
パフォーマンスの最適化は、通常はレイテンシとスループットに関連する主要な指標を特定することから始まります。これらの指標をキャプチャして追跡するモニタリングを追加すると、アプリケーションの弱点が明らかになります。指標を使用すると、パフォーマンス指標を改善するための最適化を行うことができます。
また、多くのモニタリング ツールでは、指標のアラートを設定して、特定のしきい値に達したときに通知を受け取ることができます。たとえば、リクエストの失敗率が通常のレベルの x% を超えて増加した場合に通知するアラートを設定できます。モニタリング ツールを使用すると、通常のパフォーマンスを把握し、レイテンシ、エラー数、その他の主要な指標の異常な急増を特定できます。これらの指標をモニタリングする機能は、ビジネス クリティカルな期間中や、新しいコードが本番環境にプッシュされた後に特に重要になります。
レイテンシ指標を特定する
ユーザーはモバイルアプリに さらに高い基準を求めているため、UI の応答性をできるだけ高く保つようにしてください。また、バックエンド サービスのレイテンシも測定して追跡する必要があります。放置するとスループットの問題につながる可能性があるためです。
追跡する指標として、次のようなものがあります。
- リクエストの実行時間
- サブシステム単位(API 呼び出しなど)のリクエストの実行時間
- ジョブの所要時間
スループット指標を特定する
スループットは、一定期間に処理されたリクエストの合計数を測定したものです。スループットはサブシステムのレイテンシの影響を受ける可能性があるため、スループットを改善するにはレイテンシを最適化する必要があります。
追跡する指標として、次のようなものがあります。
- 秒間クエリ数
- 1 秒あたりに転送されるデータのサイズ
- 1 秒あたりの I/O オペレーション数
- リソース使用率(CPU やメモリ使用量など)
- 処理バックログのサイズ(Pub/Sub やスレッド数など)
