
目标
高容量地址验证教程介绍了可以使用高容量地址验证的不同场景。在本教程中,我们将向您介绍 Google Cloud Platform 中用于运行高容量地址验证的不同设计模式。
我们将首先概述如何在 Google Cloud Platform 中使用 Cloud Run、Compute Engine 或 Google Kubernetes Engine 运行高容量地址验证,以进行一次性执行。然后,我们将了解如何将此功能纳入数据流水线。
读完本文后,您应该能够很好地了解在 Google Cloud 环境中以高容量运行地址验证的不同选项。
Google Cloud Platform 上的参考架构
本部分将深入探讨使用 Google Cloud Platform 进行大批量地址验证的不同设计模式。通过在 Google Cloud Platform 上运行,您可以与现有流程和数据流水线集成。
在 Google Cloud Platform 上运行一次高容量地址验证
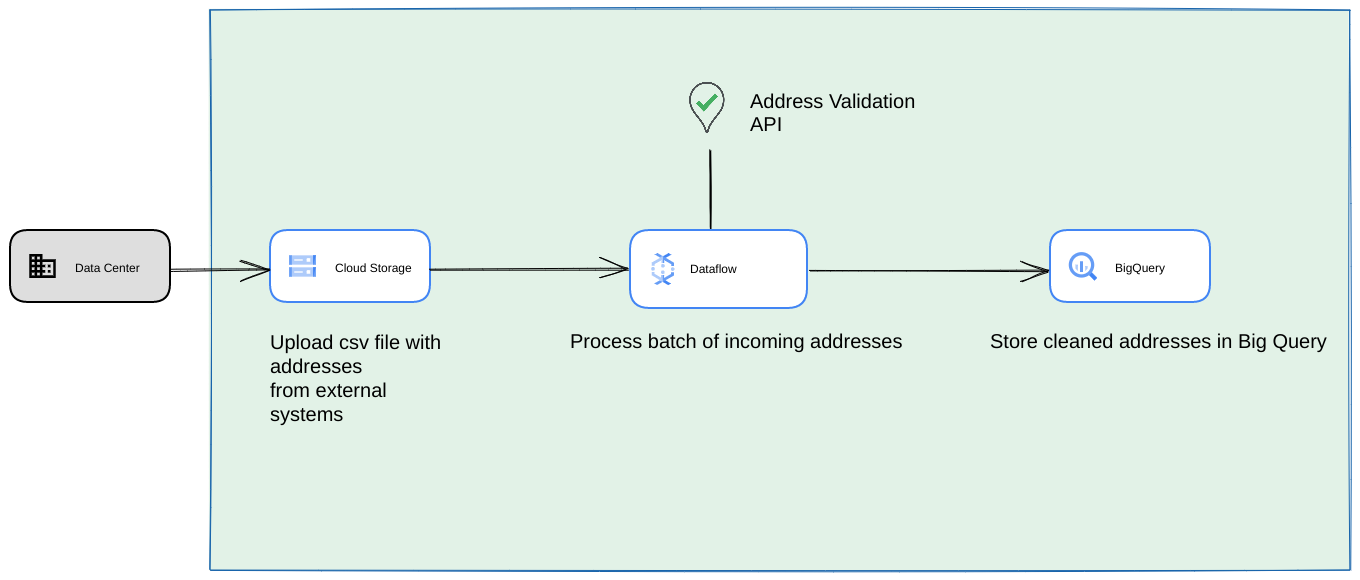
下图展示了如何在 Google Cloud Platform 上构建更适合一次性操作或测试的集成。

在这种情况下,我们建议您将 CSV 文件上传到 Cloud Storage 存储分区。然后,您可以从 Cloud Run 环境运行高容量地址验证脚本。不过,您可以在任何其他运行时环境(例如 Compute Engine 或 Google Kubernetes Engine)中执行它。输出 CSV 还可以上传到 Cloud Storage 存储分区。
作为 Google Cloud Platform 数据流水线运行
上一部分中显示的部署模式非常适合快速测试一次性使用的高容量地址验证。不过,如果您需要经常在数据流水线中使用它,那么可以更好地利用 Google Cloud Platform 原生功能来增强其稳健性。您可以进行的一些更改包括:
- 在这种情况下,您可以将 CSV 文件转储到 Cloud Storage 存储分区中。
- Dataflow 作业可以提取要处理的地址,然后将其缓存在 BigQuery 中。
- 可以扩展 Dataflow Python 库,使其包含大批量地址验证的逻辑,以验证 Dataflow 作业中的地址。
从数据流水线运行脚本,作为长期运行的周期性进程
