2024 年 12 月 3 日,星期二
您可能听说过,Google 搜索需要完成一些工作,才能在 Google 搜索结果中显示某个网页。其中一个步骤称为“抓取”。Google 搜索上的抓取工作是由 Googlebot 完成的。Googlebot 是 Google 服务器上运行的一款程序,用于检索网址,并处理在遍历整个网络时可能遇到的网络错误、重定向和其他小问题。但是,有些细节并不常被提及。在本月的每周,我们都会探讨这些细节的一部分,因为这些细节可能会对您网站的被抓取方式产生重大影响。
稍微回顾一下:什么是抓取?
抓取是指发现新网页和重新访问更新后的网页并下载网页的过程。简而言之,Googlebot 会获取网址,向托管该网址的服务器发出 HTTP 请求,然后处理来自该服务器的响应(可能会跟随重定向、处理错误),并将网页内容传递给 Google 的索引编制系统。
但现代网页并非纯 HTML,那么构成网页的其他资源呢? 抓取这些资源会对“抓取预算”产生什么影响?这些资源是否可以在 Google 端缓存?未曾抓取过的网址与已编入索引的网址之间是否存在差异?在这篇博文中,我们将解答这些问题并探讨更多内容!
Googlebot 和抓取网页资源
除了 HTML 之外,现代网站还会结合使用 JavaScript 和 CSS 等不同技术,为用户提供逼真体验和实用功能。当用户使用浏览器访问此类网页时,浏览器会先下载父级网址,其中托管着开始为用户构建网页所需的数据,即网页的 HTML。此类初始数据可能包含对 JavaScript 和 CSS 等资源的引用,也可能包含浏览器将再次下载的图片和视频,以终于构建向用户呈现的最终网页。
Google 也会执行完全相同的操作,但方式略有不同:
- Googlebot 从父网址(网页的 HTML)下载初始数据。
- Googlebot 将提取的数据传递给网页渲染服务 (WRS)。
- WRS 使用 Googlebot 下载原始数据中引用的资源。
- WRS 像用户的浏览器一样,使用所有下载的资源构建网页。
与浏览器相比,由于调度限制(例如托管渲染网页所需资源的服务器的被感知负载),每个步骤之间的时间间隔可能会明显更长。这时,抓取预算就有了用武之地。
抓取渲染网页所需的资源会消耗托管资源的主机名的抓取预算。为了改善这种情况,WRS 会尝试缓存其渲染的网页中引用的所有资源(JavaScript 和 CSS)。WRS 缓存的存留时长不受 HTTP 缓存指令影响;实际上,WRS 会将所有内容缓存长达 30 天,这有助于为其他抓取任务保留网站的抓取预算。
从网站所有者的角度来看,管理抓取资源的方式和抓取的资源可能会影响网站的抓取预算;我们建议:
- 尽可能少用资源,为用户提供出色的体验;渲染网页所需的资源越少,渲染过程中使用的抓取预算就越少。
- 慎用缓存无效化参数:如果资源的网址发生更改,Google 可能需要重新抓取这些资源,即使它们的内容未更改。这当然会消耗抓取预算。
- 在与主网站不同的主机名上托管资源,例如,通过使用 CDN 或仅在其他子网域上托管资源。这会将抓取预算问题转移到提供资源的主机。
所有这些要点也适用于媒体资源。如果 Googlebot(更具体地说,是 Googlebot-Image 和 Googlebot-Video)抓取这些网页,则会消耗网站的抓取预算。
您可能会忍不住也想将 robots.txt 添加到列表中,但从渲染角度来看,禁止抓取资源通常会导致问题。如果 WRS 无法提取对渲染至关重要的资源,Google 搜索便可能无法提取网页内容,也无法让网页在 Google 搜索中排名靠前。
什么是 Googlebot 抓取?
若要分析 Google 正在抓取哪些资源,最佳来源是网站的原始访问日志,其中包含浏览器和抓取工具请求的每个网址的条目。为便于在访问日志中识别 Google 的抓取工具,我们在开发者文档中发布了 IP 范围。
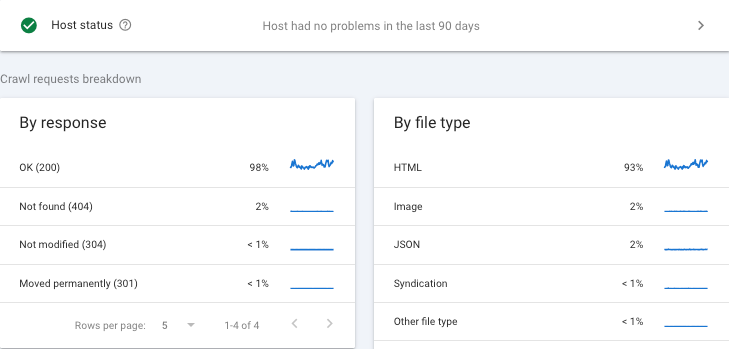
次最佳来源当然是 Search Console“抓取统计信息”报告,其中会按抓取工具细分每种资源:
最后,如果您对抓取和渲染非常感兴趣,并想与他人讨论相关问题,请访问搜索中心社区,您也可在 LinkedIn 上找到我们。
进行了几项更新
- 2024 年 12 月 6 日更新:指出了从其他源提供资源的性能影响。