wysłaniem do źródła raportowania technologii reklamowych. Klucze publiczne są poddawane rotacji co 7 dni.
Źródło raportowania technologii reklamowych powinno być skonfigurowane tak, aby zbierać i konwertować przychodzące raporty do formatu avro oraz wysyłać je do usługi agregacji zgodnie z opisem w sekcji Strategie przetwarzania partii danych.
Gdy masz gotową partię, wysyłasz do usługi agregacji żądanie zbiorcze. Usługa agregacji pobiera klucze odszyfrowywania z usługi hostingu kluczy, odszyfrowuje raporty, a następnie agreguje je i zaciemnia, aby utworzyć raport podsumowujący. Pamiętaj, że zależy to od tego, czy masz wystarczający budżet na ochronę prywatności.
Usługa zbierania danych o technologiach reklamowych hostowana jest w chmurze dostawcy technologii reklamowych, gdzie są zbierane raporty, a usługa agregacji jest wdrażana w chmurze dostawcy technologii reklamowych.
grupowanie raportów zbiorczych.
Proces raportowania nie byłby kompletny bez pomocy wyznaczonego serwera źródłowego raportowania. To jest pochodzenie, które zostało przesłane w trakcie procesu rejestracji. Źródło raportów odpowiada za zbieranie, przekształcanie i grupowanie otrzymanych raportów podlegających agregacji oraz przygotowanie ich do wysłania do usługi agregacji w Google Cloud lub Amazon Web Services. Dowiedz się więcej o przygotowywaniu raportów możliwych do zsumowania.
Teraz, gdy znasz już ogólną koncepcję, możemy przyjrzeć się bliżej komponentom wdrożonym w Twojej usłudze agregacji.
Komponenty Cloud
Usługa agregacji składa się z kilku komponentów usług w chmurze. Do tworzenia i konfigurowania wszystkich niezbędnych komponentów usługi w chmurze używasz dostarczonych skryptów Terraform.
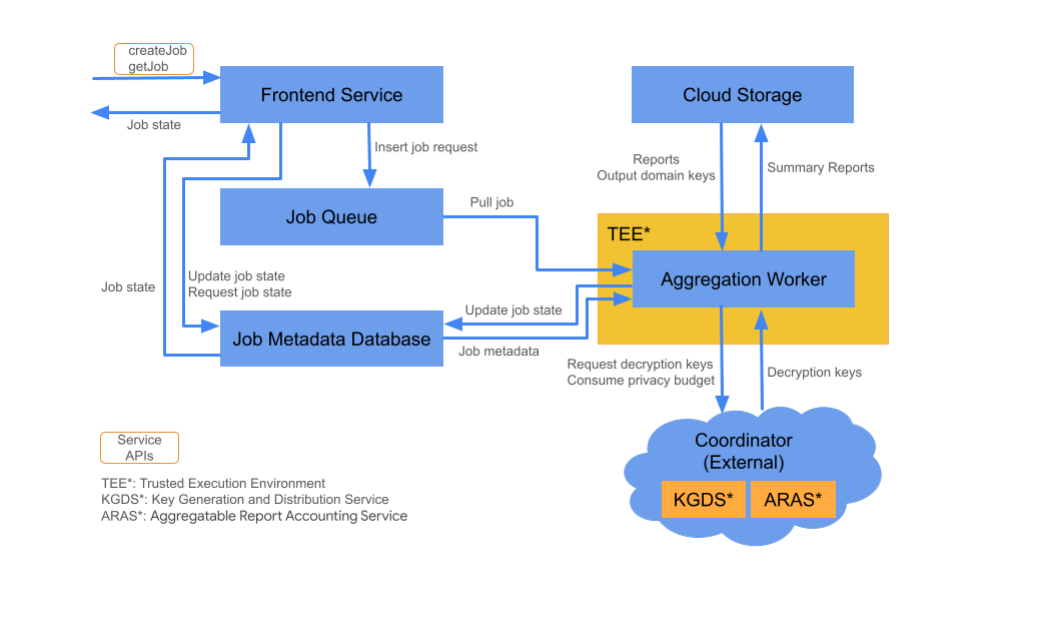
Usługa frontendu
Zarządzana usługa w chmurze: Cloud Function (Google Cloud) / API Gateway (Amazon Web Services)
Usługa frontendu to bezserwerowa brama, która jest głównym punktem wejścia do wywołań interfejsu Aggregation API służących do tworzenia zadań i pobierania stanu zadań. Odpowiada on za otrzymywanie żądań od użytkowników usługi agregacji, sprawdzanie parametrów wejściowych i inicjowanie procesu planowania zadania agregacji.
