El servicio de agregación genera informes de resumen de datos de conversiones detallados y mediciones de alcance a partir de informes agregables sin procesar. Como tecnología publicitaria, puedes usar la API de Attribution Reporting y la API de Private Aggregation, los dos principales puntos de entrada agregados del cliente, para canalizar informes al servicio de agregación y recibir un informe de resumen como respuesta.
En esta página, se supone que tienes experiencia en tecnología publicitaria. Aquí se incluye lo siguiente:
- Estado de implementación
- Términos y conceptos clave
- Casos de uso de agregación
- Flujo de extremo a extremo
- Aggregatable reports batching
- Componentes de Cloud
Estado de implementación
- El servicio de agregación ahora tiene disponibilidad general.
- El servicio de agregación se puede usar con la API de Attribution Reporting y la API de Private Aggregation para la API de Protected Audience y la API de Shared Storage.
Disponibilidad
| Propuesta | Estado |
|---|---|
| Servicio de presupuesto de privacidad entre nubes
Explicación |
Disponible |
| Compatibilidad del servicio de agregación con Amazon Web Services (AWS) en la API de Attribution Reporting y la API de Private Aggregation
Explicación |
Disponible |
| Compatibilidad del servicio de agregación con Google Cloud en la API de Attribution Reporting y la API de Private Aggregation Explicación |
Disponible |
| Inscripción de sitios del servicio de agregación y agregación de varios orígenes La inscripción de sitios incluye la asignación de un sitio a cuentas de nube (AWS o GCP). Para agregar varios orígenes, deben ser del mismo sitio.
Preguntas frecuentes en GitHub Documentación de la API de agregación de sitios |
Disponible |
| El valor de epsilon del servicio de agregación se mantendrá como un rango de hasta 64 para facilitar la experimentación y los comentarios sobre diferentes parámetros.
Envía comentarios sobre epsilon de ARA. Envía comentarios sobre la PAA. |
Disponible. Enviaremos un aviso anticipado al ecosistema antes de que se actualicen los valores del rango de epsilon. |
| Filtrado de contribuciones más flexible para las consultas del servicio de agregación
Explicación |
Disponible |
| Proceso para la recuperación del presupuesto después de desastres (errores, parámetros de configuración incorrectos, etcétera)
Explicación |
Disponible Mecanismo para revisar el porcentaje de IDs compartidos que recupera una tecnología publicitaria mediante la recuperación del presupuesto y suspender las recuperaciones futuras para recuperaciones excesivas planificadas para el 1ᵉʳ semestre de 2025 |
| Accenture opera como uno de los coordinadores en AWS
Blog para desarrolladores |
Disponible |
| Es una parte independiente que opera como uno de los coordinadores en Google Cloud.
Blog para desarrolladores |
Disponible |
| Compatibilidad del servicio de agregación con los informes de depuración agregados en la API de Attribution Reporting
Explicación |
Disponible |
Términos y conceptos clave
Si estás considerando el servicio de agregación para tu flujo de trabajo, los siguientes términos y conceptos pueden brindarte información sobre lo que este nuevo flujo de agregación puede ofrecer a tu equipo.
Glosario de términos
- Informes agregables
-
Los informes agregables son informes encriptados que se envían desde dispositivos de usuarios individuales. Estos informes contienen datos sobre el comportamiento de los usuarios y las conversiones en varios sitios. El anunciante o la tecnología publicitaria definen las conversiones (a veces llamadas eventos activadores de atribución) y las métricas asociadas. Cada informe está encriptado para evitar que varias partes accedan a los datos subyacentes.
- Contabilidad de informes agregables
-
分布式账本,位于两个协调者中,用于跟踪分配的隐私预算并强制执行“无重复”规则。这是位于协调器中并在其中运行的隐私保护机制,可确保没有任何报告在通过汇总服务时超出分配的隐私预算。
- Presupuesto de la contabilización de informes agregables
-
对预算的引用,用于确保不会对单个报告进行多次处理。
- Servicio de agregación
-
Un servicio operado por tecnología publicitaria que procesa informes agregables para crear un informe de resumen.
Obtén más información sobre los antecedentes del Servicio de agregación en nuestra explicación y en la lista completa de condiciones.
- Certificación
-
Es un mecanismo para autenticar la identidad del software, por lo general, con hashes criptográficos o firmas. En el caso de la propuesta de servicio de agregación, la certificación coincide con el código que se ejecuta en tu servicio de agregación operado por la tecnología publicitaria con el código de código abierto.
