
Optymalizacja wydajności rozpoczyna się od identyfikacji kluczowych wskaźników, zwykle związanych z czasem oczekiwania i przepustowością. Zastosowanie monitorowania w celu wychwytywania i śledzenia tych wskaźników naraża słabe punkty aplikacji. Dzięki danym można optymalizować wskaźniki skuteczności.
Poza tym wiele narzędzi do monitorowania pozwala skonfigurować alerty wskaźników, dzięki czemu otrzymasz powiadomienie, gdy osiągniesz określony próg. Możesz na przykład skonfigurować alert powiadamiający, gdy odsetek nieudanych żądań wzrośnie o ponad x% normalnych poziomów. Narzędzia do monitorowania pomagają określić, jak wygląda normalna wydajność, a także zidentyfikować nietypowe skoki czasu oczekiwania, liczbę błędów i inne kluczowe wskaźniki. Możliwość monitorowania tych wskaźników jest szczególnie ważna w okresach o krytycznym znaczeniu biznesowym lub po przesłaniu nowego kodu do środowiska produkcyjnego.
Identyfikowanie wskaźników czasu oczekiwania
Dopilnuj, aby interfejs był jak najbardziej elastyczny i pamiętaj, że użytkownicy oczekują od aplikacji mobilnych jeszcze wyższych standardów. Czas oczekiwania powinien być mierzony i śledzony również w przypadku usług backendu, zwłaszcza że niezaznaczenie tego pola może spowodować problemy z przepustowością.
Zalecane dane, które warto śledzić:
- Czas trwania żądania
- Czas trwania żądania na poziomie szczegółowości podsystemu (np. wywołania interfejsu API)
- Czas trwania zadania
Określ wskaźniki przepustowości
Przepustowość to miara łącznej liczby żądań wyświetlonych w danym okresie. Czas oczekiwania w podsystemach może wpływać na przepustowość, dlatego w celu zwiększenia przepustowości może być konieczna optymalizacja pod kątem czasu oczekiwania.
Oto kilka zalecanych danych, które warto śledzić:
- Zapytania na sekundę
- Wielkość przesyłanych danych w ciągu sekundy
- Liczba operacji wejścia-wyjścia na sekundę
- Wykorzystanie zasobów, na przykład wykorzystanie procesora lub pamięci
- Wielkość zaległości przetwarzania, na przykład Pub/Sub lub liczba wątków.
Nie tylko złośliwość
Częstym błędem pomiaru skuteczności jest uwzględnianie tylko przypadków średniej (średniej). Jest to przydatne, ale nie umożliwia wglądu w rozkład czasu oczekiwania. Lepszymi danymi do śledzenia są percentyle wydajności, np. 50/75/90/99 centyl danych.
Ogólnie optymalizację można wykonać w dwóch krokach. Po pierwsze, zoptymalizuj 90 centyl czasu oczekiwania. Następnie weź pod uwagę 99 centyl (nazywany czasem „opóźnieniem ogona”) – niewielką część żądań, których realizacja trwa znacznie dłużej.
Monitorowanie po stronie serwera w celu uzyskania szczegółowych wyników
W przypadku śledzenia wskaźników preferowane jest profilowanie po stronie serwera. Znacznie łatwiej jest przymierzyć dane po stronie serwera, uzyskać dostęp do bardziej szczegółowych danych i w mniejszym stopniu ulegaćzakłóceniom w związku z problemami z połączeniem.
Monitorowanie przeglądarki pod kątem kompleksowej widoczności
Profilowanie przeglądarek umożliwia uzyskanie dodatkowych informacji o wrażeniach użytkownika. Może pokazać, które strony mają powolne żądania. Możesz je następnie powiązać z monitorowaniem po stronie serwera w celu dalszej analizy.
Google Analytics umożliwia gotowe monitorowanie czasów wczytywania stron w raporcie Szybkość wczytywania strony. Znajdziesz tu kilka przydatnych widoków, które pomogą Ci zrozumieć wrażenia użytkowników witryny, w szczególności:
- Czasy wczytywania strony
- Czasy wczytywania przekierowań
- Czasy reakcji serwera
Monitorowanie w chmurze
Do rejestrowania i monitorowania danych o wydajności aplikacji możesz używać wielu narzędzi. Możesz na przykład użyć Google Cloud Logging, aby rejestrować wskaźniki wydajności w projekcie Google Cloud, a następnie skonfigurować panele w Google Cloud Monitoring, aby monitorować i segmentować zarejestrowane wskaźniki.
