在上一个教程(简介)中,我们了解了卫星嵌入如何捕获卫星观测和气候变量的年度轨迹。这样一来,无需对作物物候进行建模,即可轻松使用该数据集来绘制作物分布图。作物类型映射是一项艰巨的任务,通常需要对作物物候进行建模,并收集该地区种植的所有作物的田间样本。
在本教程中,我们将采用一种无监督的作物分类方法来进行作物地图绘制,这样我们就可以在不依赖田地标签的情况下执行这项复杂的任务。此方法利用了区域的本地知识以及汇总的作物统计信息,这些信息在世界许多地方都可轻松获取。
选择区域
在本教程中,我们将为爱荷华州的 Cerro Gordo 县创建作物类型地图。该县位于美国玉米带,主要种植两种作物:玉米和大豆。这些本地知识非常重要,有助于我们确定模型的关键参数。
我们先来获取所选县的边界。
// Select the region
// Cerro Gordo County, Iowa
var counties = ee.FeatureCollection('TIGER/2018/Counties');
var selected = counties
.filter(ee.Filter.eq('GEOID', '19033'));
var geometry = selected.geometry();
Map.centerObject(geometry, 12);
Map.addLayer(geometry, {color: 'red'}, 'Selected Region', false);

图:所选地区
准备卫星嵌入数据集
接下来,我们加载卫星嵌入数据集,过滤出所选年份的图片,然后创建镶嵌图。
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
var year = 2022;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredembeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
var embeddingsImage = filteredembeddings.mosaic();
创建农作物地块掩码
对于我们的模型,我们需要排除非耕地面积。许多全球和区域级数据集可用于创建作物掩码。ESA WorldCover 或 GFSAD 全球农田范围产品是全球农田数据集的理想选择。最近新增了 ESA WorldCereal Active Cropland 产品,其中包含活跃耕地的季节性地图。由于我们的区域位于美国,因此可以使用更准确的区域数据集 USDA NASS Cropland Data Layers (CDL) 来获取作物掩码。
// Use Cropland Data Layers (CDL) to obtain cultivated cropland
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var croplandMask = cdl.select('cultivated').eq(2).rename('cropmask');
// Visualize the crop mask
var croplandMaskVis = {min: 0, max: 1, palette: ['white', 'green']};
Map.addLayer(croplandMask.clip(geometry), croplandMaskVis, 'Crop Mask');
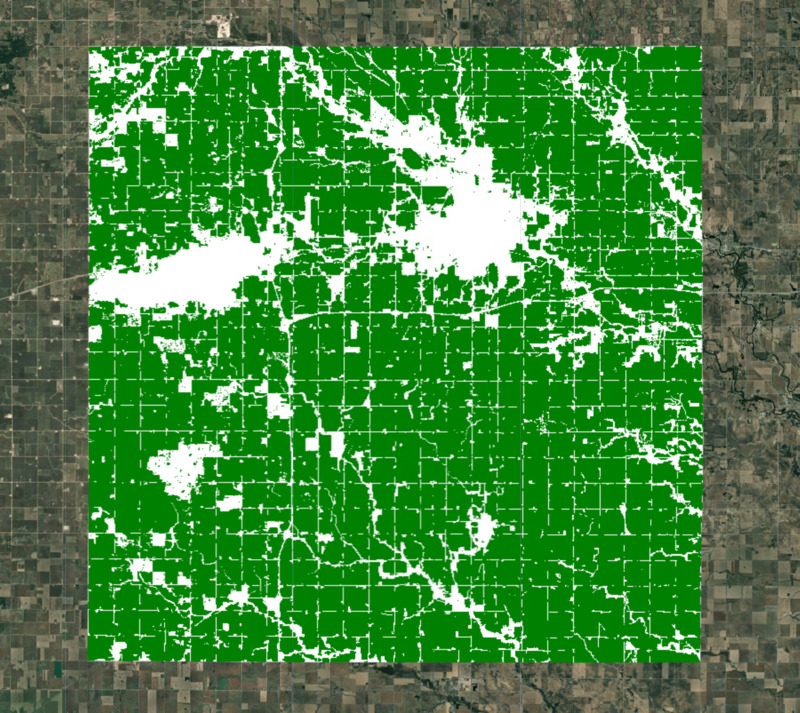
图:已选择的区域,带有耕地掩码
提取训练样本
我们将农作物地块掩码应用于嵌入马赛克。现在,我们只剩下代表该县耕种农田的所有像素。
// Mask all non-cropland pixels
var clusterImage = embeddingsImage.updateMask(croplandMask);
我们需要获取卫星嵌入图片,并获取随机样本来训练聚类模型。由于我们感兴趣的区域包含许多被遮盖的像素,因此简单的随机抽样可能会导致样本出现 null 值。为确保我们可以提取所需数量的非 null 样本,我们使用分层抽样在未遮盖的区域中获取所需数量的样本。
// Stratified random sampling