- Unión de contribuciones
- Coordinador
-
负责密钥管理和汇总报告会计核算的实体。协调者会维护已获批准的汇总服务配置的哈希列表,并配置对解密密钥的访问权限。
- Ruido y escalamiento
-
Es el ruido estadístico que se agrega a los informes de resumen durante el proceso de agregación para preservar la privacidad y garantizar que los informes finales proporcionen información de medición anonimizada.
Obtén más información sobre el mecanismo de ruido aditivo, que se extrae de la distribución de Laplace.
- Origen de los informes
-
接收可汇总报告的实体,也就是您或调用了 Attribution Reporting API 的广告技术平台。可汇总的报告会从用户设备发送到与报告来源关联的知名网址。报告来源是在注册期间指定的。
- ID compartido
-
计算值,由
shared_info、reporting_origin、destination_site(仅限 Attribution Reporting API)、source_registration-time(仅限 Attribution Reporting API)、scheduled_report_time和版本组成。如果多个报告在
shared_info字段中具有相同的属性,则应具有相同的共享 ID。共享 ID 在可汇总报告的会计核算中发挥着重要作用。 - Informe de resumen
-
Attribution Reporting API 和 Private Aggregation API 报告类型。摘要报告包含汇总的用户数据,并且可能包含添加了噪声的详细转化数据。摘要报告由汇总报告组成。与事件级报告相比,这些报告具有更高的灵活性,并提供更丰富的数据模型,对于转化价值等某些用例尤其如此。
- Entorno de ejecución confiable (TEE)
-
计算机硬件和软件的安全配置,可让外部方验证机器上运行的软件的确切版本,而无需担心信息泄露。通过 TEE,外部方可以确认软件的行为和功能与其制造商声称的完全一致,不多不少。
如需详细了解用于 Privacy Sandbox 方案的 TEE,请参阅 Protected Audience API 服务说明文档和汇总服务说明文档。
Casos de uso de agregación
Ten en cuenta los siguientes recorridos de los desarrolladores para la medición de anuncios y sus bibliotecas cliente de medición correspondientes.
| Caso de uso | Punto de entrada | Descripción |
|---|---|---|
| Optimización de ofertas | API de Attribution Reporting (Chrome y Android) | Utiliza informes agregados para transferir indicadores de conversión con el objetivo de optimizar las ofertas. |
| Medición multiplataforma | API de Attribution Reporting (Chrome y Android) | Usa las capacidades de medición en múltiples plataformas web y de aplicaciones para obtener visibilidad del rendimiento en Chrome y Android. |
| Informes de conversiones | API de Attribution Reporting (Chrome y Android) | Crea informes de conversiones agregados adaptados a las necesidades de las campañas de los clientes (incluye las CTC y las VTC). |
| Medición del alcance de la campaña | API de Storage compartido y API de agregación privada (Chrome) | Usa las variables de vistas de anuncios entre sitios para medir el alcance de la campaña. |
| Informes demográficos | API de Storage compartido y API de agregación privada (Chrome) | Usa la información demográfica y las vistas de anuncios entre sitios para medir el alcance por datos demográficos. |
| Análisis de la ruta de conversión | API de Storage compartido y API de agregación privada (Chrome) | Almacena las variables de conversiones y vistas de anuncios entre sitios para realizar un análisis agregado de las rutas de conversión. |
| Efectividad de conversiones y de marca | API de Storage compartido y API de agregación privada (Chrome) | Informes sobre grupos de prueba y control, y sobre la información de sondeo para medir el aumento de la marca y la incrementalidad |
| Depuración de subastas | API de Protected Audience y API de Private Aggregation (Chrome) | Usa informes agregados para la depuración. |
| Distribución de ofertas | API de Protected Audience y API de Private Aggregation (Chrome) | Usa informes agregados para capturar la distribución de los valores de oferta de las subastas. |
Flujo de extremo a extremo
En el siguiente diagrama, se muestra el servicio de agregación en acción. Nos enfocaremos en el flujo de extremo a extremo desde el momento en que se reciben los informes de los dispositivos web y móviles hasta el momento en que se crea el informe de resumen en el servicio de agregación.