Zapoznaj się z przewodnikiem dotyczącym logowania, w którym znajdziesz przykład logowania do Google Cloud Logging z niestandardowego elementu przechwytującego w bibliotece klienta w Pythonie. Gdy dane te są dostępne w Google Cloud, możesz na nich kompilować wskaźniki, aby uzyskać wgląd w aplikację za pomocą Google Cloud Monitoring. Postępuj zgodnie z przewodnikiem po zdefiniowanych przez użytkownika wskaźnikach opartych na logach, aby utworzyć wskaźniki przy użyciu logów wysyłanych do Google Cloud Logging.
Możesz też użyć bibliotek klienta Monitoring, aby zdefiniować wskaźniki w kodzie i wysłać je bezpośrednio do usługi Monitoring niezależnie od logów.
Przykład wskaźników opartych na logach
Załóżmy, że chcesz monitorować wartość is_fault, aby lepiej rozumieć odsetek błędów w aplikacji. Wartość is_fault z logów możesz wyodrębnić do nowego wskaźnika licznika ErrorCount.
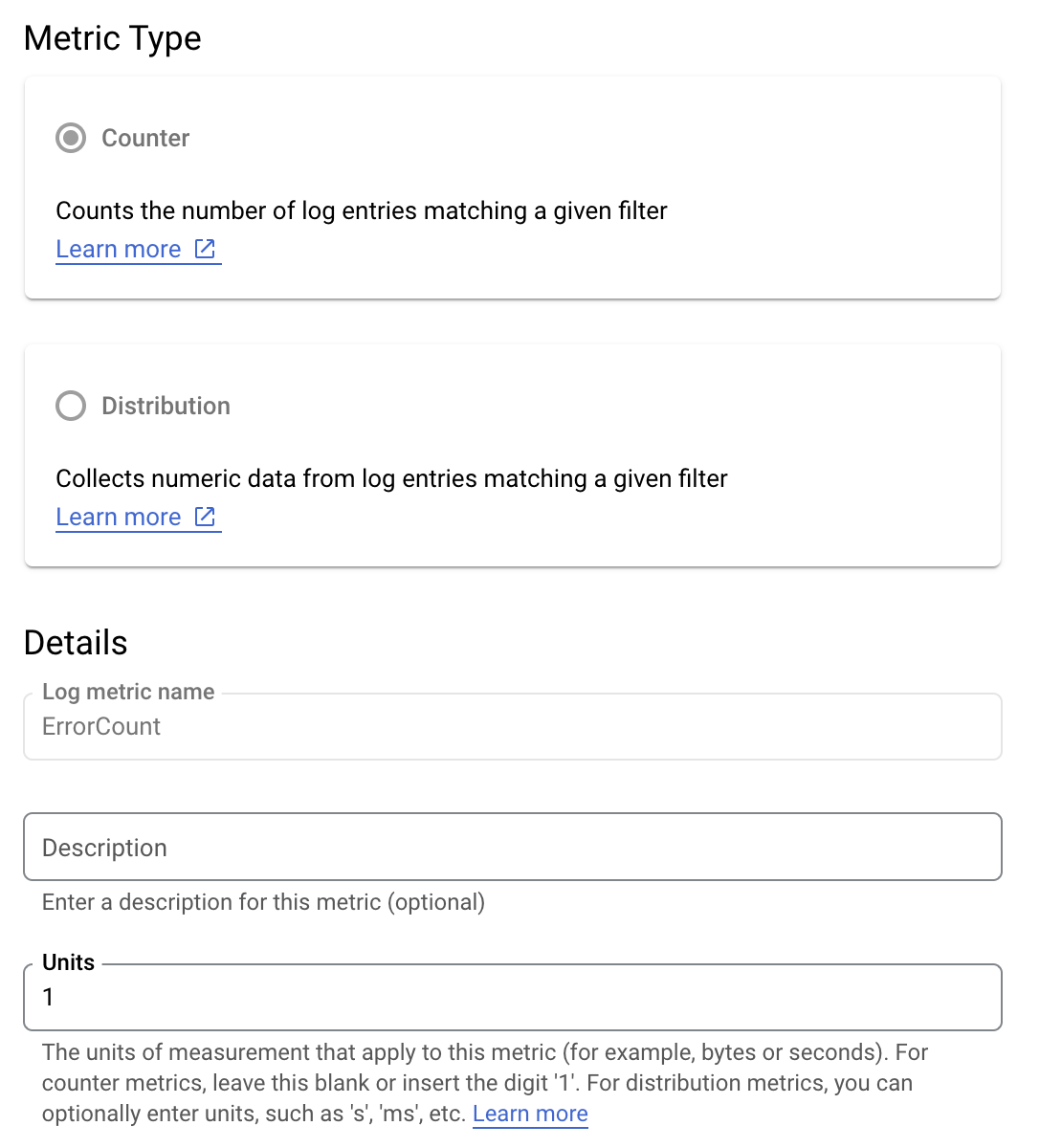
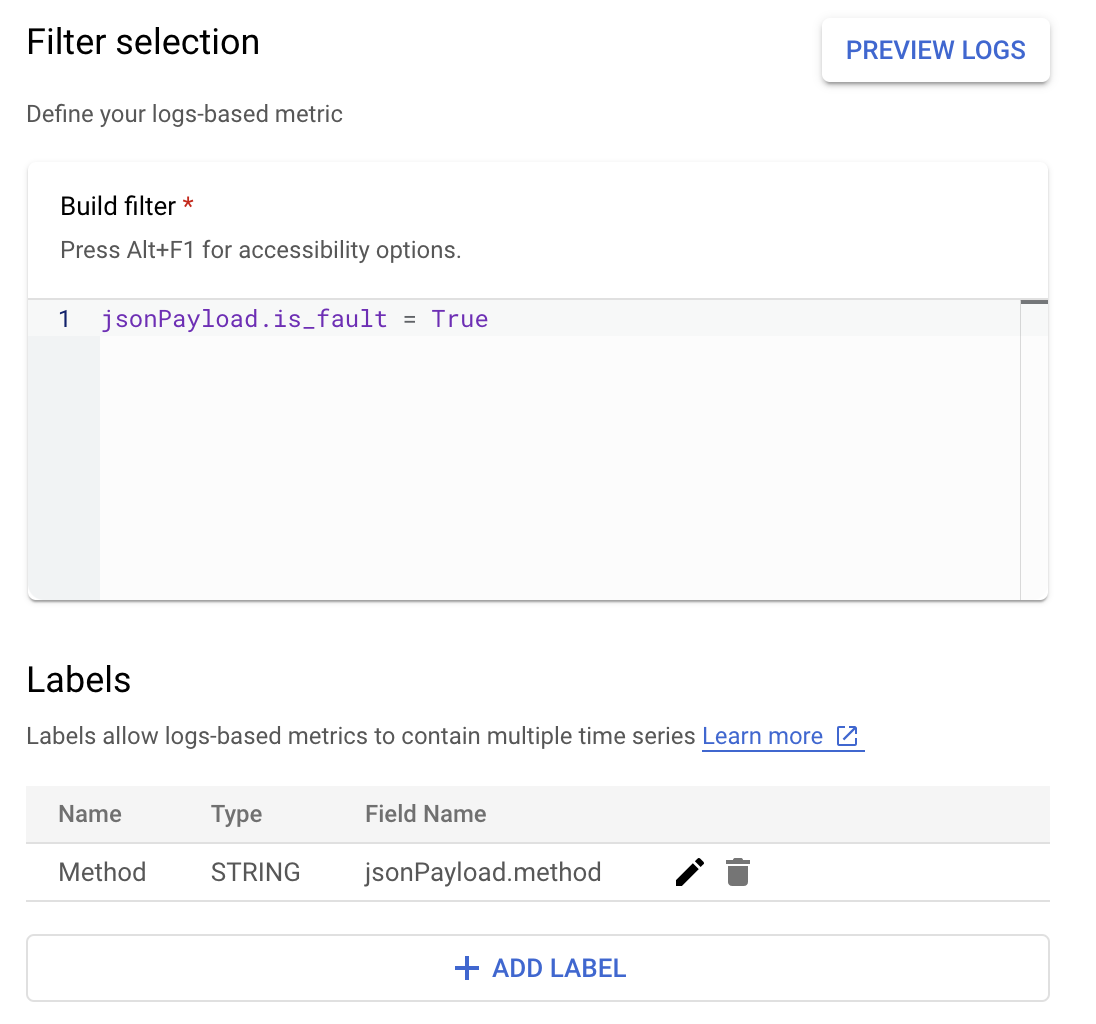
W Cloud Logging etykiety umożliwiają grupowanie wskaźników w kategorie na podstawie innych danych w logach. Możesz skonfigurować etykietę pola method wysyłanego do Cloud Logging, aby sprawdzić, jak liczba błędów jest rozkładana przy użyciu metody interfejsu Google Ads API.
