
В этом документе вы узнаете, как использовать примеры данных об идентификаторах мест из Places Insights , применять функции подсчета мест , а также выполнять целевой поиск по подробным сведениям о местах, чтобы повысить достоверность результатов.
Подробную демонстрацию этого шаблона см. в этом пояснительном блокноте:
 Посмотреть исходный код на GitHub
Посмотреть исходный код на GitHub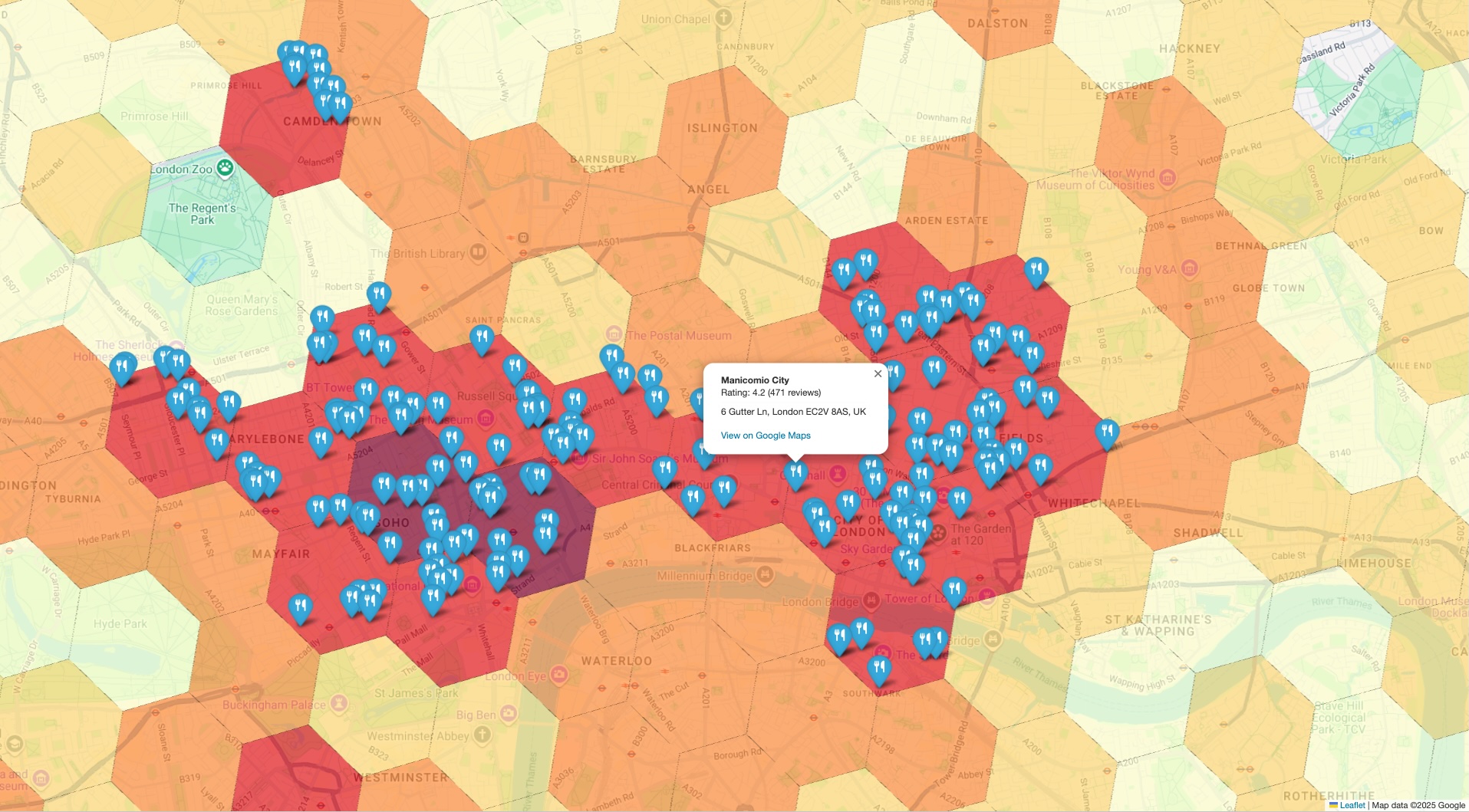
Архитектурный образец
Эта архитектурная модель обеспечивает повторяемый рабочий процесс, позволяющий преодолеть разрыв между высокоуровневым статистическим анализом и проверкой достоверности данных. Сочетая масштаб BigQuery с точностью Places API , вы можете с уверенностью подтверждать результаты анализа. Это особенно полезно для выбора местоположения, анализа конкурентов и маркетинговых исследований, где доверие к данным имеет первостепенное значение.