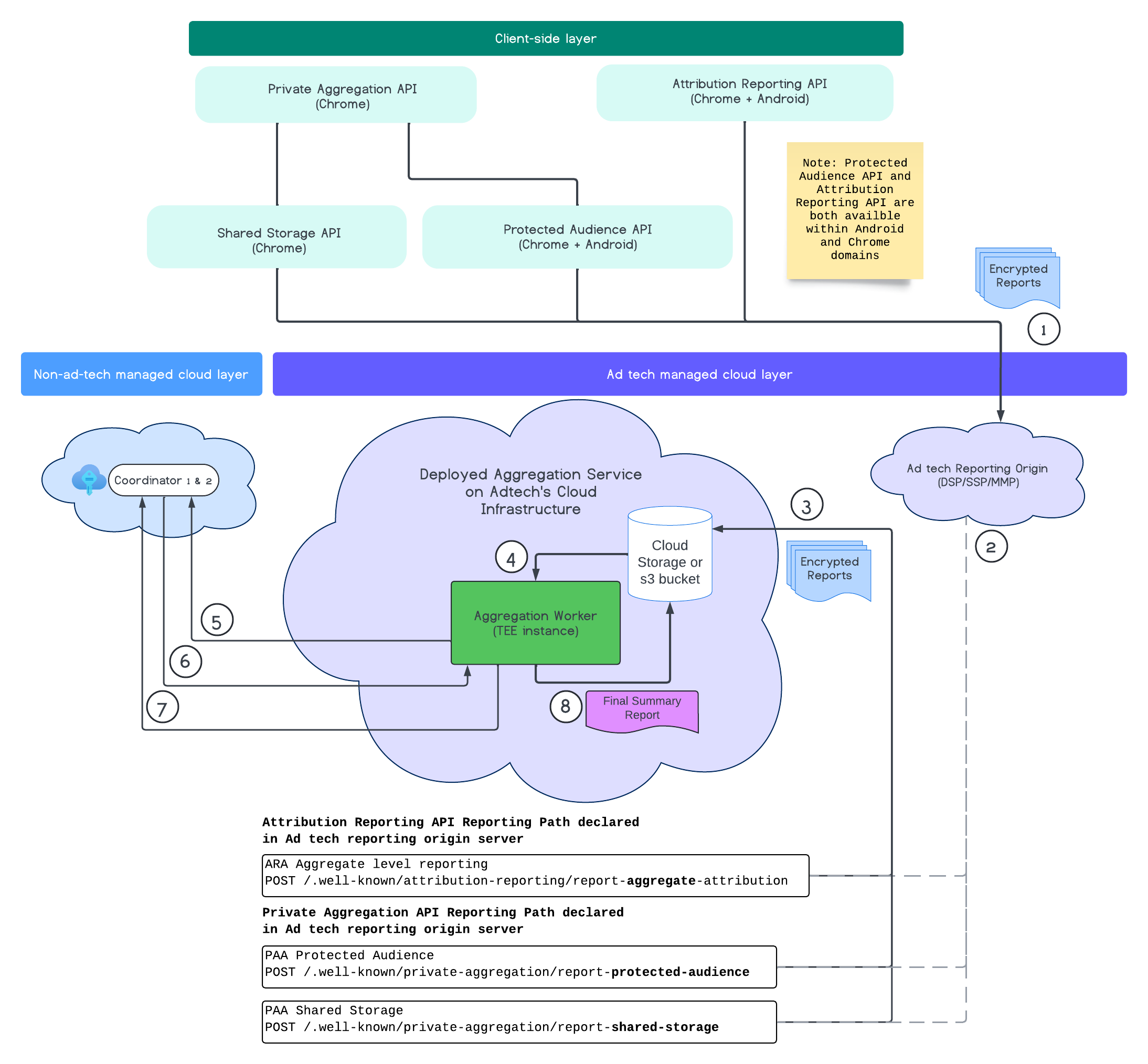
- Recupera la clave pública para generar informes encriptados.
- Los informes agregables encriptados se envían a los servidores de tecnología publicitaria para que se recopilen, transformen y agrupen.
- El servidor de tecnología publicitaria agrupa los informes (en formato Avro) y los envía al servicio de agregación. (Debes completar este paso).
- Un trabajador de agregación recupera los informes agregados para desencriptarlos.
- El trabajador de agregación recupera las claves de desencriptación de un coordinador.
- El trabajador de agregación desencripta los informes para la agregación y la contaminación.
- El servicio de contabilización de informes agregables verifica si hay suficiente presupuesto de privacidad para generar un informe de resumen de los informes agregables determinados.
- Envía un informe de resumen final.
En el diagrama, se muestran las relaciones de alto nivel que tiene el servicio de agregación con las principales APIs de medición de clientes: la API de Attribution Reporting, la API de Private Aggregation y los coordinadores.