Po skonfigurowaniu wskaźnika ErrorCount i etykiety Method w panelu monitorowania możesz utworzyć nowy wykres, aby monitorować ErrorCount i pogrupować dane według Method.
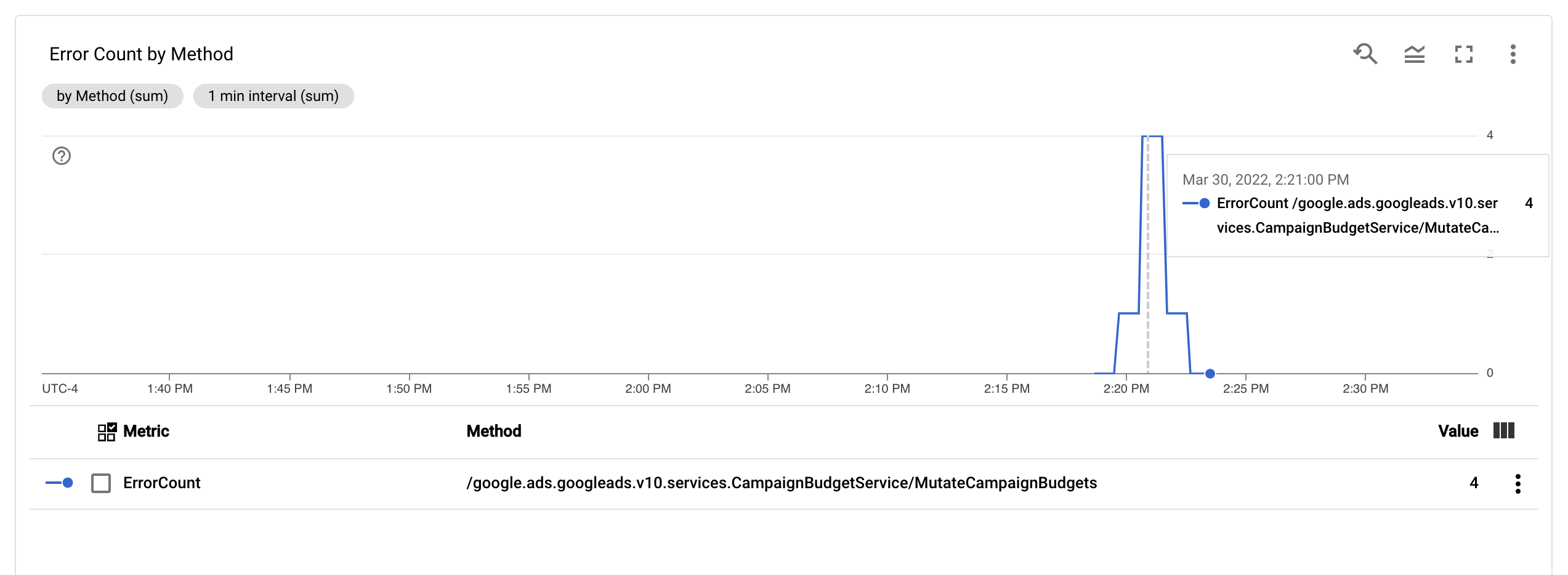
Alerty
W Cloud Monitoring i innych narzędziach możesz skonfigurować zasady tworzenia alertów, które określają, kiedy i w jaki sposób mają być uruchamiane alerty na podstawie wskaźników. Instrukcje konfigurowania alertów Cloud Monitoring znajdziesz w przewodniku po alertach.