
Objetivo
O tutorial sobre a API High Volume Address Validation orientou você em diferentes cenários em que a validação de endereços de alto volume pode ser usada. Neste tutorial, vamos apresentar diferentes padrões de design no Google Cloud Platform para executar a API High Volume Address Validation.
Vamos começar com uma visão geral da execução da API High Volume Address Validation no Google Cloud Platform com o Cloud Run, o Compute Engine ou o Google Kubernetes Engine para execuções únicas. Em seguida, vamos mostrar como essa capacidade pode ser incluída como parte de um pipeline de dados.
Ao final deste artigo, você terá uma boa compreensão das diferentes opções para executar a API Address Validation em alto volume no ambiente do Google Cloud.
Arquitetura de referência no Google Cloud Platform
Esta seção aborda diferentes padrões de design para a API High Volume Address Validation usando o Google Cloud Platform. Ao executar no Google Cloud Platform, você pode fazer a integração com seus processos e pipelines de dados atuais.
Executar a API High Volume Address Validation uma vez no Google Cloud Platform
Abaixo, mostramos uma arquitetura de referência de como criar uma integração no Google Cloud Platform mais adequada para operações ou testes únicos.

Nesse caso, recomendamos fazer o upload do arquivo CSV para um bucket do Cloud Storage. O script da API High Volume Address Validation pode ser executado em um ambiente do Cloud Run. No entanto, é possível executá-lo em qualquer outro ambiente de execução, como o Compute Engine ou o Google Kubernetes Engine. O CSV de saída também pode ser enviado para o bucket do Cloud Storage.
Executar como um pipeline de dados do Google Cloud Platform
O padrão de implantação mostrado na seção anterior é ótimo para testar rapidamente a API High Volume Address Validation para uso único. No entanto, se você precisar usá-la regularmente como parte de um pipeline de dados, poderá aproveitar melhor os recursos nativos do Google Cloud Platform para torná-la mais robusta. Algumas das mudanças que você pode fazer incluem:
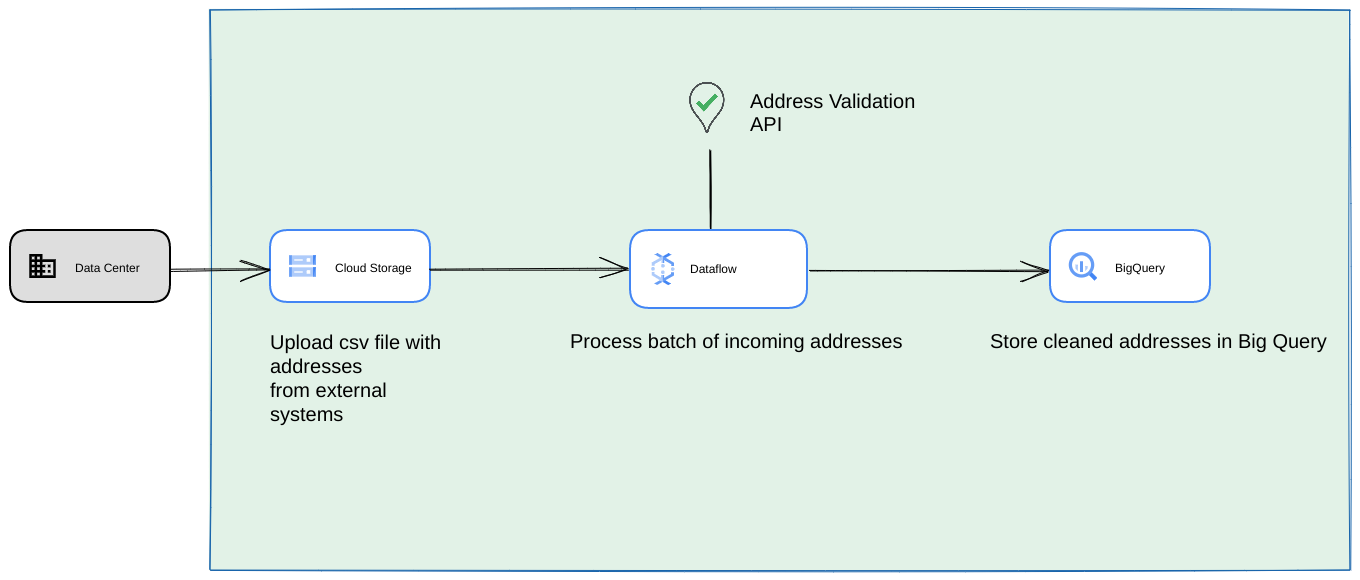
- Nesse caso, você pode despejar arquivos CSV em buckets do Cloud Storage.
- Um job do Dataflow pode selecionar os endereços a serem processados e armazenar em cache no BigQuery.
- A biblioteca Python do Dataflow pode ser estendida para ter lógica para a API High Volume Address Validation validar os endereços do job do Dataflow.
Executar o script de um pipeline de dados como um processo recorrente de longa duração
Outra abordagem comum é validar um lote de endereços como parte de um pipeline de dados de streaming como um processo recorrente. Você também pode ter os endereços em um armazenamento de dados do BigQuery. Nessa abordagem, vamos mostrar como criar um pipeline de dados recorrente (que precisa ser acionado diariamente/semanalmente/mensalmente).