平均値だけではない
パフォーマンスの測定でよくある間違いは、平均値(平均)のみを確認することです。これは便利ですが、レイテンシの分布を把握することはできません。追跡する指標としては、パフォーマンスのパーセンタイル(指標の 50 パーセンタイル、75 パーセンタイル、90 パーセンタイル、99 パーセンタイルなど)が適しています。
通常、最適化は 2 つのステップで行います。まず、90 パーセンタイルのレイテンシを最適化します。次に、99 パーセンタイル(テールレイテンシとも呼ばれます)を考慮します。これは、完了までに時間がかかるリクエストの小さな部分です。
詳細な結果を得るためのサーバーサイド モニタリング
指標の追跡には、一般的にサーバーサイド プロファイリングが推奨されます。サーバーサイドは通常、計測がはるかに簡単で、より詳細なデータにアクセスでき、接続の問題による影響を受けにくいです。
エンドツーエンドの可視化のためのブラウザ モニタリング
ブラウザ プロファイリングを使用すると、エンドユーザー エクスペリエンスに関する追加の分析情報を得ることができます。 リクエストが遅いページを確認し、サーバーサイド モニタリングと関連付けてさらに分析できます。
Google アナリティクスでは、ページタイミング レポートでページの読み込み 時間をすぐにモニタリングできます。これにより、サイトでのユーザー エクスペリエンスを把握するための便利なビューがいくつか提供されます。特に次の点に注目してください。
- ページの読み込み時間
- リダイレクトの読み込み時間
- サーバーの応答時間
クラウドでのモニタリング
アプリケーションのパフォーマンス指標をキャプチャしてモニタリングするために使用できるツールは多数あります。たとえば、Google Cloud Logging を使用してパフォーマンス指標を Google Cloud プロジェクト に記録し、Google Cloud Monitoring でダッシュボードを設定して、記録された指標をモニタリングしてセグメント化できます。
