モデルを構築したら、収束を評価し、必要に応じてモデルをデバッグしてから、モデルの適合度を評価する必要があります。
収束を評価する
モデルの完全性を確保するために、モデルの収束を評価します。
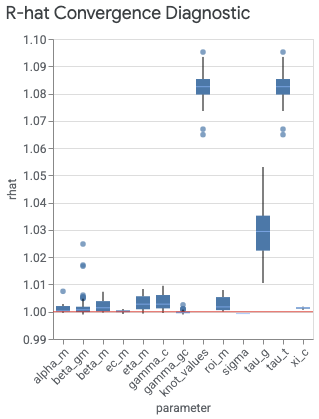
visualizer.ModelDiagnostics() の plot_rhat_boxplot コマンドは、連鎖の収束のゲルマンおよびルービン(1992 年)の潜在的スケール減少(一般に R-hat と呼ばれます)を要約して計算します。この収束診断は、連鎖間の分散(平均)が、連鎖が均一に分布している場合に想定される分散をどの程度超過しているかを測定します。
モデルのパラメータごとに R-hat 値が 1 つずつあります。箱ひげチャートは、インデックス全体の R-hat 値の分布を要約したものです。たとえば、beta_gm の X 軸のラベルに対応する箱は、地域インデックス g とチャネル インデックス m の両方における R-hat 値の分布を要約しています。
値が 1.0 に近いほど、収束が進んでいることを示します。R-hat が 1.2 に満たない場合は近似収束を示しており、多くの問題で妥当なしきい値になります(ブルックスおよびゲルマン、1998 年)。収束がない場合、原因は通常、尤度(モデル仕様)または事前分布でデータに対するモデルの指定が著しく間違っているか、十分なバーンインが行われていない(n_adapt + n_burnin が十分に大きくない)ことのいずれかです。
収束が難しい場合は、MCMC の収束を達成するをご確認ください。
R-hat 箱ひげチャートを生成する
次のコマンドを実行して、R-hat 箱ひげチャートを生成します。
model_diagnostics = visualizer.ModelDiagnostics(mmm)
model_diagnostics.plot_rhat_boxplot()
出力例:
トレース プロットと密度プロットを生成する
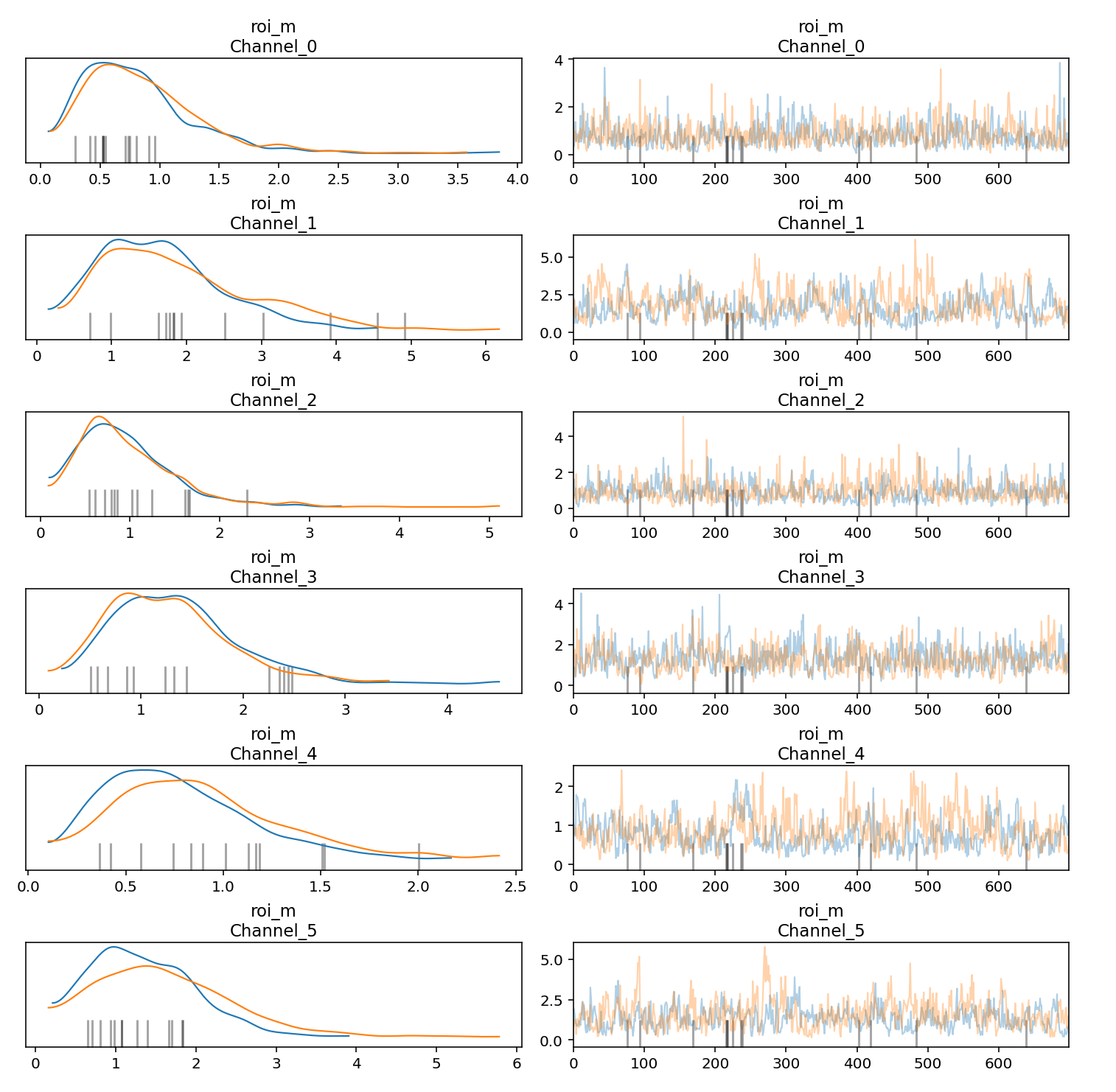