var training = clusterImage.addBands(croplandMask).stratifiedSample({
numPoints: 1000,
classBand: 'cropmask',
region: geometry,
scale: 10,
tileScale: 16,
seed: 100,
dropNulls: true,
geometries: true
});
将示例导出到资源(可选)
提取样本是一项计算量大的操作,最好将提取的训练样本导出为素材资源,并在后续步骤中使用导出的素材资源。这有助于解决处理大型区域时出现的计算超时或用户内存超出错误。
启动导出任务,并等待其完成,然后再继续。
// Replace this with your asset folder
// The folder must exist before exporting
var exportFolder = 'projects/spatialthoughts/assets/satellite_embedding/';
var samplesExportFc = 'cluster_training_samples';
var samplesExportFcPath = exportFolder + samplesExportFc;
Export.table.toAsset({
collection: training,
description: 'Cluster_Training_Samples',
assetId: samplesExportFcPath
});
导出任务完成后,我们可以将提取的样本作为要素集合读回代码中。
// Use the exported asset
var training = ee.FeatureCollection(samplesExportFcPath);
直观呈现样本
无论您是以交互方式运行样本,还是将其导出到要素集合,现在您都将拥有一个包含样本点的训练变量。我们来打印第一个样本以进行检查,并将训练点添加到 Map。
print('Extracted sample', training.first());
Map.addLayer(training, {color: 'blue'}, 'Extracted Samples', false);

图:提取的用于聚类的随机样本
执行非监督式聚类
现在,我们可以训练聚类器,并将 64 维嵌入向量分组为所选数量的不同聚类。根据我们的当地知识,主要有两类作物占据了该地区的大部分面积,其余面积则种植了其他几种作物。我们可以对卫星嵌入进行无监督聚类,以获得具有相似时间轨迹和模式的像素聚类。具有相似光谱和空间特征以及相似物候的像素将归为同一聚类。
借助 ee.Clusterer.wekaCascadeKMeans(),我们可以指定最小和最大聚类数,并根据训练数据找到最佳聚类数。这时,我们的本地知识就派上了用场,可以帮助我们确定聚类的最小和最大数量。由于我们预计会有几种不同的聚类类型(玉米、大豆和其他几种作物),因此我们可以将最小聚类数设为 4,将最大聚类数设为 5。您可能需要尝试使用这些数字,才能找出最适合您所在地区的设置。
// Cluster the Satellite Embedding Image
var minClusters = 4;
var maxClusters = 5;
var clusterer = ee.Clusterer.wekaCascadeKMeans({
minClusters: minClusters, maxClusters: maxClusters}).train({
features: training,
inputProperties: clusterImage.bandNames()
});
var clustered = clusterImage.cluster(clusterer);
Map.addLayer(clustered.randomVisualizer().clip(geometry), {}, 'Clusters');
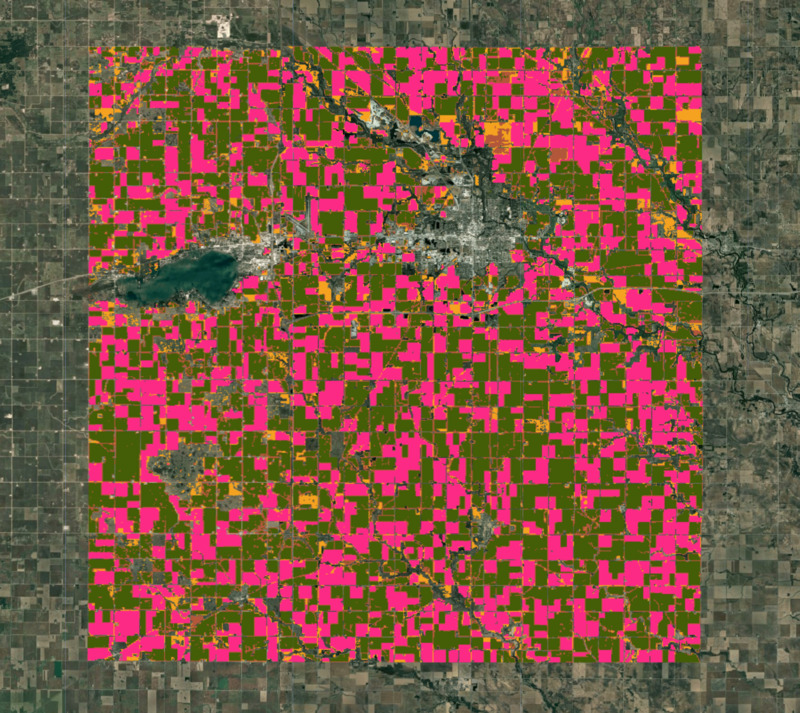
图:通过无监督分类获得的聚类
为集群分配标签
通过直观检查,我们发现上一步中获得的聚类结果与高分辨率图像中显示的农场边界非常接近。根据当地知识,我们知道最大的两个集群是玉米和大豆。我们来计算一下图片中每个聚类的面积。