В основе этой схемы лежат четыре ключевых шага:
- Проведите масштабный анализ: используйте функцию подсчета мест из раздела «Аналитика мест» в BigQuery для анализа данных о местах на обширной территории, например, в целом городе или регионе.
- Выделение и извлечение образцов: Определите интересующие области (например, «горячие точки» с высокой плотностью) из агрегированных результатов и извлеките идентификаторы
sample_place_ids, предоставленные функцией. - Получение достоверных данных: используйте извлеченные идентификаторы мест для целевых запросов к API сведений о местах, чтобы получить подробную информацию о каждом месте, соответствующую реальному миру.
- Создайте комбинированную визуализацию: наложите подробные данные о населенных пунктах на исходную статистическую карту высокого уровня, чтобы визуально убедиться, что агрегированные данные отражают реальную ситуацию на местах.
Рабочий процесс решения
Этот рабочий процесс позволяет преодолеть разрыв между макроэкономическими тенденциями и микроэкономическими фактами. Вы начинаете с общего статистического обзора и стратегически углубляетесь в детали, чтобы проверить данные с помощью конкретных примеров из реальной жизни.
Анализ плотности застройки в масштабе с помощью Places Insights
Первым шагом является понимание общей картины. Вместо того чтобы получать данные о тысячах отдельных точек интереса (POI), вы можете выполнить один запрос для получения статистической сводки.
Функция Places Insights PLACES_COUNT_PER_H3 идеально подходит для этой цели. Она агрегирует данные о количестве объектов интереса в гексагональную сетку (H3) , позволяя быстро определять зоны с высокой или низкой плотностью на основе ваших конкретных критериев (например, работающие рестораны с высоким рейтингом).
Пример запроса выглядит следующим образом. Обратите внимание, что вам потребуется указать географическую область поиска. Для получения данных о географических границах можно использовать открытый набор данных, например, общедоступный набор данных Overture Maps Data BigQuery.
Для границ часто используемых открытых наборов данных мы рекомендуем материализовать их в таблицу в вашем собственном проекте. Это значительно снижает затраты на BigQuery и повышает производительность запросов.
-- This query counts all highly-rated, operational restaurants
-- across a large geography, grouping them into H3 cells.
SELECT *
FROM
`places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'types', ['restaurant'],
'business_status', ['OPERATIONAL'],
'min_rating', 3.5
)
);
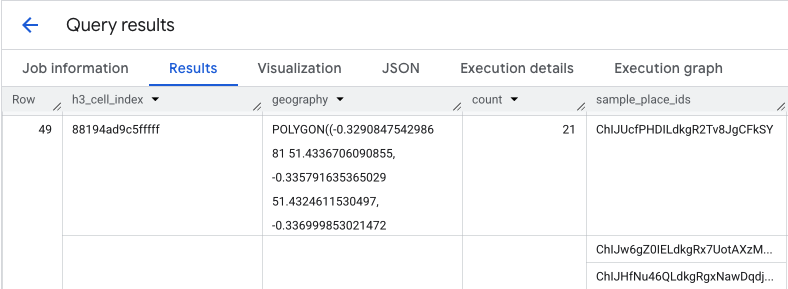
Результатом этого запроса является таблица ячеек H3 и количество мест в каждой из них, которая служит основой для тепловой карты плотности.
Выделить очаги активности и извлечь идентификаторы мест отбора проб.
Результат функции PLACES_COUNT_PER_H3 также возвращает массив sample_place_ids , содержащий до 250 идентификаторов мест на каждый элемент ответа. Эти идентификаторы являются связующим звеном между агрегированной статистикой и отдельными местами, которые вносят в нее свой вклад.
Ваша система может сначала определить наиболее релевантные ячейки из первоначального запроса. Например, вы можете выбрать 20 ячеек с наибольшим количеством совпадений. Затем из этих «горячих точек» вы объединяете sample_place_ids в единый список. Этот список представляет собой тщательно отобранную выборку наиболее интересных точек интереса из наиболее релевантных областей, подготавливая вас к целевой проверке.
Если вы обрабатываете результаты BigQuery в Python с помощью DataFrame pandas, логика извлечения этих идентификаторов довольно проста:
# Assume 'results_df' is a pandas DataFrame from your BigQuery query.
# 1. Identify the 20 busiest H3 cells by sorting and taking the top results.
top_hotspots_df = results_df.sort_values(by='count', ascending=False).head(20)
# 2. Extract and flatten the lists of sample_place_ids from these hotspots.
# The .explode() function creates a new row for each ID in the lists.
all_sample_ids = top_hotspots_df['sample_place_ids'].explode()
# 3. Create a final list of unique Place IDs to verify.
place_ids_to_verify = all_sample_ids.unique().tolist()
print(f"Consolidated {len(place_ids_to_verify)} unique Place IDs for spot-checking.")
