2007年12月10日星期一
发表者: John Blackburn (站长工具组),Matt Dougherty, 搜索质量组
原文: New robots.txt feature and REP Meta Tags
发表于: 2007年8月15日,星期三,下午4时01分
我们已经改进了站长中心的分析工具,使之能理解网站地图(sitemap)的声明和相关的URL。较早的版本并不认识网站地图,且仅仅理解绝对的URL;其他的任何东西都被报错成“不理解你的语法”。现在改进后的版本会告诉你网站地图的URL和范围是否正确。您还可以对相关的URL测试并少了许多输入工作。
现在生成的报告也好多了。你可以在一行中知道多个问题的答案(如果有的话)。不像早期版本,一行仅第一个遇到的问题给出答案。同时,我们也在其他用以分析和验证的功能上取得了改进。
假设你负责域名 www.example.com ,你希望搜索引擎索引你网站的除/images文件夹之外的一切内容。您还想确保你的网站地图被搜索引擎知道,那么你可以使用以下内容作为你的robots.txt文件:
disallow images
user-agent: *
Disallow:
sitemap: https://www.example.com/sitemap.xml
你可以访问站长中心,使用robots.txt分析工具对你的网站进行测试,用这两个URL作测试:
https://www.example.com
/archives
站长工具的较早版本将会报错:

改进版会告诉你关于robots.txt文件的更多信息:
你可以在 https://www.google.com/webmasters/tools 看到以上信息。
我们还希望确保你听说过新的 unavailable_after 元标签,该标签由Dan Crow数周前在 Google官方博客 中宣布。该标签可增加你的站点和谷歌的googlebot间的互动。试想,对 www.example.com ,有时你有一个临时性的新闻故事,限时公司促销,或一个宣传页,你可以对特定页面指定确切的日期和时间,来阻止被抓取和索引。
让我们假设你的一个促销活动有效期截至2007年年底。在 www.example.com/2007promotion.html 的源码开始,你可以使用以下行:
<META NAME="GOOGLEBOT"
CONTENT="unavailable_after: 31-Dec-2007 23:59:59 EST">
另一个令人振奋的消息是新的X-Robots-Tag指令。它增加了 机器人排除协议 (REP) META标签,该标签为非HTML网页提供支持!你终于可以控制对你的录像,电子表格,及其他索引文件类型的索引,就像控制对HTML页面的索引一样。还是上面的例子,比方说你的宣传页面是PDF格式。在文件 www.example.com/2007promotion.pdf 中,你可以增加以下行:
X-Robots-Tag: unavailable_after: 31 Dec
2007 23:59:59 EST
请记住,REP META标签可用于实现针对页面索引控制的noarchive,nosnippet,及现在的unavailable_after标签。这和robots.txt不同,robots.txt是对整个域名进行控制的。我们是应博客们和网站管理员的要求而增加这些特性的,请试用。如果你有其他的建议,也请随时提出。想问一些问题?请在我们的 网络管理员帮助组 里提问。
原文: New robots.txt feature and REP Meta Tags
发表于: 2007年8月15日,星期三,下午4时01分
我们已经改进了站长中心的分析工具,使之能理解网站地图(sitemap)的声明和相关的URL。较早的版本并不认识网站地图,且仅仅理解绝对的URL;其他的任何东西都被报错成“不理解你的语法”。现在改进后的版本会告诉你网站地图的URL和范围是否正确。您还可以对相关的URL测试并少了许多输入工作。
现在生成的报告也好多了。你可以在一行中知道多个问题的答案(如果有的话)。不像早期版本,一行仅第一个遇到的问题给出答案。同时,我们也在其他用以分析和验证的功能上取得了改进。
假设你负责域名 www.example.com ,你希望搜索引擎索引你网站的除/images文件夹之外的一切内容。您还想确保你的网站地图被搜索引擎知道,那么你可以使用以下内容作为你的robots.txt文件:
disallow images
user-agent: *
Disallow:
sitemap: https://www.example.com/sitemap.xml
你可以访问站长中心,使用robots.txt分析工具对你的网站进行测试,用这两个URL作测试:
https://www.example.com
/archives
站长工具的较早版本将会报错:
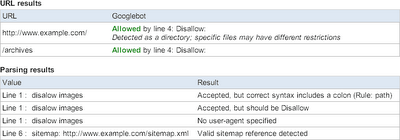
改进版会告诉你关于robots.txt文件的更多信息:
你可以在 https://www.google.com/webmasters/tools 看到以上信息。
我们还希望确保你听说过新的 unavailable_after 元标签,该标签由Dan Crow数周前在 Google官方博客 中宣布。该标签可增加你的站点和谷歌的googlebot间的互动。试想,对 www.example.com ,有时你有一个临时性的新闻故事,限时公司促销,或一个宣传页,你可以对特定页面指定确切的日期和时间,来阻止被抓取和索引。
让我们假设你的一个促销活动有效期截至2007年年底。在 www.example.com/2007promotion.html 的源码开始,你可以使用以下行:
<META NAME="GOOGLEBOT"
CONTENT="unavailable_after: 31-Dec-2007 23:59:59 EST">
另一个令人振奋的消息是新的X-Robots-Tag指令。它增加了 机器人排除协议 (REP) META标签,该标签为非HTML网页提供支持!你终于可以控制对你的录像,电子表格,及其他索引文件类型的索引,就像控制对HTML页面的索引一样。还是上面的例子,比方说你的宣传页面是PDF格式。在文件 www.example.com/2007promotion.pdf 中,你可以增加以下行:
X-Robots-Tag: unavailable_after: 31 Dec
2007 23:59:59 EST
请记住,REP META标签可用于实现针对页面索引控制的noarchive,nosnippet,及现在的unavailable_after标签。这和robots.txt不同,robots.txt是对整个域名进行控制的。我们是应博客们和网站管理员的要求而增加这些特性的,请试用。如果你有其他的建议,也请随时提出。想问一些问题?请在我们的 网络管理员帮助组 里提问。