// Calculate Cluster Areas
// 1 Acre = 4046.86 Sq. Meters
var areaImage = ee.Image.pixelArea().divide(4046.86).addBands(clustered);
var areas = areaImage.reduceRegion({
reducer: ee.Reducer.sum().group({
groupField: 1,
groupName: 'cluster',
}),
geometry: geometry,
scale: 10,
maxPixels: 1e10
});
var clusterAreas = ee.List(areas.get('groups'));
// Process results to extract the areas and create a FeatureCollection
var clusterAreas = clusterAreas.map(function(item) {
var areaDict = ee.Dictionary(item);
var clusterNumber = areaDict.getNumber('cluster').format();
var area = areaDict.getNumber('sum');
return ee.Feature(null, {cluster: clusterNumber, area: area});
});
var clusterAreaFc = ee.FeatureCollection(clusterAreas);
print('Cluster Areas', clusterAreaFc);
我们选择面积最大的 2 个聚类。
var selectedFc = clusterAreaFc.sort('area', false).limit(2);
print('Top 2 Clusters by Area', selectedFc);
但我们仍然不知道哪个聚类对应哪种作物。如果您有玉米或大豆的少量实地样本,则可以将其叠加到聚类上,以确定其各自的标签。在没有田间样本的情况下,我们可以利用汇总的作物统计信息。在世界许多地区,农作物统计汇总数据会定期收集和发布。对于美国,美国农业统计局 (NASS) 针对每个县和每种主要农作物都提供了详细的农作物统计数据。2022 年,爱荷华州塞罗戈多县的玉米种植面积为 161,500 英亩,大豆种植面积为 110,500 英亩。
根据这些信息,我们现在知道,在面积最大的两个聚类中,一个很可能是玉米,另一个是大豆。我们来分配这些标签,并将计算出的面积与已发布的统计信息进行比较。
var cornFeature = selectedFc.sort('area', false).first();
var soybeanFeature = selectedFc.sort('area').first();
var cornCluster = cornFeature.get('cluster');
var soybeanCluster = soybeanFeature.get('cluster');
print('Corn Area (Detected)', cornFeature.getNumber('area').round());
print('Corn Area (From Crop Statistics)', 163500);
print('Soybean Area (Detected)', soybeanFeature.getNumber('area').round());
print('Soybean Area (From Crop Statistics)', 110500);
创建裁剪地图
现在,我们已经知道每个聚类的标签,可以提取每种作物的像素,并将它们合并以创建最终的作物地图。
// Select the clusters to create the crop map
var corn = clustered.eq(ee.Number.parse(cornCluster));
var soybean = clustered.eq(ee.Number.parse(soybeanCluster));
