
La optimización del rendimiento comienza con la identificación de métricas clave, que suelen estar relacionadas con la latencia y la capacidad de procesamiento. La incorporación de la supervisión para capturar y hacer un seguimiento de estas métricas expone los puntos débiles de la aplicación. Con las métricas, se puede realizar la optimización para mejorar las métricas de rendimiento.
Además, muchas herramientas de supervisión te permiten configurar alertas para tus métricas, de modo que recibas una notificación cuando se cumpla un umbral determinado. Por ejemplo, puedes configurar una alerta para que te notifique cuando el porcentaje de solicitudes fallidas aumente en más de x% de los niveles normales. Las herramientas de supervisión pueden ayudarte a identificar cómo es el rendimiento normal y los aumentos inusuales en la latencia, las cantidades de errores y otras métricas clave. La capacidad de supervisar estas métricas es especialmente importante durante los períodos críticos para la empresa o después de que se haya enviado código nuevo a producción.
Identifica las métricas de latencia
Asegúrate de que tu IU sea lo más responsiva posible, y ten en cuenta que los usuarios esperan estándares aún más altos de las apps para dispositivos móviles. También se debe medir y hacer un seguimiento de la latencia de los servicios de backend, en particular, ya que puede generar problemas de capacidad de procesamiento si no se controla.
Entre las métricas sugeridas para hacer un seguimiento, se incluyen las siguientes:
- Duración de la solicitud
- Duración de la solicitud con granularidad de subsistema (como llamadas a la API)
- Duración del trabajo
Identifica las métricas de capacidad de procesamiento
La capacidad de procesamiento es una medida de la cantidad total de solicitudes atendidas durante un período determinado. La capacidad de procesamiento puede verse afectada por la latencia de los subsistemas, por lo que es posible que debas optimizar la latencia para mejorar la capacidad de procesamiento.
Estas son algunas métricas sugeridas para hacer un seguimiento:
- Consultas por segundo
- Tamaño de los datos transferidos por segundo
- Cantidad de operaciones de E/S por segundo
- Utilización de recursos, como el uso de CPU o memoria
- Tamaño del trabajo pendiente de procesamiento, como Pub/Sub o cantidad de subprocesos
No solo la media
Un error común al medir el rendimiento es solo observar el caso medio (promedio). Si bien esto es útil, no proporciona información sobre la distribución de la latencia. Una mejor métrica para hacer un seguimiento son los percentiles de rendimiento, por ejemplo, el percentil 50, 75, 90 o 99 para una métrica.
En general, la optimización se puede realizar en dos pasos. Primero, optimiza la latencia del percentil 90. Luego, considera el percentil 99, también conocido como latencia de cola: la pequeña porción de solicitudes que tardan mucho más en completarse.
Supervisión del servidor para obtener resultados detallados
Por lo general, se prefiere la generación de perfiles del servidor para hacer un seguimiento de las métricas. Por lo general, el servidor es mucho más fácil de instrumentar, permite el acceso a datos más detallados y está menos sujeto a perturbaciones por problemas de conectividad.
Supervisión del navegador para obtener visibilidad de extremo a extremo
La generación de perfiles del navegador puede proporcionar estadísticas adicionales sobre la experiencia del usuario final. Puede mostrar qué páginas tienen solicitudes lentas, que luego puedes correlacionar con la supervisión del servidor para realizar un análisis más detallado.
Google Analytics proporciona supervisión lista para usar de los tiempos de carga de la página en el informe de tiempos de página. Esto proporciona varias vistas útiles para comprender la experiencia del usuario en tu sitio, en particular:
- Tiempos de carga de la página
- Tiempos de carga de redireccionamiento
- Tiempos de respuesta del servidor
Supervisión en la nube
Existen muchas herramientas que puedes usar para capturar y supervisar las métricas de rendimiento de tu aplicación. Por ejemplo, puedes usar Google Cloud Logging para registrar métricas de rendimiento en tu proyecto de Google Cloud y, luego, configurar paneles en Google Cloud Monitoring para supervisar y segmentar las métricas registradas.
