
L'ottimizzazione delle prestazioni inizia con l'identificazione delle metriche chiave, di solito correlate a latenza e velocità effettiva. L'aggiunta del monitoraggio per acquisire e tracciare queste metriche espone i punti deboli dell'applicazione. Le metriche consentono di ottimizzare le metriche per migliorare le prestazioni.
Inoltre, molti strumenti di monitoraggio ti consentono di configurare avvisi per le metriche, in modo da ricevere una notifica al raggiungimento di una determinata soglia. Ad esempio, potresti configurare un avviso per ricevere una notifica quando la percentuale di richieste non riuscite aumenta di più del x% rispetto ai livelli normali. Gli strumenti di monitoraggio ti aiutano a identificare le normali prestazioni e picchi insoliti di latenza, quantità di errori e altre metriche chiave. La capacità di monitorare queste metriche è particolarmente importante durante periodi di tempo critici per l'attività o dopo che il nuovo codice è stato inviato in produzione.
Identifica le metriche di latenza
Assicurati di mantenere la tua UI il più reattiva possibile, facendo notare che gli utenti si aspettano standard ancora più elevati dalle app mobile. Inoltre, la latenza deve essere misurata e tracciata per i servizi di backend, in particolare perché, se non selezionata, può causare problemi di velocità effettiva.
Le metriche da monitorare suggerite includono:
- Durata della richiesta
- Durata delle richieste a livello di granularità del sottosistema (ad esempio le chiamate API)
- Durata job
Identificare le metriche di velocità effettiva
La velocità effettiva è una misura del numero totale di richieste gestite in un determinato periodo di tempo. La velocità effettiva può essere influenzata dalla latenza dei sottosistemi, quindi potresti dover ottimizzare la latenza per migliorare la velocità effettiva.
Ecco alcune metriche consigliate da monitorare:
- Query al secondo
- Dimensione dei dati trasferiti al secondo
- Numero di operazioni di I/O al secondo
- Utilizzo delle risorse, ad esempio utilizzo di CPU o memoria
- Dimensione del backlog di elaborazione, ad esempio Pub/Sub o il numero di thread
Non solo la media
Un errore comune nella misurazione del rendimento è osservare solo il caso medio (media). Sebbene questo sia utile, non fornisce insight sulla distribuzione della latenza. Una metrica migliore da monitorare sono i percentili di rendimento, ad esempio il 50°/75°/90°/99° percentile per una metrica.
In genere, l'ottimizzazione può essere eseguita in due passaggi. In primo luogo, ottimizza per la latenza del 90° percentile. Considera quindi il 99° percentile, noto anche come latenza di coda, ovvero la piccola parte di richieste il cui completamento richiede molto più tempo.
Monitoraggio lato server per risultati dettagliati
In genere è preferibile la profilazione lato server per il monitoraggio delle metriche. In genere, il lato server è molto più facile da strumentare, consente l'accesso a dati più granulari ed è meno soggetto alle perturbazioni causate da problemi di connettività.
Monitoraggio del browser per la visibilità end-to-end
La profilazione del browser può fornire ulteriori informazioni sull'esperienza dell'utente finale. Può mostrare quali pagine hanno richieste lente, che puoi poi correlare al monitoraggio lato server per ulteriori analisi.
Google Analytics fornisce un monitoraggio immediato dei tempi di caricamento delle pagine nel report sui tempi delle pagine. Fornisce diverse visualizzazioni utili per comprendere l'esperienza utente sul tuo sito, in particolare:
- Tempi di caricamento della pagina
- Tempi di caricamento dei reindirizzamenti
- Tempi di risposta del server
Monitoraggio nel cloud
Esistono molti strumenti che puoi utilizzare per acquisire e monitorare le metriche delle prestazioni della tua applicazione. Ad esempio, puoi utilizzare Google Cloud Logging per registrare le metriche delle prestazioni nel tuo progetto Google Cloud e configurare dashboard in Google Cloud Monitoring per monitorare e segmentare le metriche registrate.
