
मकसद
ज़्यादा पतों की पुष्टि करने की सुविधा वाले ट्यूटोरियल में, आपको अलग-अलग ऐसे उदाहरण दिखाए गए हैं जिनमें इस सुविधा का इस्तेमाल किया जा सकता है. इस ट्यूटोरियल में, हम आपको Google Cloud Platform में मौजूद अलग-अलग डिज़ाइन पैटर्न के बारे में बताएंगे. इनकी मदद से, पतों की पुष्टि करने की सुविधा को बड़े पैमाने पर इस्तेमाल किया जा सकता है.
हम एक बार के लिए, Cloud Run, Compute Engine या Google Kubernetes Engine की मदद से, Google Cloud Platform में ज़्यादा पतों की पुष्टि करने की सुविधा को चलाने के बारे में खास जानकारी देंगे. इसके बाद, हम देखेंगे कि इस सुविधा को डेटा पाइपलाइन में कैसे शामिल किया जा सकता है.
इस लेख को पढ़ने के बाद, आपको Google Cloud एनवायरमेंट में बड़ी संख्या में पतों की पुष्टि करने के अलग-अलग विकल्पों के बारे में अच्छी तरह से पता चल जाएगा.
Google Cloud Platform पर रेफ़रंस आर्किटेक्चर
इस सेक्शन में, Google Cloud Platform का इस्तेमाल करके, बड़ी संख्या में पतों की पुष्टि करने के अलग-अलग डिज़ाइन पैटर्न के बारे में ज़्यादा जानकारी दी गई है. Google Cloud Platform पर चलने की वजह से, इसे अपनी मौजूदा प्रोसेस और डेटा पाइपलाइन के साथ इंटिग्रेट किया जा सकता है.
Google Cloud Platform पर, पतों की पुष्टि करने की सुविधा का इस्तेमाल एक बार करना
नीचे, Google Cloud Platform पर इंटिग्रेशन बनाने के लिए रेफ़रंस आर्किटेक्चर दिखाया गया है. यह एक बार की जाने वाली कार्रवाइयों या टेस्टिंग के लिए ज़्यादा सही है.

ऐसे में, हमारा सुझाव है कि CSV फ़ाइल को Cloud Storage बकेट में अपलोड करें. इसके बाद, ज़्यादा पतों की पुष्टि करने वाली स्क्रिप्ट को Cloud Run एनवायरमेंट से चलाया जा सकता है. हालांकि, इसे Compute Engine या Google Kubernetes Engine जैसे किसी अन्य रनटाइम एनवायरमेंट में भी चलाया जा सकता है. आउटपुट CSV फ़ाइल को Cloud Storage बकेट में भी अपलोड किया जा सकता है.
Google Cloud Platform की डेटा पाइपलाइन के तौर पर चल रहा है
पिछले सेक्शन में दिखाया गया डिप्लॉयमेंट पैटर्न, एक बार इस्तेमाल करने के लिए, बड़ी संख्या में पतों की पुष्टि करने की सुविधा को तुरंत टेस्ट करने के लिए सबसे सही है. हालांकि, अगर आपको इसका इस्तेमाल डेटा पाइपलाइन के हिस्से के तौर पर नियमित रूप से करना है, तो इसे ज़्यादा बेहतर बनाने के लिए, Google Cloud Platform की नेटिव क्षमताओं का बेहतर तरीके से फ़ायदा उठाया जा सकता है. यहां कुछ बदलाव दिए गए हैं जिन्हें किया जा सकता है:
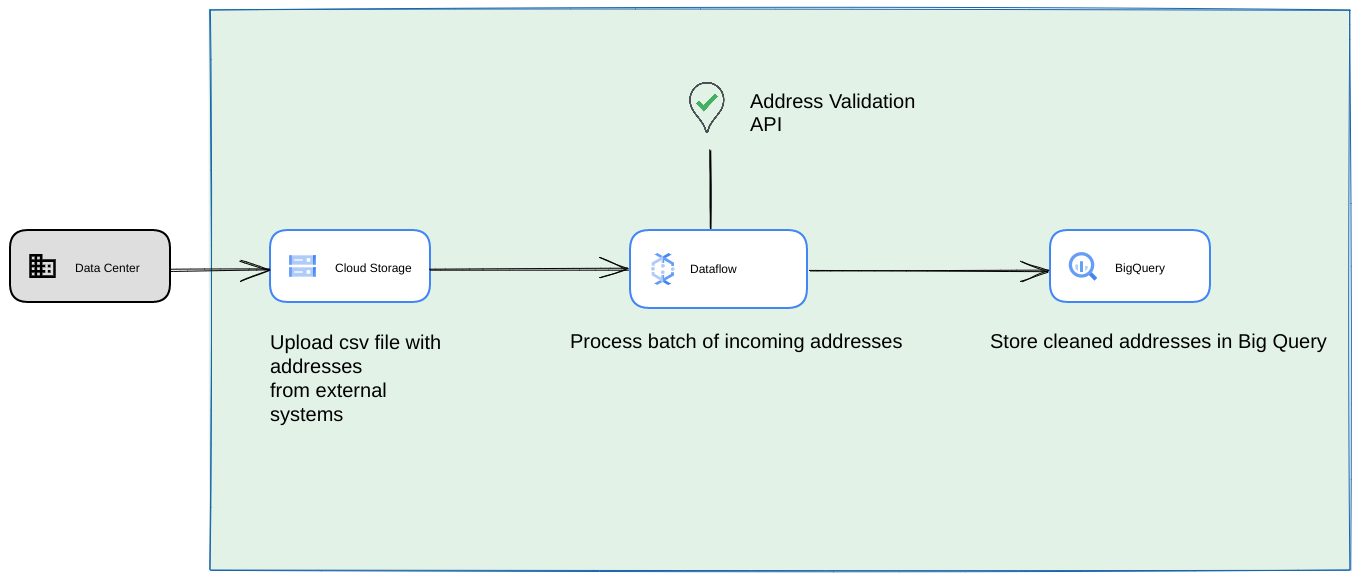
- इस मामले में, CSV फ़ाइलों को Cloud Storage बकेट में डंप किया जा सकता है.
