Wichtige Konzepte der Private Aggregation API
An wen richtet sich dieses Dokument?
Die Private Aggregation API ermöglicht die aggregierte Datenerhebung aus Worklets mit Zugriff auf websiteübergreifende Daten. Die hier beschriebenen Konzepte sind wichtig für Entwickler, die Berichtsfunktionen in der Shared Storage API und der Protected Audience API erstellen.
- Wenn Sie ein Entwickler sind, der ein Berichtssystem für websiteübergreifende Analysen erstellt.
- Wenn Sie Werbetreibender, Data Scientist oder ein anderer Nutzer von Zusammenfassungsberichten sind, können Sie mithilfe dieser Informationen bessere Entscheidungen bei der Berichtsgestaltung treffen, um einen optimierten Zusammenfassungsbericht zu erhalten.
Wichtige Begriffe
Bevor Sie dieses Dokument lesen, sollten Sie sich mit den wichtigsten Begriffen und Konzepten vertraut machen. Im Folgenden werden diese Begriffe ausführlich beschrieben.
- Ein Aggregationsschlüssel (auch als Bucket bezeichnet) ist eine vordefinierte Sammlung von Datenpunkten. Sie möchten beispielsweise einen Bucket mit Standortdaten erfassen, in dem der Browser den Landesnamen meldet. Ein Aggregationsschlüssel kann mehrere Dimensionen enthalten, z. B. Land und ID Ihres Inhalts-Widgets.
- Ein aggregierbarer Wert ist ein einzelner Datenpunkt, der in einem Aggregationsschlüssel erfasst wird. Wenn Sie messen möchten, wie viele Nutzer aus Frankreich Ihre Inhalte gesehen haben, ist
Franceeine Dimension im Aggregationsschlüssel und derviewCountvon1ist der aggregierbare Wert. - Zusammenführbare Berichte werden in einem Browser erstellt und verschlüsselt. Bei der Private Aggregation API enthält es Daten zu einem einzelnen Ereignis.
- Der Aggregationsdienst verarbeitet Daten aus aggregierbaren Berichten, um einen Zusammenfassungsbericht zu erstellen.
- Ein Zusammenfassungsbericht ist die endgültige Ausgabe des Aggregationsdienstes. Er enthält aggregierte Nutzerdaten mit Rauschen und detaillierte Conversion-Daten.
- Ein Worklet ist eine Infrastruktur, mit der Sie bestimmte JavaScript-Funktionen ausführen und Informationen an den Anfragenden zurückgeben können. Innerhalb eines Worklets können Sie JavaScript ausführen, aber nicht mit der externen Seite interagieren oder kommunizieren.
Workflow für die Private Aggregation
Wenn Sie die Private Aggregation API mit einem Aggregationsschlüssel und einem aggregierbaren Wert aufrufen, generiert der Browser einen aggregierbaren Bericht. Die Berichte werden an Ihren Server gesendet, auf dem sie in Batches zusammengefasst werden. Die Batchberichte werden später vom Aggregationsdienst verarbeitet und ein zusammenfassender Bericht generiert.