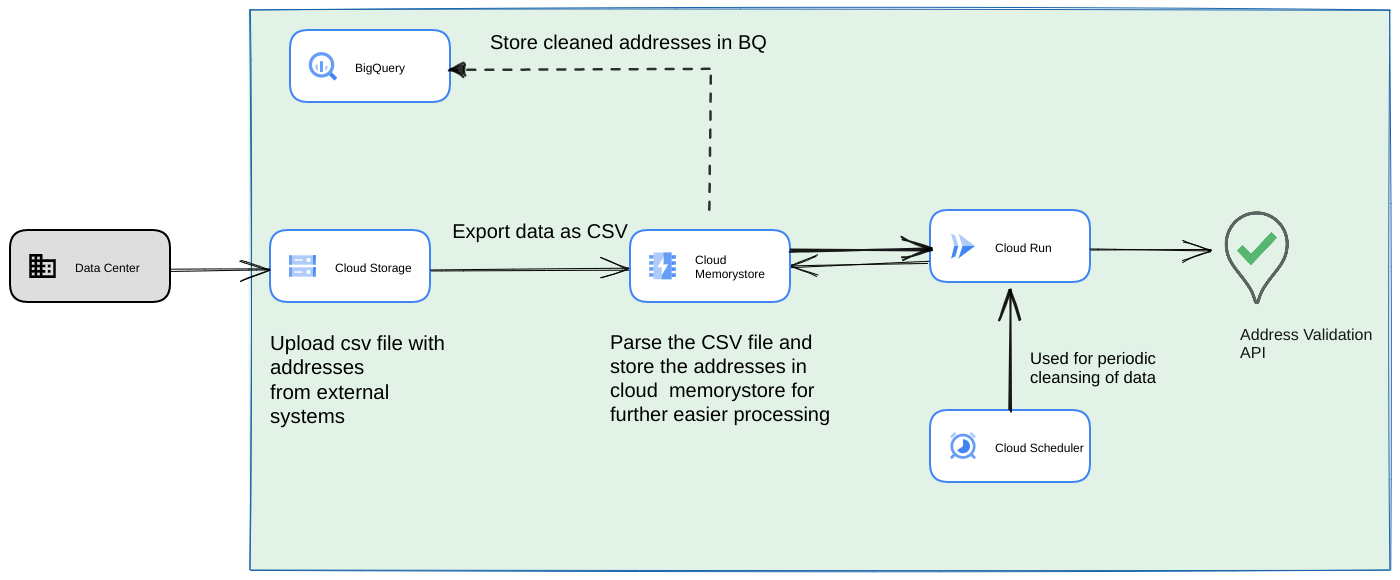
- Faça o upload do arquivo CSV inicial para um Cloud Storage bucket.
- Use o Memorystore como um repositório de dados persistente para manter o estado intermediário do processo de longa duração.
- Armazene em cache os endereços finais em um BigQuery repositório de dados.
- Configure o Cloud Scheduler para executar o script periodicamente.
Essa arquitetura tem as seguintes vantagens:
- Usando o Cloud Scheduler, a validação de endereços pode ser feita periodicamente. Talvez você queira validar novamente os endereços mensalmente ou validar novos endereços mensalmente/trimestralmente. Essa arquitetura ajuda a resolver esse caso de uso.
Se os dados do cliente estiverem no BigQuery, os endereços validados ou as flags de validação poderão ser armazenados em cache diretamente. Observação: o que pode ser armazenado em cache e como é descrito em detalhes no artigo da API High Volume Address Validation.
O uso do Memorystore oferece maior resiliência e capacidade de processar mais endereços. Essa etapa adiciona um estado a todo o pipeline de processamento, que é necessário para processar conjuntos de dados de endereços muito grandes. Outras tecnologias de banco de dados, como o Cloud SQL[https://cloud.google.com/sql] ou qualquer outro tipo de banco de dados oferecido pelo Google Cloud Platform, também podem ser usadas aqui. No entanto, acreditamos que o Memorystore equilibra perfeitamente as necessidades de escalonamento e simplicidade, portanto, deve ser a primeira opção.
Conclusão
Ao aplicar os padrões descritos aqui, você pode usar a API Address Validation para diferentes casos de uso no Google Cloud Platform.
Criamos uma biblioteca Python de código aberto para ajudar você a começar a usar os casos de uso descritos acima. Ela pode ser invocada em uma linha de comando no seu computador ou no Google Cloud Platform ou em outros provedores de nuvem.
Saiba mais sobre como usar a biblioteca neste artigo.
Próximas etapas
Faça o download do white paper Melhorar o checkout, a entrega e as operações com endereços confiáveis e assista ao webinar Melhorar o checkout, a entrega e as operações com a API Address Validation .
Sugestões de leitura adicional:
- Documentação da API Address Validation
- Geocodificação e Address Validation
- Conheça a demonstração da API Address Validation
Colaboradores
O Google mantém este artigo. Os colaboradores a seguir escreveram o artigo originalmente.
Principais autores:
Henrik Valve | Engenheiro de soluções
Thomas Anglaret | Engenheiro de soluções
Sarthak Ganguly | Engenheiro de soluções