2011 年 5 月 2 日,星期一
您正在想着自己的事情,用网站站长工具看看自己的网站有多棒…但是,等等!抓取错误页面中显示了大量 404 (Not found) 错误!是即将出现严重后果吗?
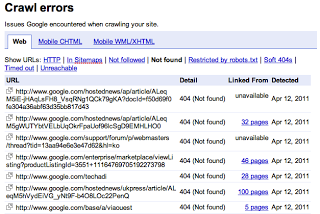
别担心,我的新手网站站长。我们来了解一下 404 错误,看看这些错误会对您的网站产生什么影响(或没有影响):
问:网站站长工具中报告的 404 错误是否会影响我的网站排名?
答:404 错误是网页的完全正常部分;互联网不断变化,新内容诞生,旧内容终止,当它终止时(理想情况下),就会返回 404 HTTP 响应代码。搜索引擎知道这一点;我们在自己的网站上也有 404 错误(如上文所示),我们在整个网络都会遇到这些错误。事实上,我们有时希望遇到这样的错误;当您删除网站上的某个网页后,请确保它会返回 404 或 410 响应代码(而不是 soft
404)。请注意,为了让我们的抓取工具能够看到网址的 HTTP 响应代码,抓取工具必须能够抓取该网址。如果该网址被 robots.txt 文件屏蔽,我们就无法抓取该网址并看到其响应代码。您网站上的部分网址不再存在或返回 404 错误不会影响您网站的其他网址(返回 200 (Success) 状态代码的网址)在搜索结果中的表现。
问:404 错误对我的网站没有任何影响吗?
答:如果您网站上的部分网址返回 404 错误,那么仅这一点就不会影响您的网站或对网站在 Google 搜索结果中的表现产生负面影响。不过,可能由于其他原因,您需要解决某些类型的 404 错误。例如,如果返回 404 错误的某些网页是您真正关心的网页,则应检查我们抓取网页时为什么会看到 404 错误!如果您看到合法网址拼写有误(www.example.com/awsome 而不是 www.example.com/awesome),很可能是因为有人原本打算链接到您的网站,但却输错了网址。您可以通过 301 代码将拼写有误的网址重定向到正确的网址,并通过该链接捕获预期流量,而不是返回 404。您还可以确保,当用户到达您网站上的 404 网页时,您可以帮助他们找到自己要找的内容,而不仅仅是显示“404 未找到”。
问:请详细说明“soft 404 错误”。
答:soft 404 表示 Web 服务器针对不存在的网址返回 404 或 410 以外的响应代码。一个常见的示例是,网站所有者想要返回包含有用用户信息的实用 404 网页,并认为要向用户提供内容,必须返回 200 响应代码。事实并非如此!您可以在提供所需内容的同时返回 404 响应代码。再比如,网站将所有未知网址重定向到其首页,而不是返回 404 错误。这两种情况都会对我们对您网站的理解和索引编制产生负面影响,因此我们建议您确保服务器针对不存在的内容返回正确的响应代码。请注意,网页显示“404 未找到”,也并不表示它就一定会返回 404 HTTP 响应代码,请使用网站站长工具中的 Googlebot 模拟抓取功能仔细检查。如果您不知道如何配置服务器以返回正确的响应代码,请参阅网站托管服务商的帮助文档。
问:如何知道某个网址应该返回 404、301 还是 410?
当您从网站上移除网页时,请考虑一下,您是要将相关内容移到别处,还是要从网站上永久移除此类内容。如果您要将相关内容移到新网址,请使用 301 代码将旧网址重定向到新网址。这样一来,如果用户访问旧网址查找该内容,系统就会自动将他们重定向到与所需内容相关的网址。如果您要彻底删除相关内容且您的网站上没有可满足用户相同需求的内容,那么旧版网址应该返回 404 或 410。目前,Google 会将 410 (Gone) 视为与 404 (Not found) 相同,因此无论返回哪一个,对我们来说都一样。
问:我的大部分 404 错误都是针对我的网站中从未存在过的奇怪网址。
这是怎么回事?它们来自哪里?
答:如果 Google 在网络上某个位置找到指向您网域中网址的链接,可能会尝试抓取该链接,无论其中是否实际存在任何内容;如果 Google 尝试抓取了,并且找不到任何内容,您的服务器应该返回 404。导致出现这些链接的原因可能是:有人在链接到您的网站时拼错了网址;某些类型的错误配置(如果链接是自动生成的,例如由 CMS 自动生成);或者由 Google 努力识别和抓取嵌入 JavaScript 中的链接或其他嵌入式内容;或者,也可能是我们在进行快速检查,以了解您的服务器如何处理未知网址,等等。如果网站站长工具针对您网站上不存在的网址报告了 404 错误,您可以放心地忽略它们。我们不知道哪些网址对您很重要,哪些网址应该返回 404 错误,因此我们将向您展示在您的网站上发现的所有 404 错误,并由您决定需要注意哪些错误(如果有)。
问:有人抄袭了我的网站,并在此过程中造成了很多 404 错误。这些都是包含其他代码的“真实”网址(例如 https://www.example.com/images/kittens.jpg" width="100" height="300" alt="kittens"/>),这会影响我的网站吗?
答:一般来说,您无需担心,这样的“损坏链接”不会影响您的网站。我们知道,网站所有者几乎无法控制抄袭其网站的用户,或以异常方式链接到其网站的用户。如果您擅长使用正则表达式,可以考虑重定向这些网址,但一般来说,无需担心。请注意,如果您认为有人从您的网站窃取原创内容,也可以提交移除要求。
问:上周我修正了网站站长工具报告的所有 404 错误,但它们仍然列在我的帐号中。这是否意味着我没有正确解决这些问题?它们需要多长时间才会消失?
答:请查看“抓取错误”页面上的“上次检测到此错误的时间”列,这是最近一次检测到每个错误的日期。如果该列中的日期是您修正错误之前的日期,则意味着我们自该日期起未遇到这些错误。如果日期较近,则表示我们在抓取时仍会看到这些 404 错误。
修正后,您可以使用 Googlebot 模拟抓取功能来检查抓取工具能否看到新的响应代码。 测试几个网址,如果它们看上去正常,这些错误应该很快就会从“抓取错误”列表中消失。
问:我能否使用 Google 的网址移除工具,让 404 错误更快地从我的帐号中消失?
答:不能。网址移除工具会从 Google 搜索结果中移除网址,而不是从您的网站站长工具帐号中移除网址。它仅用于处理紧急移除请求,如果网址已返回 404 错误,则不必使用该工具,因为随着时间的推移,此类网址自然会从我们的搜索结果中消失。请参阅这篇博文的下半部分,详细了解网址移除工具可以执行哪些操作以及不能执行哪些操作。
还想要详细了解 404 错误?请在我们的博客中查看 404 特集,或访问我们的网站站长帮助论坛。