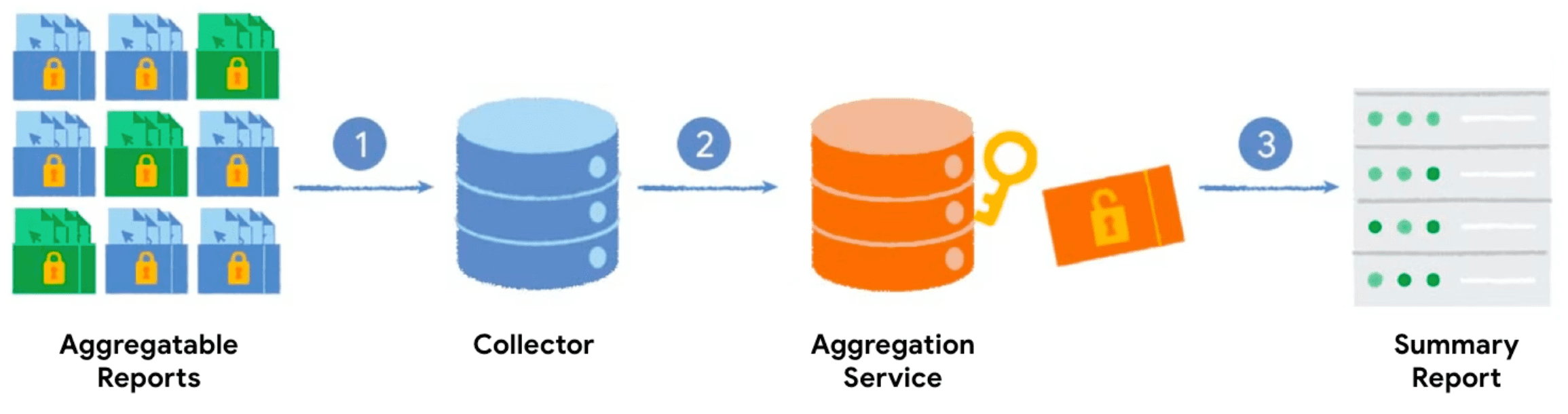
- Wenn Sie die Private Aggregation API aufrufen, generiert und sendet der Client (Browser) den aggregierbaren Bericht zur Erfassung an Ihren Server.
- Ihr Server sammelt die Berichte von den Clients und sendet sie in Batches an den Aggregationsdienst.
- Sobald Sie genügend Berichte erfasst haben, werden sie in einem Batch an den Aggregationsdienst gesendet, der in einer vertrauenswürdigen Ausführungsumgebung ausgeführt wird, um einen Zusammenfassungsbericht zu generieren.
Der in diesem Abschnitt beschriebene Workflow ähnelt der Attribution Reporting API. In Attributionsberichten werden jedoch Daten aus einem Impressionsereignis und einem Conversion-Ereignis verknüpft, die zu unterschiedlichen Zeiten stattfinden. Bei der privaten Aggregation wird ein einzelnes websiteübergreifendes Ereignis erfasst.
Aggregationsschlüssel
Ein Aggregationsschlüssel (kurz „Schlüssel“) steht für den Bucket, in dem die aggregierbaren Werte erfasst werden. Mindestens eine Dimension kann in den Schlüssel codiert werden. Eine Dimension steht für einen Aspekt, zu dem Sie mehr erfahren möchten, z. B. die Altersgruppe der Nutzer oder die Anzahl der Impressionen einer Werbekampagne.
Angenommen, Sie haben ein Widget, das auf mehreren Websites eingebettet ist, und möchten das Land der Nutzer analysieren, die Ihr Widget gesehen haben. Sie möchten Fragen wie „Wie viele der Nutzer, die mein Widget gesehen haben, stammen aus Land X?“ beantworten. Wenn Sie Berichte zu dieser Frage erstellen möchten, können Sie einen Aggregationsschlüssel einrichten, der zwei Dimensionen codiert: „Widget-ID“ und „Länder-ID“.
Der an die Private Aggregation API übergebene Schlüssel ist ein BigInt, der aus mehreren Dimensionen besteht. In diesem Beispiel sind die Dimensionen die Widget-ID und die Länder-ID. Angenommen, die Widget-ID kann bis zu vier Ziffern lang sein, z. B. 1234. Jedem Land wird in alphabetischer Reihenfolge eine Zahl zugewiesen, z. B. 1 für Afghanistan, 61 für Frankreich und 195 für Simbabwe.
Der aggregierbare Schlüssel ist daher 7 Ziffern lang, wobei die ersten 4 Ziffern für das WidgetID und die letzten 3 Ziffern für das CountryID reserviert sind.