另一种常见方法是在流式数据流水线中验证一批地址,作为一种定期执行的流程。您还可以在 BigQuery 数据存储区中存储地址。在此方法中,我们将了解如何构建需要每天/每周/每月触发的周期性数据流水线
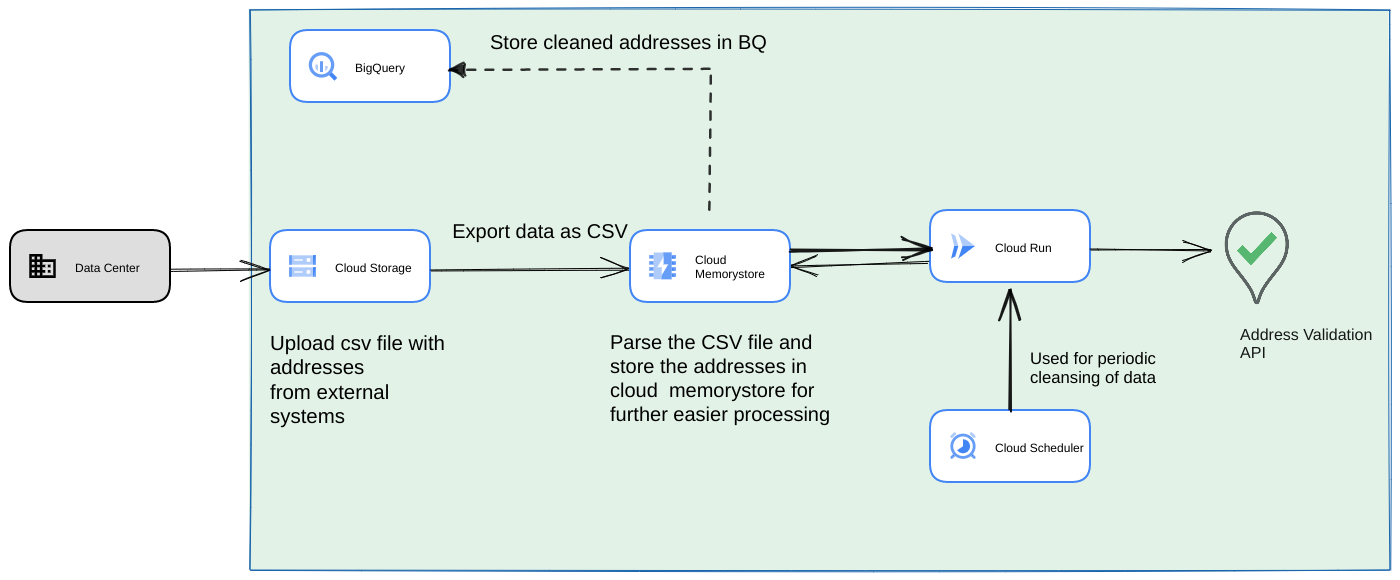
- 将初始 CSV 文件上传到 Cloud Storage 存储分区。
- 使用 Memorystore 作为持久性数据存储区,以维护长时间运行的进程的中间状态。
- 将最终地址缓存到 BigQuery 数据存储区中。
- 设置 Cloud Scheduler 以定期运行脚本。
此架构具有以下优势:
- 借助 Cloud Scheduler,可以定期进行地址验证。您可能需要每月重新验证地址,或者每月/每季度验证所有新地址。此架构有助于解决该用例。
如果客户数据位于 BigQuery 中,则可以直接在其中缓存经过验证的地址或验证标志。 注意:大批量地址验证文章详细介绍了可以缓存的内容以及缓存方式。
使用 Memorystore 可提供更高的恢复能力,并能够处理更多地址。此步骤为整个处理流水线添加了状态,这对于处理非常大的地址数据集是必需的。您也可以在此处使用其他数据库技术,例如 Cloud SQL[https://cloud.google.com/sql] 或 Google Cloud Platform 提供的任何其他数据库类型。不过,我们认为 Memorystore 完美地平衡了扩缩和简单性需求,因此应该是首选。
总结
通过应用此处所述的模式,您可以在 Google Cloud Platform 上针对不同的用例使用 Address Validation API。
我们编写了一个开源 Python 库,可帮助您开始使用上述应用场景。您可以从计算机上的命令行调用该工具,也可以从 Google Cloud Platform 或其他云服务提供商调用该工具。
如需详细了解如何使用该库,请参阅这篇文章。
后续步骤
下载通过可靠的地址提升结账、配送和运营效率 白皮书,并观看通过地址验证提升结账、配送和运营效率 在线讲座。
建议的进一步阅读内容:
贡献者
Google 负责维护本文。以下贡献者最初撰写了此内容。
主要作者:
Henrik Valve | 解决方案工程师
Thomas Anglaret | 解决方案工程师
Sarthak Ganguly | 解决方案工程师