Consulta la guida a Logging per un esempio di logging in Google Cloud Logging da un intercettatore personalizzato nella libreria client Python. Con questi dati disponibili in Google Cloud, puoi creare metriche sui dati registrati per ottenere visibilità sulla tua applicazione tramite Google Cloud Monitoring. Segui la guida per le metriche basate su log definite dall'utente per creare metriche utilizzando i log inviati a Google Cloud Logging.
In alternativa, puoi utilizzare le librerie del client Monitoring per definire le metriche nel codice e inviarle direttamente a Monitoring, separatamente dai log.
Esempio di metriche basate su log
Supponiamo di voler monitorare il valore is_fault per comprendere meglio
le percentuali di errore nella tua applicazione. Puoi estrarre il valore is_fault dai log in una nuova metrica del contatore, ErrorCount.
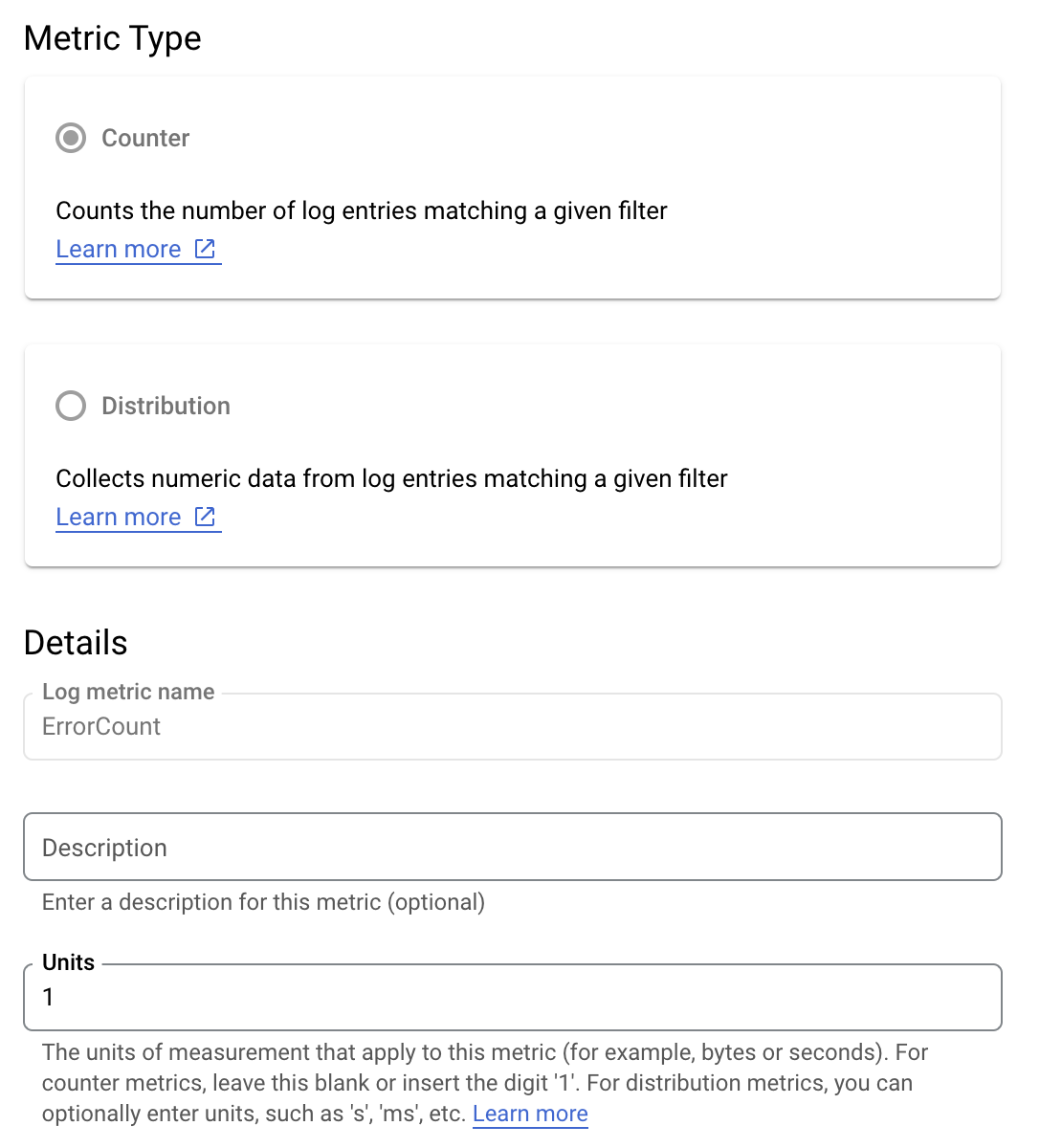

In Cloud Logging, le etichette consentono di raggruppare le metriche in categorie in base ad altri dati dei log. Puoi configurare un'etichetta per il campo method inviato a Cloud Logging per vedere come il conteggio degli errori viene suddiviso in base al metodo API Google Ads.