Angenommen, der Schlüssel steht für die Anzahl der Nutzer aus Frankreich (Landes-ID 061), die die Widget-ID 3276 gesehen haben. Der Aggregationsschlüssel ist 3276061.
| Aggregationsschlüssel | |
| Widget-ID | Landes-ID |
| 3276 | 061 |
Der Aggregationsschlüssel kann auch mit einem Hash-Mechanismus wie SHA-256 generiert werden. So kann der String {"WidgetId":3276,"CountryID":67} beispielsweise gehasht und dann in einen BigInt-Wert von 42943797454801331377966796057547478208888578253058197330928948081739249096287n umgewandelt werden.
Wenn der Hashwert mehr als 128 Bit hat, können Sie ihn kürzen, damit er den maximal zulässigen Bucket-Wert von 2^128−1 nicht überschreitet.
In einem Worklet für freigegebenen Speicher können Sie auf die Module crypto und TextEncoder zugreifen, mit denen Sie einen Hash generieren können. Weitere Informationen zum Generieren eines Hashwerts finden Sie unter SubtleCrypto.digest() in der MDN.
Im folgenden Beispiel wird beschrieben, wie Sie einen Bucket-Schlüssel aus einem Hashwert generieren:
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
Aggregierbarer Wert
Aggregierbare Werte werden pro Schlüssel für viele Nutzer summiert, um aggregierte Statistiken in Form von Zusammenfassungswerten in Zusammenfassungsberichten zu generieren.
Kehren Sie nun zur Beispielfrage zurück: „Wie viele der Nutzer, die mein Widget gesehen haben, kommen aus Frankreich?“ Die Antwort auf diese Frage sieht in etwa so aus: „Ungefähr 4.881 Nutzer, die mein Widget mit der ID 3276 gesehen haben, stammen aus Frankreich.“ Der aggregierbare Wert ist für jeden Nutzer 1 und „4.881 Nutzer“ ist der aggregierte Wert, also die Summe aller aggregierbaren Werte für diesen Aggregationsschlüssel.
| Aggregationsschlüssel | Aggregierbarer Wert | |
| Widget-ID | Landes-ID | Anzahl der Aufrufe |
| 3276 | 061 | 1 |
In diesem Beispiel erhöhen wir den Wert für jeden Nutzer, der das Widget sieht, um 1. In der Praxis kann der aggregierbare Wert skaliert werden, um das Signal-Rausch-Verhältnis zu verbessern.
Beitragsbudget
Jeder Aufruf der Private Aggregation API wird als Beitrag bezeichnet. Zum Schutz der Privatsphäre der Nutzer ist die Anzahl der Beiträge, die von einer einzelnen Person gesammelt werden können, begrenzt.
Die Summe aller aggregierbaren Werte für alle Aggregationsschlüssel muss unter dem Beitragsbudget liegen. Das Budget gilt pro Worklet, pro Ursprung und pro Tag. Für Protected Audience API- und Shared Storage-Worklets ist es jeweils separat. Für den Tag wird ein rollierendes Fenster von etwa 24 Stunden verwendet. Wenn durch einen neuen aggregierbaren Bericht das Budget überschritten würde, wird der Bericht nicht erstellt.
Das Beitragsbudget wird durch den Parameter L1 dargestellt und auf 216 (65.536) pro zehn Minuten pro Tag mit einem Backstop von 220 (1.048.576) festgelegt. Weitere Informationen zu diesen Parametern finden Sie in diesem Hilfeartikel.
Der Wert des Beitragsbudgets ist willkürlich, aber der Rauschenpegel wird daran angepasst. Mit diesem Budget können Sie das Signal-Rausch-Verhältnis für die Summenwerte maximieren. Weitere Informationen finden Sie im Abschnitt Rauschen und Skalierung.
Weitere Informationen zu Beitragsbudgets findest du in diesem Hilfeartikel. Weitere Informationen finden Sie unter Beitragsbudget.