マルコフ連鎖モンテカルロ法(MCMC)サンプルのトレース プロットと密度プロットを生成すると、連鎖間の収束と安定性を評価できます。トレース プロットの各トレースは、MCMC アルゴリズムがパラメータ空間を探索する際に生成された値のシーケンスを表します。アルゴリズムが反復処理を繰り返す中で、パラメータのさまざまな値をどのように処理するかを示しています。トレース プロットでは、連鎖が同じ状態を長時間維持する、または同一方向にステップが過度に連続するような、フラットな領域は避けてください。
左側の密度プロットは、MCMC アルゴリズムによって取得された 1 つ以上のパラメータのサンプル値の密度分布を可視化しています。密度プロットでは、連鎖が安定した密度分布に収束していることを確認します。
次の例は、トレース プロットと密度プロットを生成する方法を示しています。
parameters_to_plot=["roi_m"]
for params in parameters_to_plot:
az.plot_trace(
meridian.inference_data,
var_names=params,
compact=False,
backend_kwargs={"constrained_layout": True},
)
出力例:
事前分布と事後分布を確認する
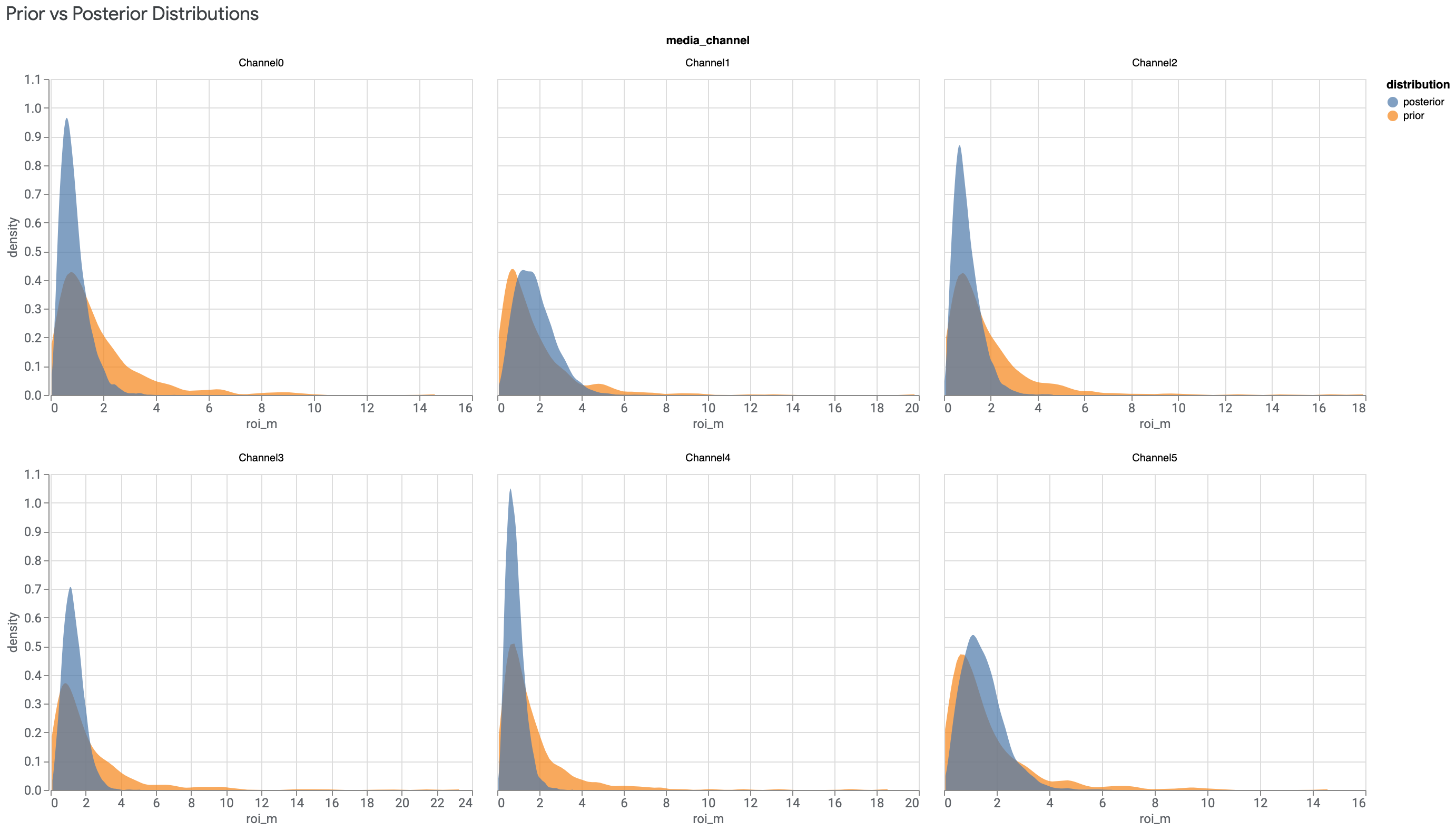
データに情報が少ない場合、事前分布と事後分布は類似します。詳細については、事前分布と事後分布が同一の場合をご確認ください。
特に費用の少ないチャネルは、費用対効果の事後分布が費用対効果の事前分布と類似する傾向があります。この問題を解決するには、MMM 用のデータの準備時に、費用が非常に低いチャネルを削除するか、他のチャネルと組み合わせることをおすすめします。
次のコマンドを実行して、各メディア チャネルの費用対効果事後分布を費用対効果事前分布と比較してプロットします。
model_diagnostics = visualizer.ModelDiagnostics(mmm)