Consulta la guía de Logging para ver un ejemplo de registro en Google Cloud Logging desde un interceptor personalizado en la biblioteca cliente de Python. Con esos datos disponibles en Google Cloud, puedes crear métricas sobre los datos registrados para obtener visibilidad de tu aplicación a través de Google Cloud Monitoring. Sigue la guía para las métricas basadas en registros definidas por el usuario para crear métricas con los registros enviados a Google Cloud Logging.
Como alternativa, puedes usar las bibliotecas cliente de Monitoring para definir métricas en tu código y enviarlas directamente a Monitoring, por separado de los registros.
Ejemplo de métricas basadas en registros
Supongamos que deseas supervisar el valor is_fault para comprender mejor las tasas de error en tu aplicación. Puedes extraer el valor is_fault de los registros
en una nueva métrica de contador, ErrorCount.
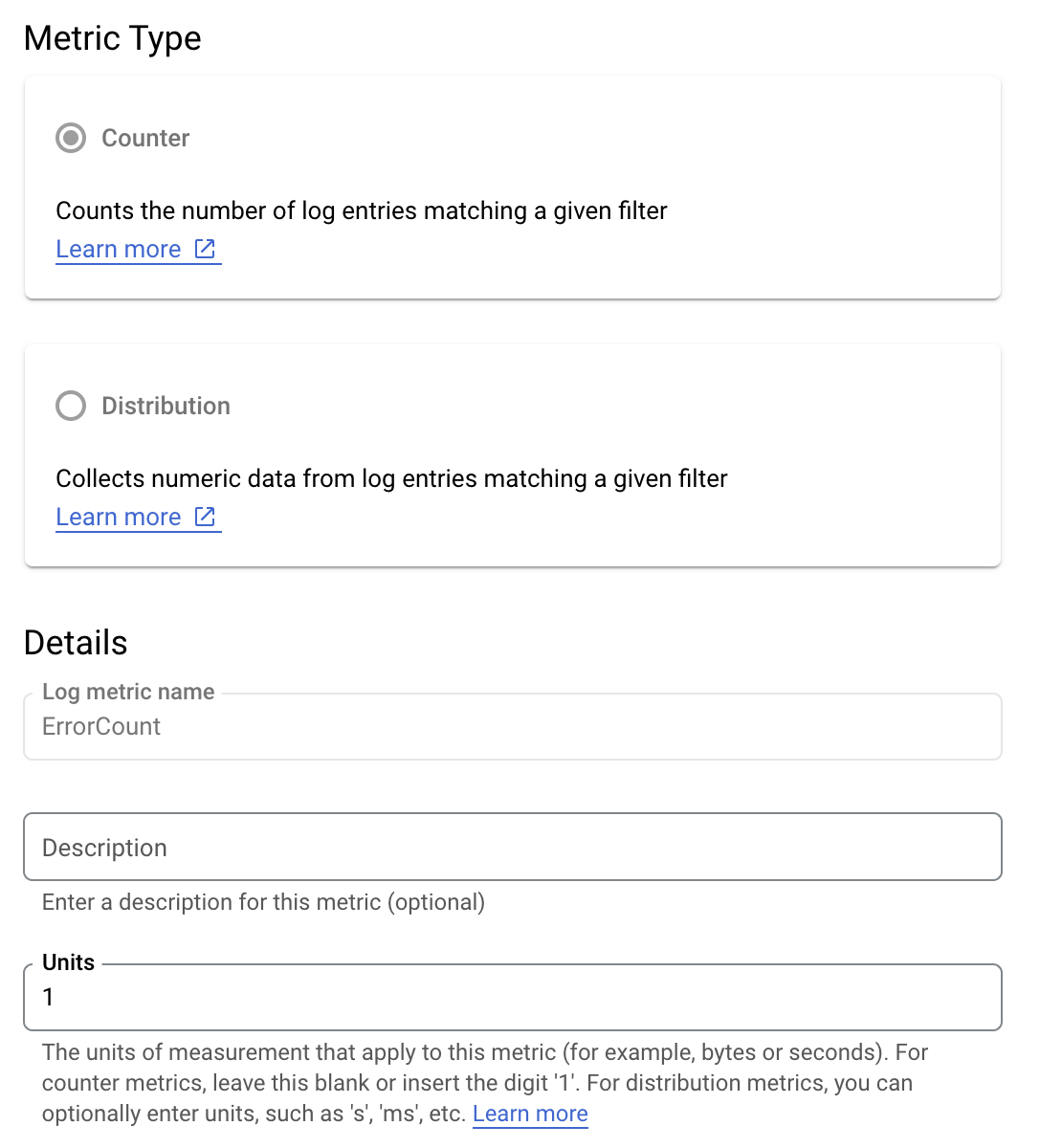
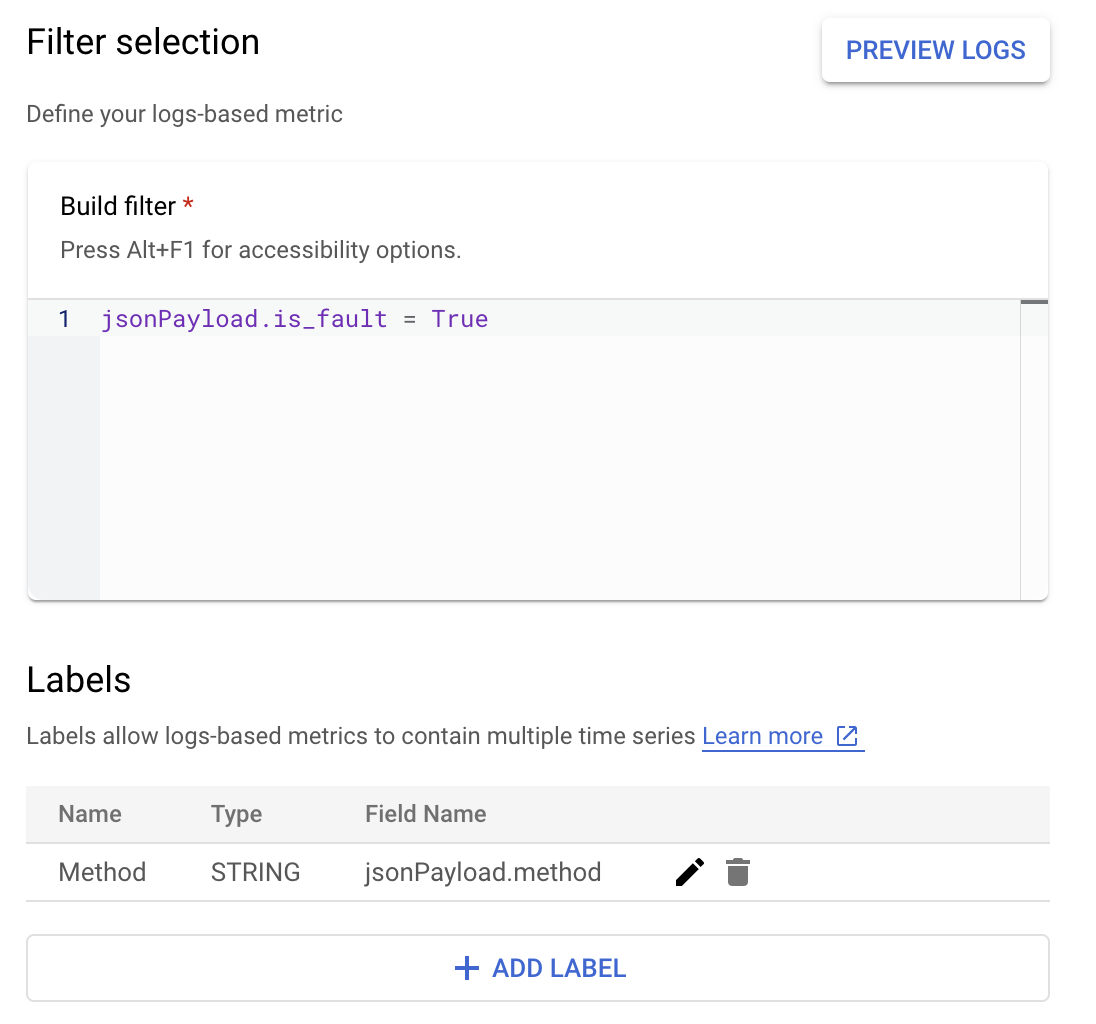
En Cloud Logging, las etiquetas te permiten agrupar tus métricas en categorías
según otros datos de los registros. Puedes configurar una etiqueta para el campo method
enviado a Cloud Logging para ver cómo se desglosa el recuento de errores por el método de la API de Google Ads.