Usługa frontendu ma 2 dostępne interfejsy API:
| Punkt końcowy | Opis |
|---|---|
createJob |
Ten interfejs API uruchamia zadanie usługi do agregacji. Aby uruchomić zadanie, musisz podać takie informacje, jak identyfikator zadania, szczegóły miejsca docelowego danych wejściowych, szczegóły miejsca docelowego danych wyjściowych i źródło raportowania. |
getJob |
Ten interfejs API zwraca stan zadania o określonym identyfikatorze. Zawiera informacje o stanie zadania, takie jak „Otrzymano”, „W toku” lub „Ukończono”. Jeśli zadanie zostało ukończone, zwraca też jego wynik, w tym komunikaty o błędach, które wystąpiły podczas jego wykonywania. |
Zapoznaj się z dokumentacją interfejsu API usługi do agregacji.
Kolejka zadań
Zarządzana usługa w chmurze: Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services).
Kolejka zadań to kolejka wiadomości zawierająca żądania zadań dotyczące usługi agregacji. Usługa frontendu wstawia żądania zadań do kolejki, które są następnie wykorzystywane przez pracowników agregacji, którzy je przetwarzają.
Cloud Storage
Zarządzana usługa w chmurze: Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services).
Pliki wejściowe i wyjściowe używane przez usługę agregacji, takie jak zaszyfrowane pliki raportów i raporty podsumowania wyjściowego, są przechowywane w chmurze.
Baza danych metadanych zadania
Zarządzana usługa w chmurze: Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
Baza danych metadanych zadań służy do przechowywania stanu zadań agregacji i śledzenia go. Zapisywanie metadanych, takich jak czas utworzenia, czas zgłoszenia, czas aktualizacji i stan (np. Otrzymano, W toku lub Gotowe). Instancje robocze agregacji aktualizują bazę danych metadanych zadań w miarę wykonywania zadań.
Zasób roboczy agregacji
Zarządzana usługa w chmurze: Compute Engine z Confidential space (Google Cloud) lub Amazon Web Services EC2 z Nitro Enclave (Amazon Web Services).
Pracownik agregacji przetwarza żądania zadań w kole zadań i odszyfrowuje zaszyfrowane dane wejściowe za pomocą kluczy pobieranych z usługi Key Generation and Distribution Service (KGDS) w koordynatorze. Aby zminimalizować opóźnienia w przetwarzaniu zadań, instancje robocze agregacji przechowują klucze odszyfrowywania w pamięci podręcznej przez 8 godzin i używają ich w ramach przetwarzanych zadań.
Procesy agregacji działają w środowisku Trusted Execution Environment (TEE). Worker obsługuje tylko jedno zadanie naraz. Możesz skonfigurować wiele instancji roboczych do przetwarzania zadań równolegle, ustawiając konfigurację automatycznego skalowania. Jeśli jest używane, autoskalowanie dynamicznie dostosowuje liczbę instancji roboczych do liczby wiadomości w kolejce zadań. Minimalną i maksymalną liczbę instancji roboczych do automatycznego skalowania możesz skonfigurować w pliku środowiska Terraform. Więcej informacji o autoskalowaniu znajdziesz w tych skryptach Terraform: Amazon Web Services lub Google Cloud.
Procesy robocze agregacji wywołują usługę księgowania raportów agregacji w celu księgowania raportów agregacji. Ta usługa zapewnia, że zadania są wykonywane tylko wtedy, gdy nie przekroczono limitu budżetu prywatności. (zobacz regułę „Brak duplikatów”). Jeśli budżet jest dostępny, na podstawie zbiorczych danych o wysokiej zmienności jest generowany raport podsumowujący. Dowiedz się więcej o rachunkowości w raportach możliwych do zsumowania.
Pracownicy agregacji aktualizują metadane zadań w bazie danych metadanych zadań. Te informacje obejmują kody zwrotu zadań i liczniki błędów raportów w przypadku częściowych błędów raportów. Użytkownicy mogą pobrać stan za pomocą interfejsu getJob job state retrieval API.
Szczegółowe informacje o usłudze agregacji znajdziesz w tym artykule.
Dalsze kroki
Po zapoznaniu się z najważniejszymi informacjami o usłudze agregacji możesz wdrożyć własny jej egzemplarz w Google Cloud lub Amazon Web Services. Aby dowiedzieć się więcej o działaniach związanych z usługą agregacji, zapoznaj się z sekcją „Pierwsze kroki” lub kliknij ten link.
Rozwiązywanie problemów
Szczegółowe opisy komunikatów o błędach, informacje o możliwych przyczynach ich występowania oraz dalsze kroki, które należy podjąć, aby je rozwiązać, znajdziesz w dokumentacji Częste kody błędów i sposoby ich rozwiązania.
Uzyskiwanie pomocy i przesyłanie opinii
- Aby zadać pytanie o usługę, przekazać opinię lub zgłosić prośbę o dodanie funkcji, utwórz zgłoszenie w naszym repozytorium GitHub.
- Jeśli podczas wdrażania, utrzymywania lub wykonywania zadań za pomocą usługi agregacji wystąpił błąd, możesz poprosić o pomoc techniczną, korzystając z tego formularza.
- Sprawdź panel stanu usługi Google Analytics, aby dowiedzieć się, czy wystąpiły znane problemy.