Places Insights データに直接アクセスするには、BigQuery で SQL クエリを作成して、場所に関する集約された分析情報を返します。結果は、クエリで指定された検索条件のデータセットから返されます。
5 未満のカウントを取得する必要がある場合は、代わりに Places Count 関数 を使用することを検討してください。これらの関数は、0 を含む任意のカウントを返すことができますが、最小検索エリアは 40.0 メートル x 40.0 メートル(1,600 平方メートル)に制限されます。直接クエリを実行する場合と関数を使用する場合の詳細をご覧ください。
クエリの基本
次の図は、クエリの基本的な形式を示しています。

クエリの各部分について、以下で詳しく説明します。
クエリの要件
データセットに対して直接実行される SQL クエリでは、データセットを指定し、SELECT 句に WITH AGGREGATION_THRESHOLD を含める必要があります。これがないと、クエリは失敗します。
この例では、places_insights___us.places を指定して、米国向けのデータセットに対してクエリを実行します。
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`
プロジェクト名を指定する(省略可)
必要に応じて、クエリにプロジェクト名を含めることができます。プロジェクト名を指定しない場合、クエリはデフォルトでアクティブなプロジェクトになります。
異なるプロジェクトで同じ名前のデータセットをリンクしている場合や、アクティブなプロジェクト外のテーブルに対してクエリを実行する場合は、プロジェクト名を含めることをおすすめします。
例: [project name].[dataset name].places
集計関数を指定する
次の例は、サポートされている BigQuery 集計 関数を示しています。 このクエリは、ニューヨーク市のエンパイア ステート ビルから半径 1,000 メートル以内のすべての場所の評価を集計して、評価の統計情報を生成します。
SELECT WITH AGGREGATION_THRESHOLD COUNT(id) AS place_count, APPROX_COUNT_DISTINCT(rating) as distinct_ratings, COUNTIF(rating > 4.0) as good_rating_count, LOGICAL_AND(rating <= 5) as all_ratings_equal_or_below_five, LOGICAL_OR(rating = 5) as any_rating_exactly_five, AVG(rating) as avg_rating, SUM(user_rating_count) as rating_count, COVAR_POP(rating, user_rating_count) as rating_covar_pop, COVAR_SAMP(rating, user_rating_count) as rating_covar_samp, STDDEV_POP(rating) as rating_stddev_pop, STDDEV_SAMP(rating) as rating_stddev_samp, VAR_POP(rating) as rating_var_pop, VAR_SAMP(rating) as rating_var_samp, FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL"
ロケーションの制限を指定する
ロケーションの制限を指定しない場合、データ集計はデータセット全体 に適用されます。通常、特定のエリアを検索するためにロケーションの制限を指定します。このクエリの例では、ニューヨーク市のエンパイア ステート ビルを中心とした半径 1, 000 メートルのターゲット制限を指定しています。
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000)
ポリゴンを使用して検索エリアを指定できます。ポリゴンを使用する場合、ポリゴンの最初の点が最後の点と同じになるように、ポリゴンの点を閉じたループで定義する必要があります。
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_CONTAINS(ST_GEOGFROMTEXT("""POLYGON((-73.985708 40.75773,-73.993324 40.750298, -73.9857 40.7484,-73.9785 40.7575, -73.985708 40.75773))"""), point)
次の例では、接続された点の線を使用して検索エリアを定義し、線の周囲 100 メートルの検索半径を設定します。この線は、 Routes APIで計算されたルートに似ています。ルートは、車両、自転車、歩行者向けに設定できます。
DECLARE route GEOGRAPHY; SET route = ST_GEOGFROMTEXT("""LINESTRING(-73.98903537033028 40.73655649223003, -73.93580216278471 40.80955538843361)"""); SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(route, point, 100)
場所のデータセット フィールドでフィルタする
データセット スキーマで定義されたフィールドに基づいて検索を絞り込みます。場所の regular_opening_hours、price_level、顧客の rating などのデータセット フィールドに基づいて結果をフィルタします。