- Dataflow जॉब, प्रोसेस किए जाने वाले पतों को चुन सकता है. इसके बाद, उन्हें BigQuery में कैश मेमोरी में सेव कर सकता है.
- Dataflow Python लाइब्रेरी को बढ़ाया जा सकता है, ताकि इसमें ज़्यादा पतों की पुष्टि करने की सुविधा के लिए लॉजिक शामिल किया जा सके. इससे Dataflow जॉब से मिले पतों की पुष्टि की जा सकेगी.
डेटा पाइपलाइन से स्क्रिप्ट को लंबे समय तक चलने वाली बार-बार होने वाली प्रोसेस के तौर पर चलाना
एक और सामान्य तरीका यह है कि बार-बार होने वाली प्रोसेस के तौर पर, स्ट्रीमिंग डेटा पाइपलाइन के हिस्से के तौर पर पतों के एक बैच की पुष्टि की जाए. आपके पास BigQuery डेटास्टोर में भी पते हो सकते हैं. इस तरीके में, हम यह देखेंगे कि बार-बार होने वाली डेटा पाइपलाइन (जिसे रोज़/हर हफ़्ते/हर महीने ट्रिगर करने की ज़रूरत होती है) कैसे बनाई जाती है
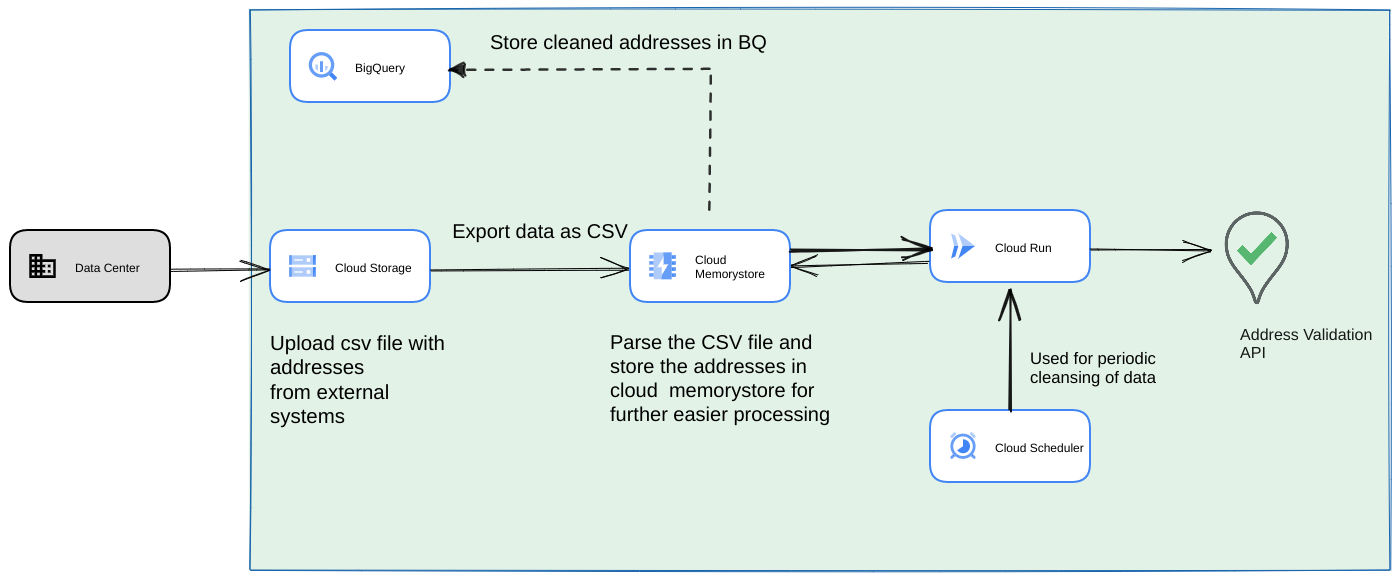
- शुरुआती CSV फ़ाइल को Cloud Storage बकेट में अपलोड करें.