Beitragslimit pro Bericht
Je nach Anrufer kann das Beitragslimit variieren. Derzeit sind für Berichte, die für Shared Storage API-Aufrufer generiert werden, maximal 20 Beiträge pro Bericht zulässig. Für Protected Audience API-Aufrufer ist die Anzahl der Beiträge pro Bericht auf 100 beschränkt. Diese Limits wurden festgelegt, um die Anzahl der Beiträge, die eingebettet werden können, mit der Größe der Nutzlast in Einklang zu bringen.
Bei gemeinsam genutztem Speicher werden Beiträge, die innerhalb eines einzelnen run()- oder selectURL()-Vorgangs erfolgen, in einem Bericht zusammengefasst. Bei Protected Audience werden Beiträge, die von einem einzelnen Ursprung innerhalb einer Auktion stammen, in einem Batch zusammengefasst.
Beiträge mit Padding
Beiträge werden zusätzlich mit einer Padding-Funktion modifiziert. Durch das Ausfüllen der Nutzlast werden Informationen zur tatsächlichen Anzahl der Beiträge geschützt, die in den aggregierbaren Bericht eingebettet sind. Durch das Padding wird die Nutzlast mit null-Beiträgen (d. h. mit dem Wert 0) auf eine feste Länge erweitert.
Aggregierbare Berichte
Sobald der Nutzer die Private Aggregation API aufruft, generiert der Browser aggregierbare Berichte, die später vom Aggregationsdienst verarbeitet werden, um Zusammenfassungsberichte zu erstellen. Ein aggregierbarer Bericht ist im JSON-Format und enthält eine verschlüsselte Liste von Beiträgen, die jeweils ein {aggregation key, aggregatable value}-Paar sind.
Aggregierbare Berichte werden mit einer zufälligen Verzögerung von bis zu einer Stunde gesendet.
Die Beiträge sind verschlüsselt und können außerhalb des Aggregationsdiensts nicht gelesen werden. Der Aggregationsdienst entschlüsselt die Berichte und generiert einen Zusammenfassungsbericht. Der Verschlüsselungsschlüssel für den Browser und der Entschlüsselungsschlüssel für den Aggregationsdienst werden vom Koordinator ausgegeben, der als Schlüsselverwaltungsdienst fungiert. Der Koordinator führt eine Liste mit Binär-Hashes des Dienst-Images, um zu überprüfen, ob der Aufrufer den Entschlüsselungsschlüssel erhalten darf.
Beispiel für einen aggregierbaren Bericht mit aktiviertem Debug-Modus:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
Die aggregierbaren Berichte können auf der Seite chrome://private-aggregation-internals geprüft werden:

Zum Testen können Sie über die Schaltfläche „Ausgewählte Berichte senden“ den Bericht sofort an den Server senden.
Aggregierbare Berichte erfassen und im Batch zusammenführen
Der Browser sendet die aggregierbaren Berichte an den Ursprung des Worklets, das den Aufruf der Private Aggregation API enthält, und verwendet dabei den aufgeführten bekannten Pfad:
- Für Shared Storage:
/.well-known/private-aggregation/report-shared-storage - Für Protected Audience gilt Folgendes:
/.well-known/private-aggregation/report-protected-audience
An diesen Endpunkten müssen Sie einen Server als Collector betreiben, der die von den Clients gesendeten aggregierbaren Berichte empfängt.
Der Server sollte dann Berichte in einem Batch zusammenfassen und an den Aggregationsdienst senden. Erstellen Sie Batches basierend auf den Informationen in der unverschlüsselten Nutzlast des aggregierbaren Berichts, z. B. im Feld shared_info. Idealerweise sollten die Batches mindestens 100 Berichte enthalten.
Sie können die Batch-Dateien täglich oder wöchentlich erstellen. Diese Strategie ist flexibel. Sie können die Batch-Strategie für bestimmte Ereignisse ändern, bei denen Sie ein höheres Volumen erwarten, z. B. für Tage im Jahr, an denen mehr Impressionen erwartet werden. Batches sollten Berichte mit derselben API-Version, demselben Berichts-Ursprung und derselben geplanten Berichtszeit enthalten.