Аналогичная логика применима и при использовании других языков программирования.
Получите достоверные данные о местоположении с помощью API Places.
Имея сводный список идентификаторов мест, вы переходите от крупномасштабной аналитики к извлечению конкретных данных. Вы будете использовать эти идентификаторы для запроса к API сведений о местах, чтобы получить подробную информацию о каждом примере местоположения.
Это критически важный этап проверки. Если Places Insights сообщал вам, сколько ресторанов находится в определенном районе, то Places API сообщает вам, какие именно рестораны это, предоставляя их название, точный адрес, широту/долготу, рейтинг пользователей и даже прямую ссылку на их местоположение на Google Maps. Это обогащает ваши тестовые данные, превращая абстрактные идентификаторы в конкретные, проверяемые места.
Полный список данных, доступных через API Place Details, а также стоимость их получения, см. в документации API .
Запрос к Places API для получения определенного ID с использованием клиентской библиотеки Python будет выглядеть следующим образом. Более подробную информацию см. в примерах использования клиентской библиотеки Places API (новая версия) .
# A request to fetch details for a single Place ID.
request = {"name": f"places/{place_id}"}
# Define the fields you want returned in the response as a comma-separated string.
fields_to_request = "formattedAddress,location,displayName,googleMapsUri"
# The response contains ground truth data.
response = places_client.get_place(
request=request,
metadata=[("x-goog-fieldmask", fields_to_request)]
)
Обратите внимание, что поля в этом запросе извлекают данные из двух разных платежных SKU.
- Адрес и
locationformattedAddressявляются частью основного функционала Place Details Essentials SKU . -
displayNameиgoogleMapsUriвходят в состав пакета Place Details Pro .
Если один запрос на получение сведений о месте размещения включает поля из нескольких артикулов, то весь запрос оплачивается по тарифу артикула самого высокого уровня. Следовательно, этот конкретный запрос будет оплачиваться как запрос Place Details Pro.
Для контроля затрат всегда используйте FieldMask , чтобы запрашивать только те поля, которые необходимы вашему приложению.
Создайте комбинированную визуализацию для проверки.
Последний шаг — объединить оба набора данных в единое представление. Это обеспечивает быстрый и интуитивно понятный способ выборочной проверки вашего первоначального анализа. Ваша визуализация должна состоять из двух слоев:
- Базовый слой: хорплетная карта или тепловая карта, созданная на основе первоначальных результатов
PLACES_COUNT_PER_H3, показывающая общую плотность населенных пунктов на вашей территории. - Верхний слой: набор отдельных маркеров для каждой исследуемой точки интереса, нанесенных на карту с использованием точных координат, полученных из API Places на предыдущем шаге.
Логика построения этого объединенного представления представлена в следующем примере псевдокода:
# Assume 'h3_density_data' is your aggregated data from Step 1.
# Assume 'detailed_places_data' is your list of place objects from Step 3.
# Create the base choropleth map from the H3 density data.
# The 'count' column determines the color of each hexagon.
combined_map = create_choropleth_map(
data=h3_density_data,
color_by_column='count'
)
# Iterate through the detailed place data to add individual markers.
for place in detailed_places_data:
# Construct the popup information with key details and a link.
popup_html = f"""
<b>{place.name}</b><br>
Address: {place.address}<br>
<a href="{place.google_maps_uri}" target="_blank">View on Maps</a>
"""
# Add a marker for the current place to the base map.
combined_map.add_marker(
location=[place.latitude, place.longitude],
popup=popup_html,
tooltip=place.name
)
# Display the final map with both layers.
display(combined_map)
Наложив на карту плотности населения конкретные, достоверные маркеры, вы можете мгновенно подтвердить, что области, обозначенные как «горячие точки», действительно содержат высокую концентрацию анализируемых вами мест. Это визуальное подтверждение значительно повышает доверие к вашим выводам, основанным на данных.
Заключение
Эта архитектурная модель обеспечивает надежный и эффективный метод проверки крупномасштабных геопространственных данных. Используя Places Insights для широкого масштабируемого анализа и API Place Details для целевой проверки достоверности данных, вы создаете мощную обратную связь. Это гарантирует, что ваши стратегические решения, будь то выбор места для розничной торговли или планирование логистики, будут основаны на данных, которые не только статистически значимы, но и поддаются проверке.
Следующие шаги
- Изучите другие функции подсчета разрядов, чтобы увидеть, как они могут отвечать на различные аналитические вопросы.
- Ознакомьтесь с документацией по API Places , чтобы узнать о других полях, которые вы можете запросить для дальнейшего обогащения анализа.
Авторы
Хенрик Вэлв | Инженер DevX