El flujo comienza con las APIs de medición, como la API de Attribution Reporting o la API de Private Aggregation, que generan informes a partir de varias instancias de navegador. Chrome obtiene la clave pública del servicio de hosting de claves en el coordinador para encriptar los informes antes de enviarlos al origen de informes de tu tecnología publicitaria. Las claves públicas se rotan cada siete días.
El origen de informes de tu tecnología publicitaria debe configurarse para recopilar y convertir los informes entrantes al formato avro, y enviarlos a tu servicio de agregación como se describe en las estrategias de procesamiento por lotes.
Cuando tengas un lote listo, envía una solicitud por lotes al servicio de agregación. El servicio de agregación recupera claves de desencriptación del servicio de alojamiento de claves, desencripta los informes y los agrega y genera ruido para crear un informe de resumen. Ten en cuenta que esto depende de que haya suficiente presupuesto de privacidad para crearlos.
Alojas el extremo de origen de informes de la tecnología publicitaria en el que se recopilan los informes, y el servicio de agregación se implementa en tu nube de tecnología publicitaria.
Procesamiento por lotes de informes agregables
El flujo de informes no estaría completo sin la ayuda del servidor de origen de informes designado. Este es el origen que habrías enviado en el proceso de inscripción. El origen de los informes es responsable de recopilar, transformar y agrupar los informes agregables que recibe, y prepararlos para que se envíen a tu servicio de agregación en Google Cloud o Amazon Web Services. Obtén más información para preparar tus informes agregables.
Ahora que tienes el concepto general, podemos analizar con más detalle los componentes que se implementan en tu servicio de agregación.
Componentes de la nube
El servicio de agregación consta de varios componentes de servicios en la nube. Usas las secuencias de comandos de Terraform proporcionadas para aprovisionar y configurar todos los componentes necesarios del servicio en la nube.
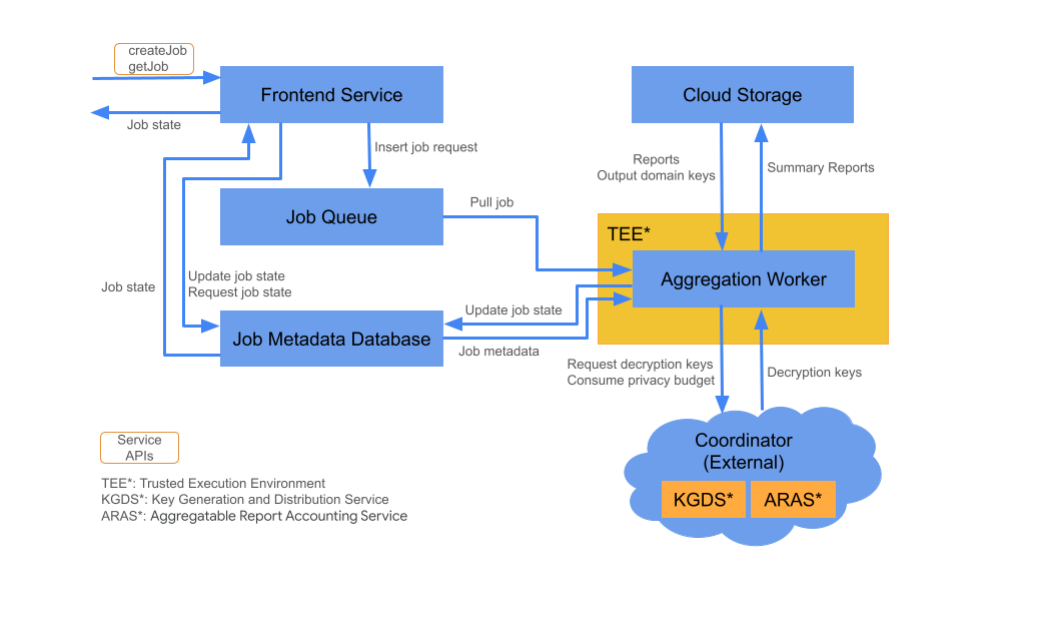
Servicio de frontend
Servicio en la nube administrado: Cloud Function (Google Cloud) o API Gateway (Amazon Web Services)
El servicio de frontend es una puerta de enlace sin servidores que es el punto de entrada principal para las llamadas a la API de Aggregation para la creación de trabajos y la recuperación de su estado. Es responsable de recibir solicitudes de los usuarios del servicio de agregación, validar los parámetros de entrada y comenzar el proceso de programación de tareas de agregación.