IDs filtern
Mit der Private Aggregation API und dem Aggregation Service können Sie Filter-IDs verwenden, um Messungen detaillierter zu verarbeiten, z. B. nach Werbekampagne, anstatt die Ergebnisse in größeren Abfragen zu verarbeiten.

Hier sind einige grobe Schritte, die Sie auf Ihre aktuelle Implementierung anwenden können, um sie noch heute zu verwenden.
Schritte für Shared Storage
Wenn du in deinem Flow die Shared Storage API verwendest:
Legen Sie fest, wo Sie Ihr neues Shared Storage-Modul deklarieren und ausführen möchten. Im folgenden Beispiel haben wir die Moduldatei
filtering-worklet.jsgenannt, die unterfiltering-exampleregistriert ist.(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();filteringIdMaxByteskann für jeden Bericht konfiguriert werden. Wenn der Wert nicht festgelegt ist, wird standardmäßig 1 verwendet. Mit diesem Standardwert wird verhindert, dass die Nutzlastgröße und damit die Speicher- und Verarbeitungskosten unnötig erhöht werden. Weitere Informationen finden Sie in der Erläuterung zu flexiblen Beiträgen.Wenn Sie in der oben verwendeten Datei, in diesem Fall
filtering-worklet.js, einen Beitrag anprivateAggregation.contributeToHistogram(...)im Shared Storage-Worklet übergeben, können Sie eine Filter-ID angeben.// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);Berichte, die zusammengefasst werden können, werden an den von Ihnen definierten Endpunkt
/.well-known/private-aggregation/report-shared-storagegesendet. Im Leitfaden zum Filtern von IDs erfahren Sie, welche Änderungen an den Jobparametern des Aggregationsdiensts erforderlich sind.
Nachdem die Batchverarbeitung abgeschlossen und die Daten an den bereitgestellten Aggregationsdienst gesendet wurden, sollten die gefilterten Ergebnisse im abschließenden Zusammenfassungsbericht zu sehen sein.
Schritte für Protected Audience
Wenn Sie in Ihrem Ablauf die Protected Audience API verwenden:
In Ihrer aktuellen Implementierung von Protected Audience können Sie Folgendes einrichten, um die Private Aggregation zu nutzen. Im Gegensatz zum freigegebenen Speicher ist es noch nicht möglich, die maximale Größe der Filter-ID zu konfigurieren. Die maximale Größe der Filter-ID beträgt standardmäßig 1 Byte und wird auf
0nfestgelegt. Diese werden in Ihren Berichtsfunktionen für geschützte Zielgruppen festgelegt (z. B.reportResult()odergenerateBid()).const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);Berichte, die zusammengefasst werden können, werden an den von Ihnen definierten Endpunkt
/.well-known/private-aggregation/report-protected-audiencegesendet. Nachdem die Batchverarbeitung abgeschlossen und die Daten an den bereitgestellten Aggregationsdienst gesendet wurden, sollten die gefilterten Ergebnisse im abschließenden Zusammenfassungsbericht zu sehen sein. Die folgenden Erläuterungen zur Attribution Reporting API und zur Private Aggregation API sowie der ursprüngliche Vorschlag sind verfügbar.
Weitere Informationen finden Sie in unserem Leitfaden zum Filtern von IDs im Aggregationsdienst oder in den Abschnitten zur Attribution Reporting API.