対象の国のデータセット スキーマで定義されているデータセット内のフィールドを参照します。各国のデータセット スキーマは、次の 2 つの部分で構成されています。
たとえば、クエリに、クエリのフィルタ条件を定義する WHERE 句を含めることができます。
次の例では、business_status が OPERATIONAL、rating が 4.0 以上、allows_dogs が true に設定されている tourist_attraction タイプの場所の集計データを返します。
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND 'tourist_attraction' IN UNNEST(types) AND business_status = "OPERATIONAL" AND rating >= 4.0 AND allows_dogs = true
次のクエリは、EV 充電スタンドが 8 つ以上ある場所の結果を返します。
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
場所のプライマリ タイプと場所のタイプでフィルタする
データセット内の各場所には、次のいずれかを含めることができます。
場所のタイプで定義されたタイプから関連付けられた 単一のプライマリ タイプ。たとえば、プライマリ タイプは
mexican_restaurantまたはsteak_houseになります。 クエリでprimary_typeを使用して、場所のプライマリ タイプで結果をフィルタします。複数のタイプ値が、 場所のタイプで定義されたタイプから関連付けられています。たとえば レストランには、
seafood_restaurant、restaurant、food、point_of_interest、establishmentなどのタイプがあります。クエリでtypesを使用して、場所に関連付けられたタイプのリストで結果をフィルタします。
次のクエリは、プライマリ タイプが skin_care_clinic で、spa としても機能するすべての場所の結果を返します。
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE 'spa' IN UNNEST(types) AND 'skin_care_clinic' = primary_type
場所 ID でフィルタする
次の例では、5 つの場所の平均評価を計算します。場所は place_id で識別されます。
DECLARE place_ids ARRAY<STRING>; SET place_ids = ['ChIJPQOh8YVZwokRE2WsbZI4tOk', 'ChIJibtT3ohZwokR7tX0gp0nG8U', 'ChIJdfD8moVZwokRO6vxjXAtoWs', 'ChIJsdNONuFbwokRLM-yuifjb8k', 'ChIJp0gKoClawokR0txqrcaEkFc']; SELECT WITH AGGREGATION_THRESHOLD AVG(rating) as avg_rating, FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(place_ids) place_id WHERE id = place_id;
特定の場所 ID を除外する
場所 ID の配列をクエリから除外することもできます。
目的のプレイス ID を見つけるには、Place ID Finder を使用するか、 Places API を使用してテキスト検索(新版) リクエストをプログラムで実行します。
次の例では、クエリは、オーストラリアのシドニーの郵便番号 2000
のカフェの数を検索します。これらのカフェは、excluded_cafes 配列に表示されません。このようなクエリは、カウントから自分のビジネスを除外したいビジネス オーナーに役立ちます。
WITH excluded_cafes AS ( -- List the specific place IDs to exclude from the final count SELECT * FROM UNNEST([ 'ChIJLTcYGz-uEmsRmazk9oMnP5w', 'ChIJeWDDDNOvEmsRF8SMPUwPbhw', 'ChIJKdaKHbmvEmsRSdxq_1O05bU' ]) AS place_id ) SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `places_insights___au.places` AS places -- Perform a LEFT JOIN to identify which places are in the exclusion list LEFT JOIN excluded_cafes ON places.id = excluded_cafes.place_id WHERE -- Filter for specific place type and postal code places.primary_type = 'cafe' AND '2000' IN UNNEST(places.postal_code_names) -- Keep only the rows where the join failed (meaning the ID was NOT in the list) AND excluded_cafes.place_id IS NULL;
事前定義されたデータ値でフィルタする
多くのデータセット フィールドには、事前定義された値があります。例:
price_levelフィールドでは、次の事前定義値がサポートされています。PRICE_LEVEL_FREEPRICE_LEVEL_INEXPENSIVEPRICE_LEVEL_MODERATEPRICE_LEVEL_EXPENSIVEPRICE_LEVEL_VERY_EXPENSIVE
business_statusフィールドでは、次の事前定義値がサポートされています。OPERATIONALCLOSED_TEMPORARILYCLOSED_PERMANENTLYFUTURE_OPENING
この例では、クエリは、ニューヨーク市のエンパイア ステート ビルから半径 1, 000 メートル以内の business_status が OPERATIONAL のすべての花屋の数を返します。
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL" AND 'florist' IN UNNEST(types)
営業時間でフィルタする
この例では、金曜日のハッピーアワーがある地理的エリア内のすべての場所の数を返します。
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(regular_opening_hours_happy_hour.friday) AS friday_hours WHERE '17:00:00' BETWEEN friday_hours.start_time AND friday_hours.end_time AND ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000);
地域(住所コンポーネント)でフィルタする
プレイスのデータセットには、政治的境界に基づいて結果をフィルタするのに役立つ住所コンポーネントのセットも含まれています。各住所コンポーネントは、テキストコード名(ニューヨーク市の郵便番号の場合は 10002)または同等の郵便番号 ID のプレイス ID(ChIJm5NfgIBZwokR6jLqucW0ipg)で識別されます。
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE '10002' IN UNNEST(postal_code_names) --- 'ChIJm5NfgIBZwokR6jLqucW0ipg' IN UNNEST(postal_code_ids) -- same filter as above using postal code ID
EV 充電スタンドでフィルタする
この例では、EV 充電スタンドが 8 つ以上ある場所の数を取得します。
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
この例では、急速充電をサポートする Tesla 充電スタンドが 10 個以上ある場所の数をカウントします。
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(ev_charge_options.connector_aggregation) as connectors WHERE connectors.type ='EV_CONNECTOR_TYPE_TESLA' AND connectors.max_charge_rate_kw >= 50 AND connectors.count >= 10
結果グループを返す
これまでに示したクエリは、クエリの集計カウントを含む単一行を結果として返します。GROUP BY 演算子を使用して、グループ化条件に基づいて複数の行をレスポンスで返すこともできます。
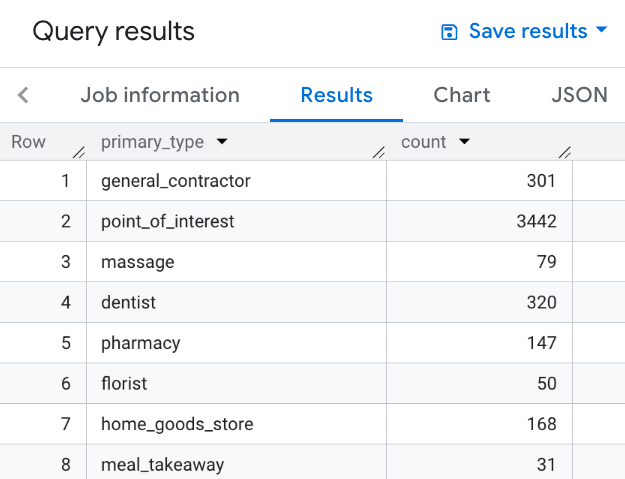
たとえば、次のクエリは、検索エリア内の各場所のプライマリ タイプでグループ化された結果を返します。
SELECT WITH AGGREGATION_THRESHOLD primary_type, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.99992071622756, 40.71818785986936), point, 1000) GROUP BY primary_type
この画像は、このクエリの出力例を示しています。
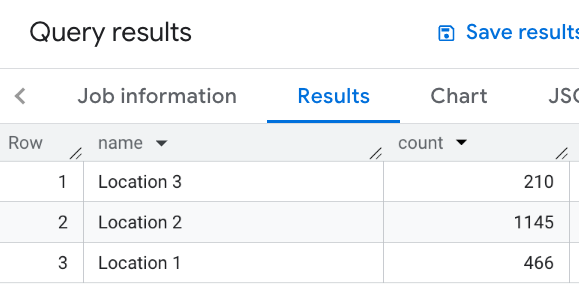
この例では、場所のテーブルを定義します。次に、各場所について、近くのレストランの数(1, 000 メートル以内)を計算します。
WITH my_locations AS ( SELECT 'Location 1' AS name, ST_GEOGPOINT(-74.00776440888504, 40.70932825380786) AS location UNION ALL SELECT 'Location 2' AS name, ST_GEOGPOINT(-73.98257192833559, 40.750738934863215) AS location UNION ALL SELECT 'Location 3' AS name, ST_GEOGPOINT(-73.94701794263223, 40.80792954838445) AS location ) SELECT WITH AGGREGATION_THRESHOLD l.name, COUNT(*) as count FROM `PROJECT_NAME.places_insights___us.places` JOIN my_locations l ON ST_DWITHIN(l.location, p.point, 1000) WHERE primary_type = "restaurant" AND business_status = "OPERATIONAL" GROUP BY l.name
この画像は、このクエリの出力例を示しています。