- लंबे समय तक चलने वाली प्रोसेस के लिए, इंटरमीडिएट स्टेट को बनाए रखने के लिए, Memorystore का इस्तेमाल लगातार डेटा स्टोर करने वाले डेटास्टोर के तौर पर करें.
- BigQuery डेटास्टोर में फ़ाइनल पतों को कैश मेमोरी में सेव करें.
- स्क्रिप्ट को समय-समय पर चलाने के लिए, Cloud Scheduler सेट अप करें.
इस आर्किटेक्चर के ये फ़ायदे हैं:
- Cloud Scheduler का इस्तेमाल करके, पते की पुष्टि समय-समय पर की जा सकती है. आपको हर महीने पतों की फिर से पुष्टि करनी पड़ सकती है. इसके अलावा, आपको हर महीने या हर तीन महीने में नए पतों की पुष्टि करनी पड़ सकती है. इस आर्किटेक्चर से, इस्तेमाल के इस उदाहरण को हल करने में मदद मिलती है.
अगर ग्राहक का डेटा BigQuery में है, तो पुष्टि किए गए पतों या पुष्टि करने वाले फ़्लैग को सीधे तौर पर वहां कैश मेमोरी में सेव किया जा सकता है. ध्यान दें: ज़्यादा पतों की पुष्टि करने की सुविधा के बारे में लेख में, इस बारे में ज़्यादा जानकारी दी गई है कि किन चीज़ों को कैश मेमोरी में सेव किया जा सकता है और कैसे किया जा सकता है
Memorystore का इस्तेमाल करने से, ज़्यादा पतों को प्रोसेस किया जा सकता है और बेहतर तरीके से काम किया जा सकता है. इस चरण से, पूरी प्रोसेसिंग पाइपलाइन में स्टेटफ़ुलनेस जुड़ जाती है. यह बहुत बड़े पते वाले डेटासेट को मैनेज करने के लिए ज़रूरी है. यहां cloud SQL[https://cloud.google.com/sql] जैसी अन्य डेटाबेस टेक्नोलॉजी या Google Cloud Platform की ओर से ऑफ़र किए जाने वाले डेटाबेस के किसी अन्य वर्शन का भी इस्तेमाल किया जा सकता है. हालांकि, हमारा मानना है कि Memorystore, स्केलिंग और इस्तेमाल में आसानी से जुड़ी ज़रूरतों को पूरा करता है. इसलिए, इसे पहली पसंद के तौर पर चुना जाना चाहिए.
नतीजा
यहां बताए गए पैटर्न लागू करके, Address Validation API का इस्तेमाल अलग-अलग कामों के लिए किया जा सकता है. साथ ही, Google Cloud Platform पर अलग-अलग कामों के लिए भी इसका इस्तेमाल किया जा सकता है.
हमने एक ओपन-सोर्स Python लाइब्रेरी लिखी है, ताकि ऊपर बताए गए इस्तेमाल के उदाहरणों को शुरू करने में आपकी मदद की जा सके. इसे अपने कंप्यूटर पर कमांड लाइन से शुरू किया जा सकता है. इसके अलावा, इसे Google Cloud Platform या अन्य क्लाउड सेवा देने वाली कंपनियों से भी शुरू किया जा सकता है.
इस लेख में, लाइब्रेरी का इस्तेमाल करने के तरीके के बारे में ज़्यादा जानें.
अगले चरण
सही पतों की मदद से, चेकआउट, डिलीवरी, और ऑपरेशंस को बेहतर बनाएं व्हाइटपेपर डाउनलोड करें. साथ ही, पते की पुष्टि करने की सुविधा की मदद से, चेकआउट, डिलीवरी, और ऑपरेशंस को बेहतर बनाना वेबिनार देखें.
इस बारे में और पढ़ें:
- Address Validation API के बारे में जानकारी देने वाला दस्तावेज़
- जियोकोडिंग और पते की पुष्टि करना
- Address Validation का डेमो देखें
योगदानकर्ता
Google इस लेख को मैनेज करता है. इस लेख को इन योगदानकर्ताओं ने लिखा है.
मुख्य लेखक:
हेनरिक वाल्व | सलूशन इंजीनियर
थॉमस ऐंगलरेट | सलूशन इंजीनियर
सार्थक गांगुली | सलूशन इंजीनियर