Zusammenfassungsdienst
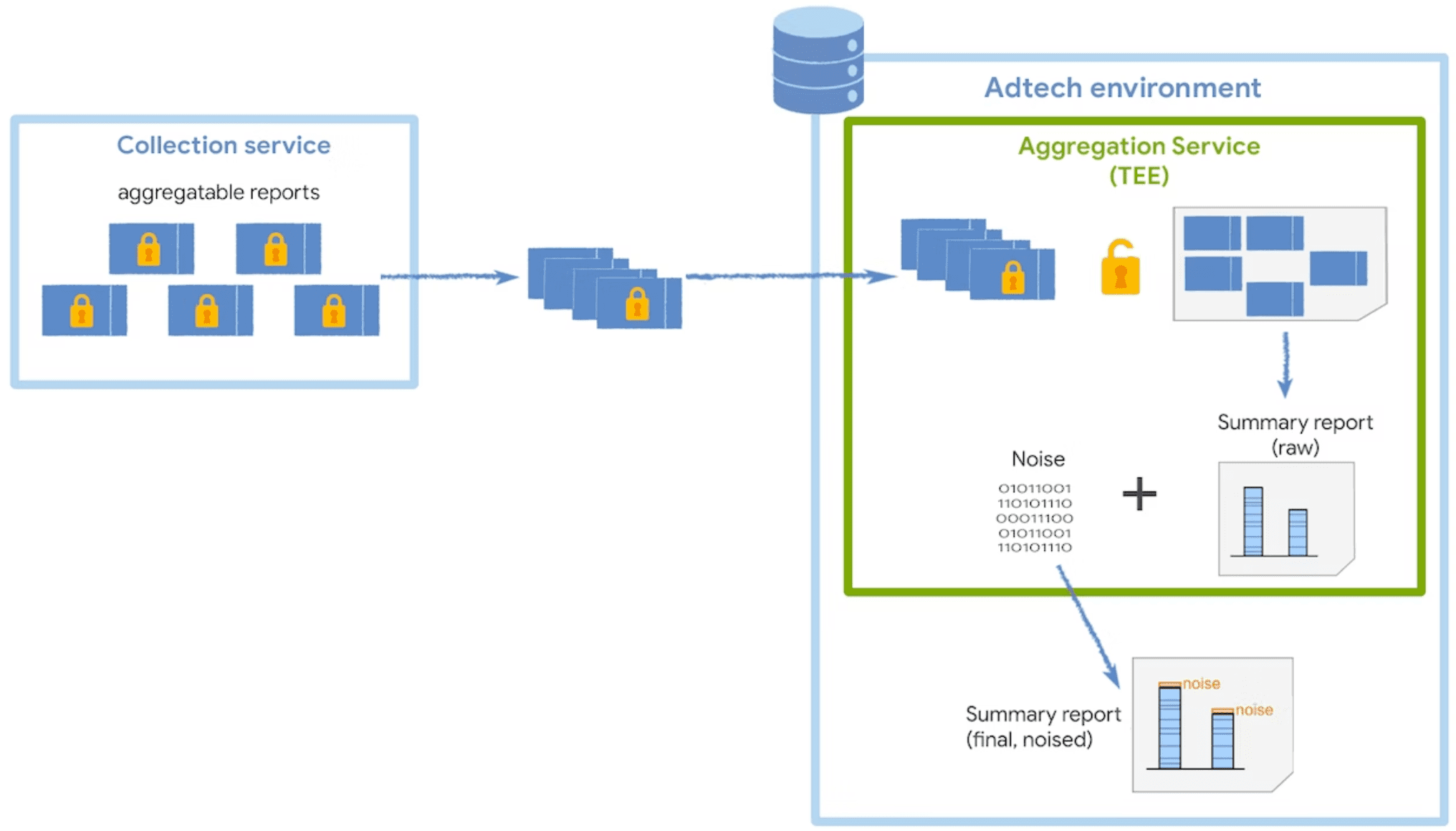
Der Aggregationsdienst empfängt verschlüsselte aggregierbare Berichte vom Collector und generiert Zusammenfassungsberichte. Weitere Strategien zum Gruppieren von Berichten in Ihrem Aggregator finden Sie in unserem Leitfaden für Batches.
Der Dienst wird in einer vertrauenswürdigen Ausführungsumgebung (Trusted Execution Environment, TEE) ausgeführt, die für Datenintegrität, Datenvertraulichkeit und Codeintegrität sorgt. Weitere Informationen dazu, wie Koordinatoren zusammen mit TEEs verwendet werden, finden Sie unter Rolle und Zweck von Koordinatoren.