model_diagnostics.plot_prior_and_posterior_distribution()
出力例:(画像をクリックして拡大)
デフォルトでは、plot_prior_and_posterior_distribution() は費用対効果の事後分布と事前分布を生成します。ただし、次の例に示すように、特定のモデル パラメータを plot_prior_and_posterior_distribution() に渡すことができます。
model_diagnostics.plot_prior_and_posterior_distribution('beta_m')
モデルの適合度を評価する
モデルの収束が最適化されたら、モデルの適合度を評価します。詳細については、モデリング後のモデルの適合度を評価するをご確認ください。
マーケティング ミックス モデリング(MMM)では、間接的な測定値に基づいて因果推論を評価し、妥当な結果を探す必要があります。次の 2 つの方法がおすすめです。
- 決定係数、平均絶対誤差率(MAPE)、加重平均絶対誤差率(wMAPE)の指標の使用
kpi_typeとrevenue_per_kpiの可用性に応じた収益または KPI の予測値と実測値の比較プロットの生成
決定係数、MAPE、wMAPE の指標を使用する
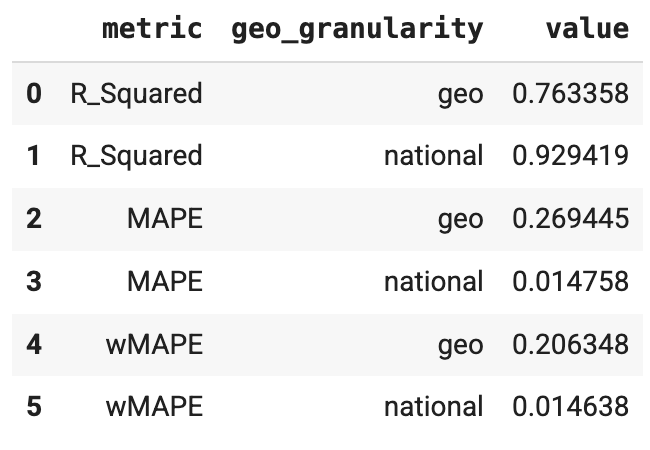
適合度指標の有効性は、モデル構造が適切で、過剰パラメータ化されていないことを確認するための信頼性チェックとして使用できます。ModelDiagnostics は、R-Squared、MAPE、wMAPE の適合度指標の有効性を計算します。メリディアンで holdout_id が設定されている場合は、Train および Test サブセットの R-squared、MAPE、wMAPE も計算されます。適合度指標の有効性は予測精度の指標であり、通常は MMM の目標ではありません。ただし、この指標は有用な信頼性チェックとして機能します。