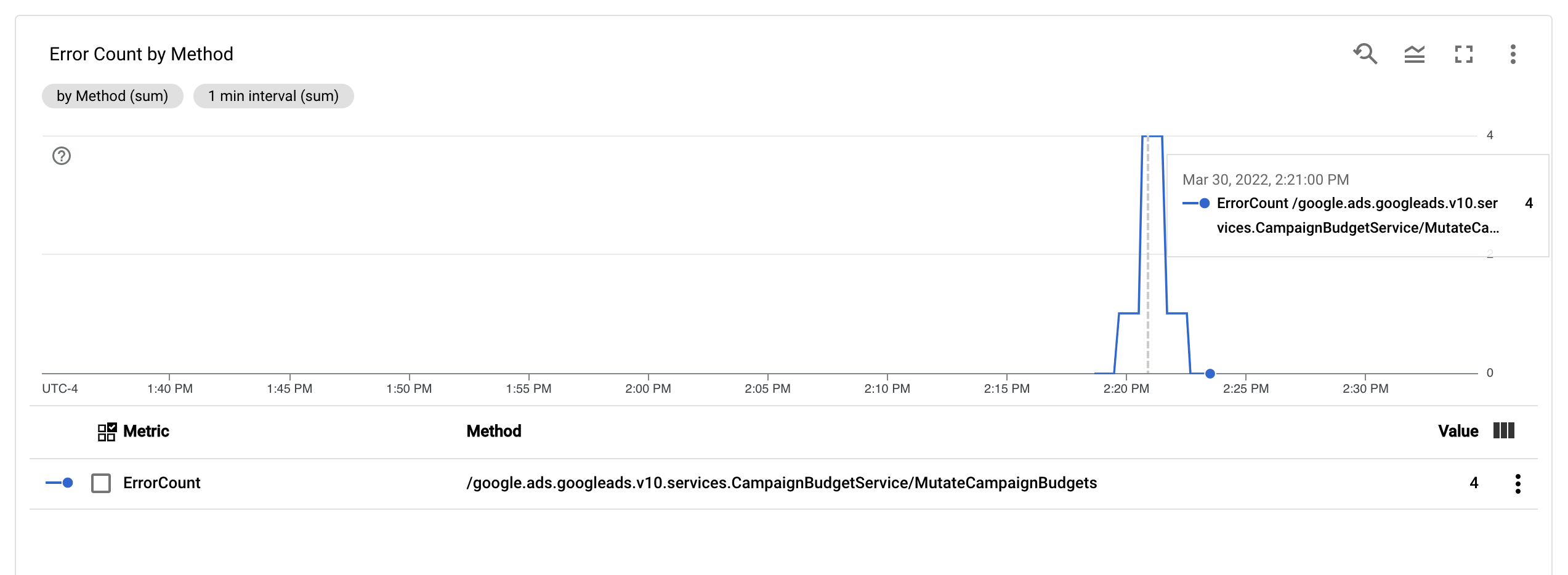
Con la métrica ErrorCount y la etiqueta Method configuradas, puedes crear
un gráfico
nuevo en
un panel de Monitoring para supervisar ErrorCount, agrupado por Method.
Alertas
Es posible configurar políticas de alertas en Cloud Monitoring y en otras herramientas que especifiquen cuándo y cómo se deben activar las alertas según tus métricas. Para obtener instrucciones sobre cómo configurar alertas de Cloud Monitoring, consulta la guía de alertas.