Python クライアント ライブラリのカスタム インターセプタから Google Cloud Logging にロギングする例については、Logging ガイドをご覧ください。 Google Cloud でそのデータを利用できるため、記録されたデータに基づいて指標を作成し、Google Cloud Monitoring を介してアプリケーションを可視化できます。ユーザー定義のログベースの指標のガイドに沿って、Google Cloud Logging に送信されたログを使用して指標を 作成します。
または、Monitoring クライアント ライブラリを使用して、コードで指標を定義し、ログとは別に Monitoring に直接送信することもできます。
ログベースの指標の例
アプリケーションのエラー率をより深く理解するために、is_fault 値をモニタリングするとします。ログから is_fault 値を抽出し、ログ
から新しい カウンタ指標、ErrorCount に格納できます。
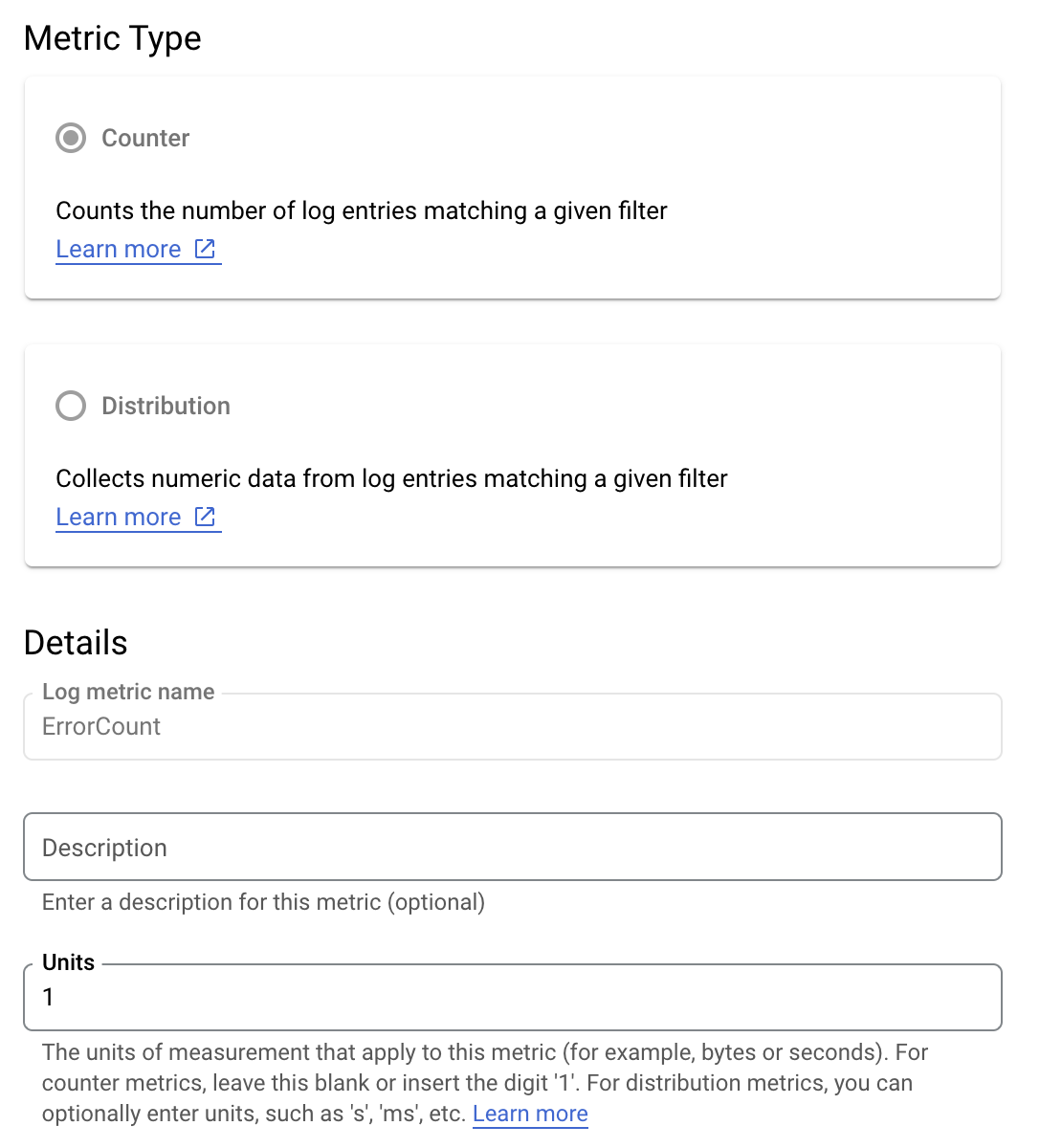
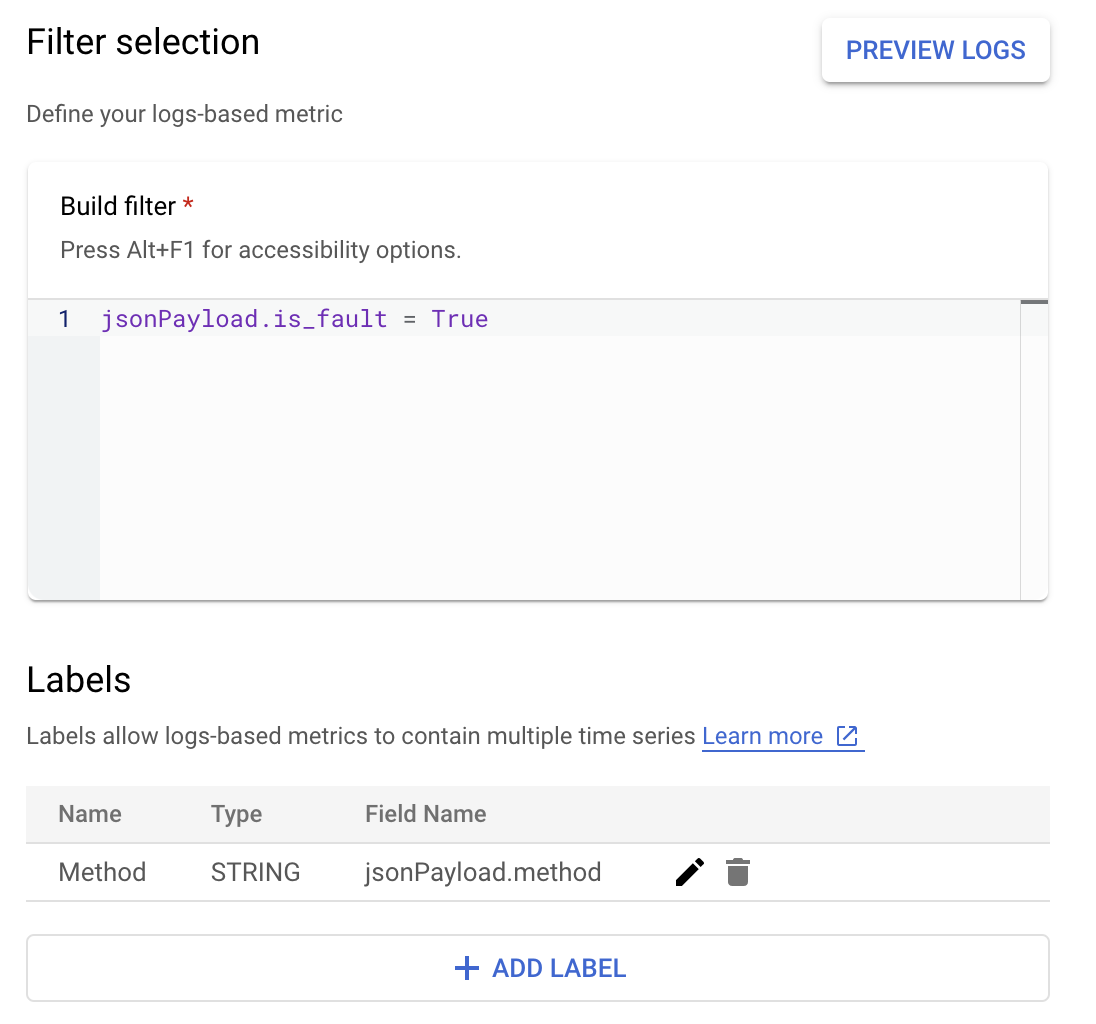
Cloud Logging では、ラベルを使用して、ログ内の他のデータに
基づいて指標をカテゴリにグループ化できます。Google Ads API メソッド別にエラー数を分析するために、Cloud Logging に送信される method
フィールドのラベルを構成できます。

アラート
Cloud Monitoring やその他のツールでは、指標によってアラートをトリガーするタイミングと方法を指定するアラート ポリシーを構成できます。Cloud Monitoring アラートの設定手順については、 アラートガイドをご覧ください。