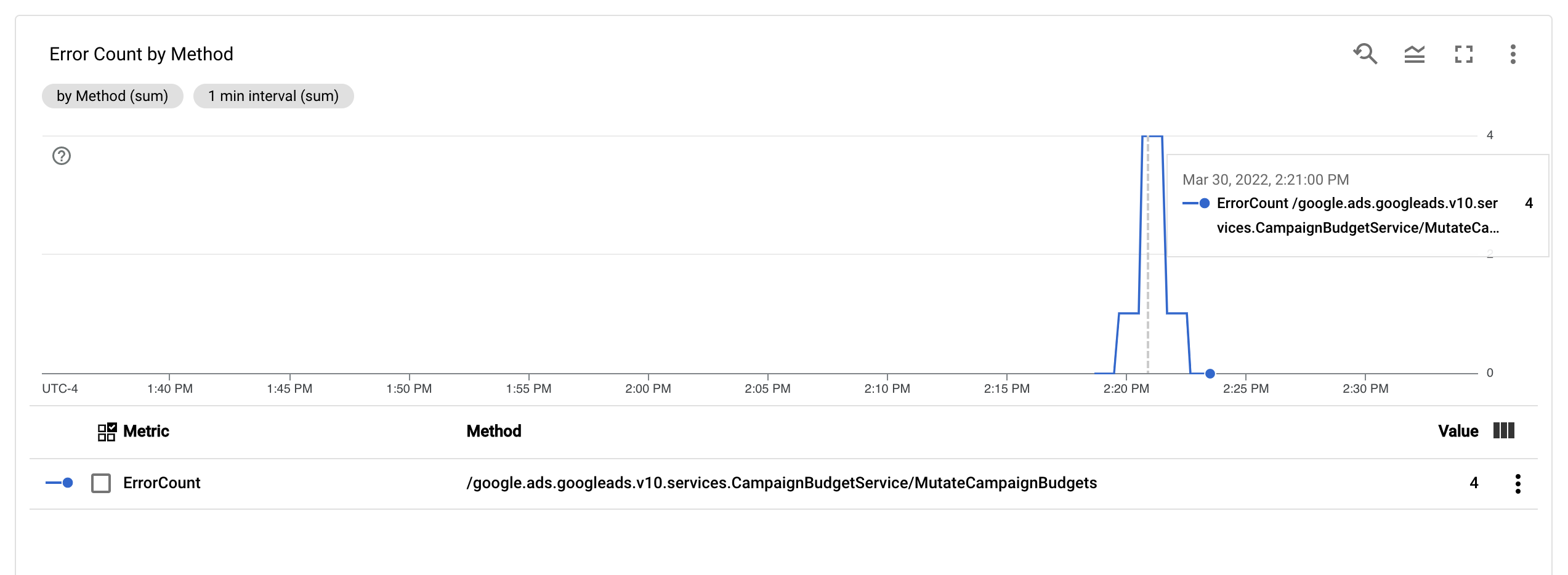
Con la metrica ErrorCount e l'etichetta Method configurate, puoi creare
un nuovo
grafico in una
dashboard di Monitoring per monitorare ErrorCount, raggruppato per Method.
Avvisi
In Cloud Monitoring e in altri strumenti è possibile configurare criteri di avviso che specificano quando e come gli avvisi devono essere attivati dalle metriche. Per le istruzioni sulla configurazione degli avvisi di Cloud Monitoring, consulta la guida agli avvisi.