2011 年 9 月 1 日,星期四
我们的使命是整合全球信息,供大众使用,使人人受益。在这项浩大的任务中,我们有时会遇到非 HTML 文件,例如 PDF、电子表格和演示文稿。我们的算法并不会因不同文件类型而减慢速度;我们会努力提取相关内容,并适当地将其编入索引,以便在搜索结果中呈现。不过,我们要如何将这些类型的文件实际编入索引?因为它们通常与标准 HTML 有很大不同,这些文件适用哪些准则?如果网站站长不希望我们将它们编入索引,该怎么办?
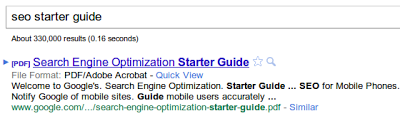
Google 从 2001 年开始将 PDF 文件编入索引,目前已将数以亿计的 PDF 文件编入索引。我们收集了有关 PDF 索引编制的常见问题,答案如下:
问:Google 是否可以将任何类型的 PDF 文件编入索引?
答:通常,我们可以将使用各种字符编码的 PDF 文件中的文本内容(以任何语言编写)编入索引,但前提是 PDF 文件没有密码保护或加密。如果文本作为图片嵌入,我们可能会使用 OCR 算法从图片中提取文本。一般来说,只要您可以将 PDF 文档中的文本复制粘贴到标准文本文档中,我们就可以将该文本编入索引。
问:PDF 文件中的图片会怎么样?
答:目前,Google 不会将图片编入索引。若要让我们将图片编入索引,您需要为图片创建 HTML 页面。为了提高我们在搜索结果中返回图片的可能性,请参阅 Google 图片最佳实践。
问:PDF 文档中的链接会怎么处理?
答:通常,处理 PDF 文件中的链接的方式与处理 HTML 中的链接类似:这些链接可以传递 PageRank 和其他索引编制信号,而且 Google 可能会在抓取 PDF 文件后跟踪这些链接。目前无法在 PDF 文档中使用 nofollow 链接。
问:如何防止我的 PDF 文件显示在搜索结果中?如果它们已经显示在搜索结果中,我该如何移除它们?
答:要防止 PDF 文档显示在搜索结果中,最简单的方法就是在用于提供文件的 HTTP 标头中添加 X-Robots-Tag: noindex。如果 Google 已将这些文件编入索引,您可以将 X-Robot-Tag 与 noindex 规则搭配使用,让这些文件随着时间的流逝从索引系统中移除。如需加快移除过程,您可以使用 Google 网站站长工具中的网址移除工具。
问:PDF 文件能在搜索结果中获得较高的排名吗?
答:当然可以!它们的排名通常与其他网页相似。例如,在这篇博文发布时,搜索 mortgage market review、irs form 2011 或 paracetamol expert report 都会返回 PDF 文档,并且这些文档在我们的搜索结果中获得了较高的排名,这要归功于其内容和在其他网页中嵌入和链接的方式。
问:如果我的网页同时有 HTML 和 PDF 两种版本,会被视为重复内容吗?
答:建议您尽可能只为内容提供一个版本。如果无法做到这一点,请务必指明您的首选版本,例如在站点地图中添加首选网址,或在 HTML 或 PDF 资源的 HTTP 标头中指定规范版本。如需获取更多建议,请参阅关于规范化的帮助中心文章。
问:如何影响 PDF 文档在搜索结果中显示的标题?
答:我们会根据两个主要元素确定显示的标题:文件中的标题元数据,以及指向 PDF 文件的链接的定位文字。为了让我们的算法明确地知道要使用的标题,我们建议对这两项都进行更新。
如需了解更多信息,请观看 Matt Cutt 发布的关于如何对 PDF 文件进行有利搜索的优化视频。有关我们能够编入索引的内容类型,请访问我们的帮助中心。如果您有任何反馈或建议,请前往网站站长帮助论坛告诉我们。