Zusammenfassende Berichte
In Zusammenfassungsberichten sehen Sie die von Ihnen erfassten Daten mit hinzugefügtem Rauschen. Sie können Zusammenfassungsberichte für eine bestimmte Gruppe von Schlüsseln anfordern.
Ein Zusammenfassungsbericht enthält eine Reihe von Schlüssel/Wert-Paaren im JSON-Wörterbuchstil. Jedes Paar enthält Folgendes:
bucket: Der Aggregationsschlüssel als Binärzahlenstring. Wenn der verwendete Aggregationsschlüssel „123“ lautet, ist der Bucket „1111011“.value: Der zusammengefasste Wert für ein bestimmtes Analyseziel, der aus allen verfügbaren aggregierbaren Berichten mit Rauschen berechnet wird.
Beispiel:
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
Rauschen und Skalierung
Um die Privatsphäre der Nutzer zu schützen, fügt der Aggregationsdienst jedem zusammengefassten Wert jedes Mal, wenn ein zusammengefasster Bericht angefordert wird, einmal Rauschen hinzu. Die Rauschwerte werden zufällig aus einer Laplace-Wahrscheinlichkeitsverteilung gezogen. Sie können zwar nicht direkt steuern, wie Rauschen hinzugefügt wird, aber Sie können die Auswirkungen von Rauschen auf die Messdaten beeinflussen.
Die Verteilung des Rauschens ist unabhängig von der Summe aller aggregierbaren Werte. Je höher die aggregierten Werte sind, desto geringer ist die Wahrscheinlichkeit, dass sich das Rauschen auswirkt.
Angenommen, die Rauschverteilung hat eine Standardabweichung von 100 und ist auf null zentriert. Wenn der erfasste aggregierbare Berichtswert (oder „aggregierbare Wert“) nur 200 beträgt, entspricht die Standardabweichung des Rauschens 50% des aggregierten Werts. Wenn der aggregierbare Wert jedoch 20.000 beträgt, entspricht die Standardabweichung des Rauschens nur 0,5% des aggregierten Werts. Der aggregierbare Wert von 20.000 hat also ein viel höheres Signal-Rausch-Verhältnis.
Wenn Sie den aggregierbaren Wert mit einem Skalierungsfaktor multiplizieren, können Sie so die Fehler reduzieren. Der Skalierungsfaktor gibt an, um wie viel Sie einen bestimmten aggregierbaren Wert skalieren möchten.

Wenn Sie die Werte durch einen größeren Skalierungsfaktor vergrößern, wird der relative Rauschanteil reduziert. Dadurch wird jedoch auch die Summe aller Beiträge in allen Kategorien schneller auf das Beitragsbudgetlimit angerechnet. Wenn Sie die Werte durch Auswahl eines kleineren Skalierungsfaktors verringern, erhöht sich der relative Rauschanteil, aber das Risiko, das Budgetlimit zu erreichen, sinkt.