var merged = corn.add(soybean.multiply(2));
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(merged.clip(geometry), cropVis, 'Crop Map (Detected)');
为了帮助解读结果,我们还可以使用界面元素创建图例并将其添加到地图中。
// Add a Legend
var legend = ui.Panel({
layout: ui.Panel.Layout.Flow('horizontal'),
style: {position: 'bottom-center', padding: '8px 15px'}});
var addItem = function(color, name) {
var colorBox = ui.Label({
style: {color: '#ffffff',
backgroundColor: color,
padding: '10px',
margin: '0 4px 4px 0',
}
});
var description = ui.Label({
value: name,
style: {
margin: '0px 10px 0px 2px',
}
});
return ui.Panel({
widgets: [colorBox, description],
layout: ui.Panel.Layout.Flow('horizontal')
});
};
var title = ui.Label({
value: 'Legend',
style: {
fontWeight: 'bold',
fontSize: '16px',
margin: '0px 10px 0px 4px'
}
});
legend.add(title);
legend.add(addItem('#ffd400', 'Corn'));
legend.add(addItem('#267300', 'Soybean'));
legend.add(addItem('#bdbdbd', 'Other Crops'));
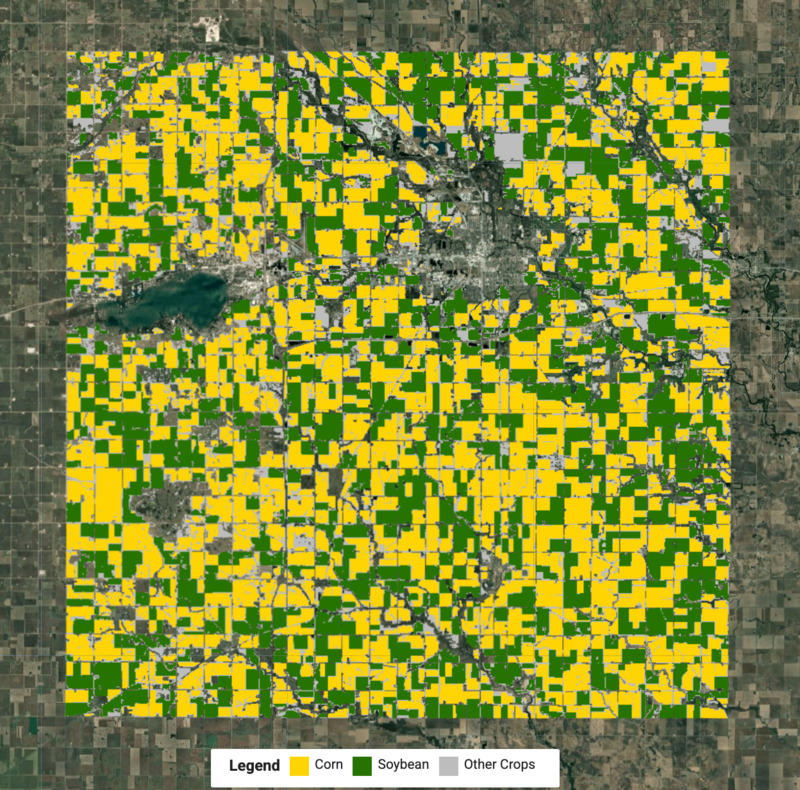
图:检测到的农作物地图,其中包含玉米和大豆农作物
验证结果
我们能够仅使用区域的汇总统计信息和本地知识,在没有任何实地标签的情况下,通过卫星嵌入数据集获得作物类型地图。接下来,我们将结果与美国农业部 NASS 作物土地数据层 (CDL) 的官方作物类型地图进行比较。
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var cropMap = cropLandcover.updateMask(croplandMask).rename('crops');
// Original data has unique values for each crop ranging from 0 to 254
var cropClasses = ee.List.sequence(0, 254);
// We remap all values as following
// Crop | Source Value | Target Value
// Corn | 1 | 1
// Soybean | 5 | 2
// All other| 0-255 | 0
var targetClasses = ee.List.repeat(0, 255).set(1, 1).set(5, 2);
var cropMapReclass = cropMap.remap(cropClasses, targetClasses).rename('crops');
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(cropMapReclass.clip(geometry), cropVis, 'Crop Landcover (CDL)');

图:(左)从卫星嵌入中剪裁地图(右)从 CDL 中剪裁地图
虽然我们的结果与官方地图存在差异,但您会发现,我们只需付出极少的努力就能获得相当不错的结果。通过对结果应用后处理步骤,我们可以移除一些噪声并填补输出中的空白。