El servicio de frontend tiene dos APIs disponibles:
| Extremo | Descripción |
|---|---|
createJob |
Esta API activa un trabajo del servicio de agregación. Para activar el trabajo, se requiere información como el ID del trabajo, los detalles de almacenamiento de entrada, los detalles de almacenamiento de salida, el origen de los informes y mucho más. |
getJob |
Esta API muestra el estado de la tarea que tiene un ID de tarea especificado. Proporciona información sobre el estado del trabajo, como "Recibido", "En curso" o "Finalizado". Si el trabajo está terminado, también muestra el resultado, incluidos los mensajes de error que se encontraron durante la ejecución. |
Consulta la documentación de la API de Aggregation Service.
Lista de tareas en cola
Servicio en la nube administrado: Pub/Sub (Google Cloud) o Amazon SQS (Amazon Web Services)
La lista de tareas en cola es una lista de mensajes que contiene solicitudes de trabajo para el servicio de agregación. El servicio de frontend inserta solicitudes de trabajo en la cola, que luego consumen los trabajadores de agregación que las procesan.
Almacenamiento en la nube
Servicio en la nube administrado: Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services)
Los archivos de entrada y salida que usa el servicio de agregación, como los archivos de informes encriptados y los informes de resumen de salida, se guardan en el almacenamiento en la nube.
Base de datos de metadatos de trabajos
Servicio de nube administrado: Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
La base de datos de metadatos de trabajo se usa para almacenar y hacer un seguimiento del estado de los trabajos de agregación. Registra metadatos, como la hora de creación, la hora solicitada, la hora de actualización y el estado, como Recibido, En curso o Finalizado. Los trabajadores de agregación actualizan la base de datos de metadatos de trabajos a medida que avanzan.
Trabajador de agregación
Servicio de nube administrado: Compute Engine con espacio confidencial (Google Cloud) / Amazon Web Services EC2 con Nitro Enclave (Amazon Web Services)
Un trabajador de agregación procesa las solicitudes de trabajo en la cola de trabajo y desencripta las entradas encriptadas con claves que recupera del servicio de generación y distribución de claves (KGDS) en los coordinadores. Para minimizar la latencia de procesamiento de trabajos, los trabajadores de agregación almacenan en caché las claves de desencriptación durante un período de 8 horas y las usan en todos los trabajos que procesan.
Los trabajadores de agregación operan dentro de una instancia de entorno de ejecución confiable (TEE). Un trabajador solo controla un trabajo a la vez. Puedes configurar varios trabajadores para que procesen trabajos en paralelo si estableces la configuración de escalamiento automático. Si se usa, el ajuste de escala automático ajusta de forma dinámica la cantidad de trabajadores según la cantidad de mensajes en la cola de trabajos. Puedes configurar la cantidad mínima y máxima de trabajadores para el ajuste de escala automático a través del archivo de entorno de Terraform. Puedes encontrar más información sobre el ajuste automático de escala en estas secuencias de comandos de Terraform: Amazon Web Services o Google Cloud.
Los trabajadores de agregación llaman al servicio de contabilización de informes agregables para la contabilización de informes agregables. Este servicio garantiza que las tareas solo se ejecuten si no se superó el límite del presupuesto de privacidad. (consulta la regla"Sin duplicados"). Si el presupuesto está disponible, se genera un informe de resumen con los agregados con ruido. Lee detalles adicionales sobre la contabilidad de informes agregables.
Los trabajadores de agregación actualizan los metadatos de los trabajos en la base de datos de metadatos de trabajos. Esta información incluye los códigos de devolución de trabajos y los contadores de errores de informes en caso de fallas parciales de informes. Los usuarios pueden recuperar el estado con la API de recuperación de estado de trabajo getJob.
Consulta esta explicación para obtener una descripción más detallada del servicio de agregación.
Próximos pasos
Ahora que conoces los aspectos más destacados del servicio de agregación, es hora de que implementes tu propia instancia del servicio de agregación a través de Google Cloud o Amazon Web Services. Consulta la sección de introducción o sigue este vínculo para obtener más información sobre cómo operar el servicio de agregación.
Solución de problemas
Consulta el documento Códigos de error y mitigaciones comunes para obtener descripciones detalladas de los mensajes de error, lo que puede haber causado el error que tienes y los próximos pasos para mitigarlo.
Obtén asistencia y envía comentarios
- Si tienes preguntas sobre el producto, comentarios o solicitudes de funciones, crea un problema en nuestro repositorio de GitHub.
- Si tienes un error durante la implementación, el mantenimiento o la ejecución de trabajos con el servicio de agregación, utiliza este formulario de asistencia técnica para solicitar asistencia.
- Consulta el Panel de estado público para ver si hay problemas conocidos.