次のコマンドを実行すると、決定係数、MAPE、wMAPE の指標を生成できます。
model_diagnostics = visualizer.ModelDiagnostics(mmm)
model_diagnostics.predictive_accuracy_table()
出力例:
予測値と実測値のプロットを生成する
予測値と実測値のプロットを使用すると、モデルの適合度を間接的に評価できます。
全国: 予測値と実測値のプロット
モデルの収益または KPI の予測値と、収益または KPI の実測値を全国レベルでプロットすると、モデルの適合度を評価できます。ベースラインは、メディア使用がなかった場合の収益(または KPI)を対象とした、モデルの反事実的条件法による推定値です。収益を可能な限り実際の収益に近づけて推定することは、MMM の目標ではない場合もありますが、信頼性チェックには役立ちます。
次のコマンドを実行すると、全国レベルのデータの収益(または KPI)の実測値と予測値をプロットできます。
model_fit = visualizer.ModelFit(mmm)
model_fit.plot_model_fit()
出力例:
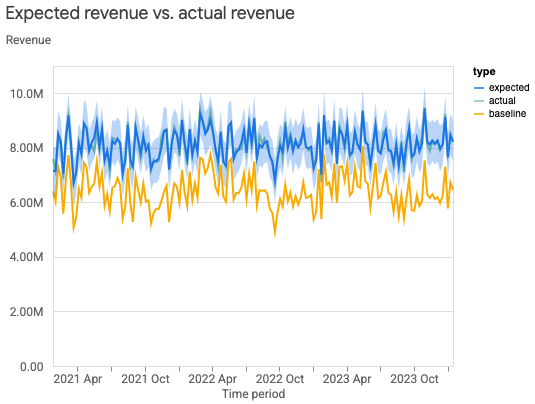
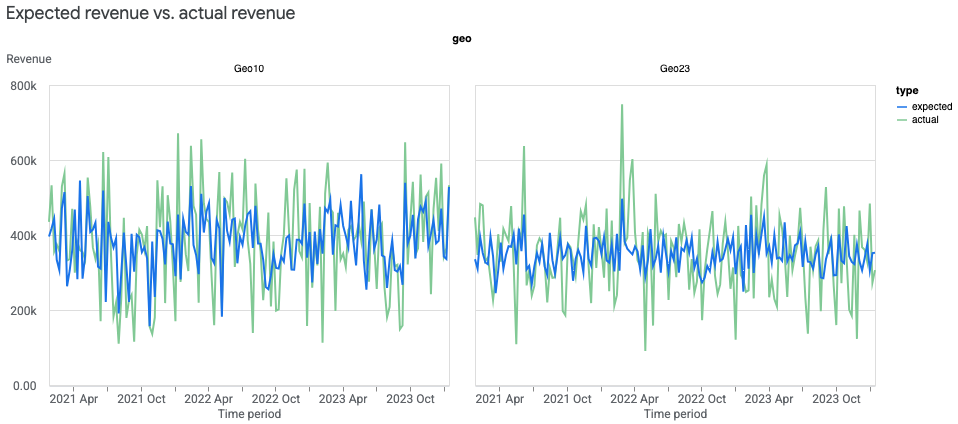
地域: 予測値と実測値のグラフ
地域レベルで予測値と実測値の比較グラフを作成して、モデルの適合度を評価できます。地域の数が多い場合は、最も大きな地域のみを表示することをおすすめします。
次のコマンドを実行すると、地域の収益(または KPI)の実測値と予測値をプロットできます。
model_fit = visualizer.ModelFit(mmm)
model_fit.plot_model_fit(n_top_largest_geos=2,
show_geo_level=True,
include_baseline=False,
include_ci=False)
出力例:
モデルの適合度に満足したら、モデルの結果を分析します。