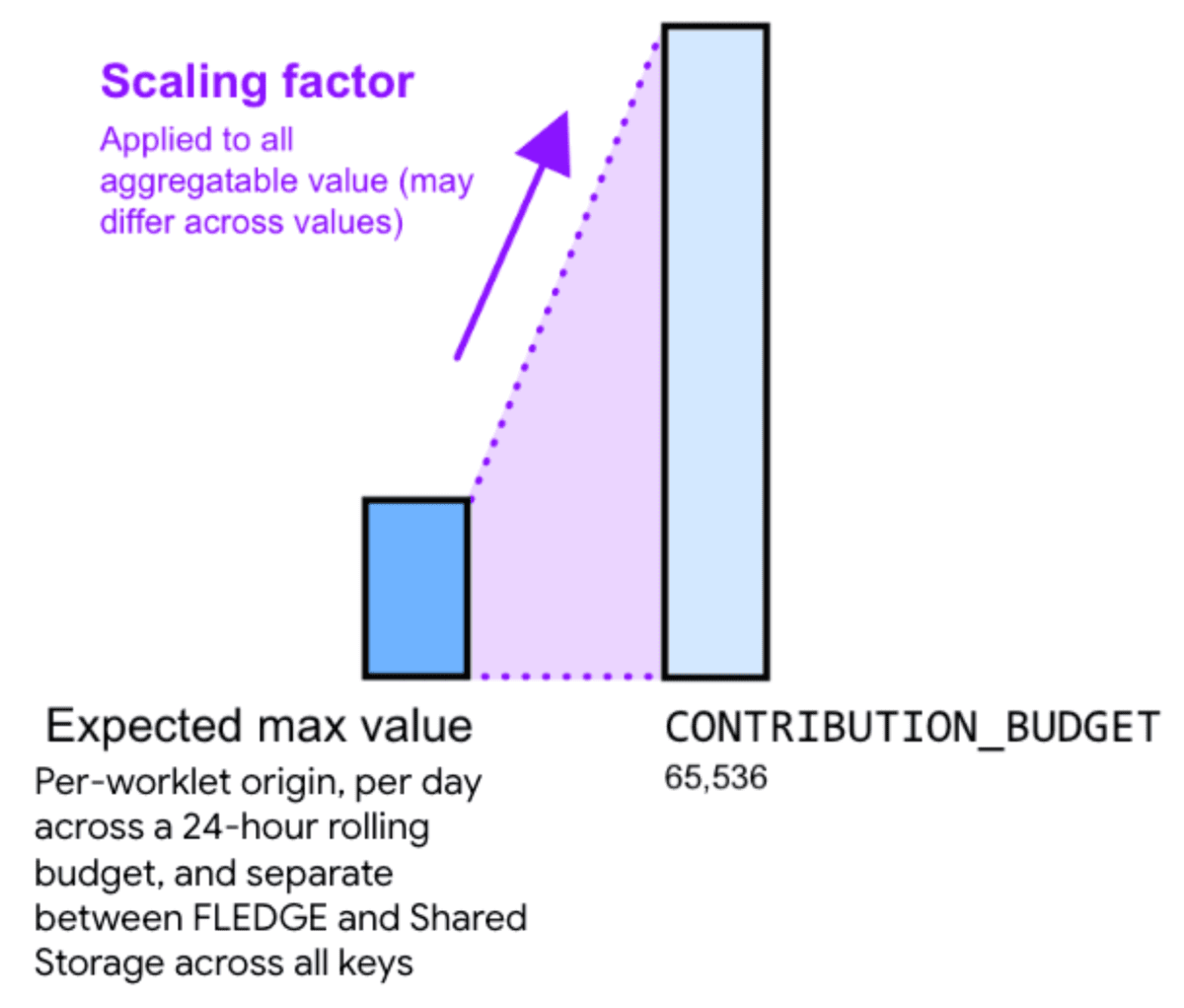
Um einen geeigneten Skalierungsfaktor zu berechnen, teilen Sie das Beitragsbudget durch die maximale Summe der aggregierbaren Werte für alle Schlüssel.
Weitere Informationen finden Sie in der Dokumentation zum Beitragsbudget.
Mit Nutzern interagieren und Feedback geben
Die Private Aggregation API befindet sich in der Entwicklungsphase und kann sich in Zukunft ändern. Wenn Sie diese API ausprobieren und Feedback haben, würden wir uns sehr darüber freuen.
- GitHub: Lesen Sie die Erläuterung, stellen Sie Fragen und nehmen Sie an der Diskussion teil.
- Entwicklersupport: Stellen Sie Fragen und nehmen Sie an Diskussionen im Repository für den Privacy Sandbox-Entwicklersupport teil.
- Treten Sie der Shared Storage API-Gruppe und der Protected Audience API-Gruppe bei, um die neuesten Ankündigungen zur privaten Aggregation zu erhalten.